











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
El modelo scorpan (McBratney et al., 2003; Lagacherie & McBratney, 2006; Minasny & McBratney, 2016) como base para la Cartografía Digital de Suelos (Digital Soil Mapping o DSM), considera que, a partir de la integración de distintos factores formadores del suelo en una función, se pueden predecir las clases de suelo (Sc) o los atributos (Sa). Estos factores comprenden el propio suelo (s), el clima (c), los organismos (o), el relieve o topografía (r), el material parental (p), la edad (a) y la posición espacial (n). Cada uno de estos factores se define a partir de distintas covariables ambientales. De esta forma, en cada ubicación donde se dispone de datos de perfiles de suelo, por un lado, se obtienen los valores de las propiedades edáficas y, por otro, se estima los valores de cada una de las covariables ambientales seleccionadas para el estudio. Todo ello permite la realización de una regresión lineal múltiple, con el objetivo de modelizar las relaciones entre la variable dependiente y las distintas covariables en los puntos de muestreo, y usar esas relaciones para estimar los valores en lugares sin muestrear (Hengl et al., 2007). En España, la aplicación de este tipo de metodologías que se incluyen en el DSM es todavía muy limitada y se ha aplicado principalmente para estimar la distribución del carbono orgánico del suelo, y menos frecuente, en otras propiedades del suelo como la textura. En el presente estudio, se propone estimar (Sa) los porcentajes de materia orgánica del suelo. En cuanto a los factores formadores del suelo se han seleccionado el clima (c), la vegetación (o), la topografía (r) y el material parental (p).
Área de estudio
El área de estudio se corresponde con una extensión aproximada de 530 km2 en el área de Benavides de Órbigo, en el noroeste de la Península Ibérica (Figura 1), caracterizada por un clima continental templado. Se distinguen relieves paleozoicos situados al oeste y norte constituidos por pizarras, areniscas y cuarcitas. Se encuentran principalmente en estas formaciones de la zona de relieves en pendiente asociaciones de Regosoles lépticos/Umbrisoles háplicos y Leptosoles úmbricos con inclusiones de Leptosoles líticos (Alonso Herrero et al., 2010). El resto de la zona está formada por materiales silíceos asociados a conglomerados, arenas, limos y arcillas del Mioceno y del Cuaternario. Las asociaciones de Umbrisoles húmicos/Regosoles dístricos junto con Cambisoles crómicos se encuentran en las zonas de laderas y vertientes. En la zona centro y noreste, en las terrazas medias y altas, dominan los Acrisoles úmbricos y abrúpticos con inclusiones de Acrisoles profóndicos y gléicos. Destacan asociaciones de Cambisoles eútricos y dístricos en zonas de terrazas bajas, junto con Fluvisoles y Regosoles dístricos, cerca de los cursos fluviales (Alonso Herrero et al., 2010).

MATERIAL Y MÉTODOS
Las fuentes de datos y los materiales utilizados para estimar las covariables de clima, vegetación, topografía y material parental siguiendo el método propuesto, se explican a continuación.
- 45 muestreos de los primeros 25-30 cm de suelo pertenecientes a la Base de Datos de los Suelos de Castilla y León (ITACyL - 2012) con datos de % materia orgánica, arcilla, limo y arena.
- 30 perfiles realizados para el Plan Piloto del Mapa de suelos de la Provincia de León (Alonso Herrero et al., 2010), de los que se ha seleccionado solo los datos del horizonte A: el valor único para dichos horizontes se estimó como media ponderada en función de la profundidad de cada subhorizonte A.
- Modelo de Elevación Digital (MED) del Centro Nacional de Información Geográfica (CNIG, 2014), con una resolución espacial de 25m x 25m para la estimación de todas las variables topográficas: altitud (m), pendiente (grados), orientación (radianes) e índice topográfico de humedad (TWI).
- Los datos climáticos se estimaron a partir de los mapas ráster (500x500m) derivados del modelo de simulación SIMPA (MITECO - 2019), obteniendo la precipitación media anual (mm), la temperatura media anual (ºC) y la evapotranspiración potencial media anual (mm) del período hidrológico 1940/1-2017/8; excepto la radiación solar anual derivada a partir del MED.
- 35 imágenes del satélite Sentinel2 de junio-septiembre 2017 y octubre-mayo de 2018 de la Agencia Espacial Europea (ESA - 2018) con las que se estimó el valor del Índice de Vegetación Normalizado (NDVI) mínimo, máximo y promedio para el período seco (junio, julio, agosto y septiembre) y el período húmedo (resto meses), después de analizar la evolución pluviométrica en el periodo simulado por el modelo SIMPA.
- Cartografía de usos de suelo del Sistema de Información de Ocupación del Suelo de España (SIOSE) del año 2014 (escala 1:25k) que se reclasificó en cuatro clases: suelo desnudo, agrícola-prado-pastizal, matorral y bosque. Al ser esta covariable de tipo categórico, se transformó cada clase a una variable numérica ordinal.
- Cartografía geológica continua del proyecto GEODE escala 1:50k del IGME (2008) para la extracción de la litología, que también se reclasificó para simplificar el número de clases litológicas en función del grado de consolidación, tamaño de grano y naturaleza litológica y se transformó a variable numérica ordinal.
Mediante operaciones de SIG se extrajo el valor de cada una de estas covariables para los 75 puntos con datos de % materia orgánica y se realizó un análisis estadístico para derivar el modelo correspondiente a DSM. Previamente, se dividió de manera aleatoria el número de puntos en dos grupos: 55 se utilizaron para calibrar el modelo y 20 para validarlo. En primer lugar, se realizó un análisis de las correlaciones entre las distintas covariables de NDVI, para eliminar aquellas que mostrasen una dependencia lineal elevada (coeficiente de Pearson superior a 0,65, p<0,01). Con todas covariables resultantes (tanto de NDVI como del resto de factores) se estimaron diversas regresiones lineales múltiples (MLR) siguiendo el método de “eliminación hacia atrás”. De todos los modelos resultantes, se seleccionaron dos que presentasen un valor de R2 adecuado teniendo en cuenta su valor de significancia y el número de covariables menor posible. Tras esta selección, se estimaron modelos lineales generalizados (GLM) utilizando las covariables que representaban cada uno de los modelos seleccionados, obteniéndose un valor del Criterio de Información de Akaike (AIC), el cual permite evaluar la idoneidad de un modelo estadístico concreto en comparación con otros modelos. Posteriormente, se seleccionó aquel modelo que menor valor de AIC presentaba o, en caso de que presentasen índices similares, se seleccionó el que menos covariables contenía. Se validaron los resultados comparando en los 20 puntos seleccionados para validación el valor predicho (estimado) con el valor real (medido), mediante la estimación del error cuadrático medio. Finalmente, la interpolación espacial de los residuos se realizó siguiendo el método del inverso de la distancia (IDW) y se aplicó la ecuación del modelo.
RESULTADOS Y DISCUSIÓN
Tras la realización de la MLR, se seleccionaron los modelos d y g, con valores de R2 de 0,552 y 0,543, respectivamente y, tras el análisis GLM se seleccionó el modelo g, al tener ambos modelos el mismo AIC y ser este el que menos covariables considera (Tabla 1).
Tabla 1 Resultados de la MLR y del GLM
| Modelo | R2 | AIC | Sig. |
|---|---|---|---|
| d | 0,552 | 260,586 | 0,000 |
| g | 0,543 | 260,586 | 0,000 |
A su vez, analizando el RMSE, el valor es similar para los muestreos de calibración como para los de validación, así como para el conjunto total de los datos (Tabla 2).
Tabla 2 RMSE obtenido para los muestreos de calibración, los de validación y totales
| Error (RMSE) | ||
|---|---|---|
| 55 muestreos | 20 muestreos | 75 muestreos |
| 2,130 | 2,186 | 2,145 |
Estos resultados son mejores que los obtenidos por otros autores, que presentaban un R2 menor y RMSE mayor. Comparando los valores medidos con los estimados para ambos conjuntos de datos, se observa que no existe una gran diferencia entre ambos (Figura 2).

En cuanto al análisis geoestadístico, los residuos de la materia orgánica muestran una ligera sobreestimación en el centro y noreste del área de estudio, mientras que se subestiman, principalmente, al sur y oeste (Figura 3).

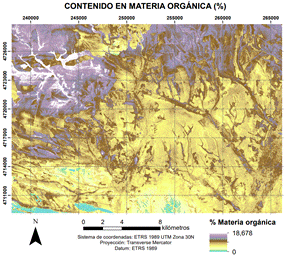
Como resultado final, los mayores porcentajes de materia orgánica se encuentran al norte de la zona siendo más elevados al noroeste (Figura 4).
CONCLUSIONES
1) Los resultados obtenidos son mejorables, pues se han hallado valores de R2 bastante bajos. Se debe revisar el origen de los muestreos con el fin de ver la afección a los resultados. 2) No hay grandes diferencias entre el grupo de calibración y validación, por lo que se corrobora la utilidad de la segmentación del conjunto de datos. 3) El muestreo de la cartografía convencional edáfica sigue siendo necesario, pues es un elemento clave para reducir los errores. 4) El método del DSM presenta aún grandes limitaciones a pesar de su gran aplicabilidad.

