










Serviços Personalizados
Journal

Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
 Citado por SciELO
Citado por SciELO Links relacionados
 Similares em
SciELO
Similares em
SciELO Compartilhar

 Permalink
PermalinkRISTI - Revista Ibérica de Sistemas e Tecnologias de Informação
versão impressa ISSN 1646-9895
RISTI no.39 Porto out. 2020
https://doi.org/10.17013/risti.39.18-34
ARTÍCULOS
Conversión de eventos desde esquemas preconceptuales en código PL/pgSQL: simulación de software en la cuarta revolución industrial
Event conversion from pre-conceptual schemas to PostgreSQL code: software simulation in the fourth industrial revolution
Carlos Mario Zapata-Jaramillo 1, Juan Sebastián Zapata-Tamayo 1, Paola Andrea Noreña Cardona 1
1 Universidad Nacional de Colombia, Carrera 80 No. 65-223 Of. M8A-310, 050036, Medellín, Colombia. cmzapata@unal.edu.co, jzapatat@unal.edu.co, panorenac@unal.edu.co
RESUMEN
La simulación es una de las áeas clave de la Industria 4.0. En la industria de software, la simulación se aplica en la predicción del comportamiento de las aplicaciones a partir del modelado. Una forma de simulación se relaciona con la obtención de código fuente a partir de los modelos, que en el caso de los eventos se suele realizar desde diferentes esquemas conceptuales hacia lenguajes basados en disparadores y viceversa, sin incluir el PL/pgSQL. Por ello, en este artículo se propone un conjunto de reglas heurísticas para obtener código PL/pgSQL a partir de esquemas preconceptuales, como una forma de simular el comportamiento de las aplicaciones que incluyen eventos. Estas reglas se validan mediante un estudio de laboratorio correspondiente a la expansión de una epidemia. Mediante la ejecución de las reglas en el estudio de laboratorio se puede simular el comportamiento futuro de la aplicación y los resultados asociados.
Palabras-clave: Simulación; Industria 4.0; Eventos; Esquemas preconceptuales; PL/pgSQL.
ABSTRACT
Simulation is one of the key areas of Industry 4.0. Simulation in the software industry is applied to the prediction of the application behavior from modeling. One kind of simulation is related to obtaining source code from models; in the case of events, such simulation can be achieved from some conceptual schemas to trigger-based languages and vice versa, but excluding PL/pgSQL. For this reason, in this paper, we propose a set of heuristic rules for obtaining PL/pgSQL code from pre-conceptual schemas, as a way to simulate the behavior of applications that include events. Such rules are validated by using a lab study related to the expansion of an epidemic. We can simulate the future behavior of the application and the associated results by executing the rules in the lab study.
Keywords: Simulation; Industry 4.0; Events; Pre-conceptual schemas; PostgreSQL.
1. Introducción
Baygin, Yetis, Karakose, & Akin (2016) presentan nueve áreas clave de la Industria 4.0. La simulación, objeto de este artículo, es una de ellas y se entiende como la reproducción virtual de los procesos que ocurren en las industrias. En la industria de software, y más concretamente en la ingeniería de software, la simulación puede contribuir en la evaluación del impacto de las aplicaciones y también en procesos de rediseño (Tanir, 2017) a partir del modelado.
La generación de código a partir de modelos es una forma de simulación que puede ser manual o automática (Boulanger, 2018) y siempre requiere la implementación de un cierto número de reglas para asegurar que los requisitos definidos en el diseño se consideren. Algunos modelos se traducen en lenguajes como el Structured Query Language SQL (Awiti, Vaisman, & Simányi, 2020; Teorey, Lightstone, Nadeau, & Jagadish, 2005; Chaverra, 2011; Chochlik, Kostolny, & Martincova, 2015). En otras propuestas se hace ingeniería inversa a porciones de código en lenguajes basados en disparadores, como el Programming Language Structured Query Language PL/SQL (Methakullawat & Limpiyakorn, 2014; Habringer, Moser, & Pichler, 2014; Fernández et al., 2019), para generar modelos. Los eventos, entendidos como fenómenos que ocurren en los procesos de negocios y que permiten iniciar operaciones, se suelen modelar en diferentes esquemas conceptuales como redes de Petri (Narciso & Piera, 2017), Business Process Modeling and Notation BPMN (Object Management Group, 2011) y esquemas preconceptuales (Zapata-Jaramillo, 2011), a partir de los cuales se pueden convertir en diferentes lenguajes de programación, como PL/SQL (El-Hayat, Toufik, & Bahaj, 2020; Zapata-Tamayo, 2019). Sin embargo, en ninguna de estas propuestas se toma en consideración el PL/pgSQL, que es un lenguaje de programación basado en disparadores del gestor de bases de datos PostgreSQL.
Por ello, en este artículo se propone un conjunto de reglas heurísticas que posibilita la generación automática de código en PL/pgSQL a partir de esquemas preconceptuales en los que se modelan eventos, de manera que se pueda estudiar el comportamiento de este tipo de aplicaciones en los procesos de simulación que se realizan en la industria de software, en el contexto de la Industria 4.0. Como forma de validación se selecciona un estudio de laboratorio proveniente de la literatura especializada (Noreña, 2018) correspondiente al comportamiento de una epidemia en expansión.
Este artículo se organiza de la siguiente manera: en la Sección 2 se presenta el marco conceptual de la propuesta; en la Sección 3 se presentan los antecedentes; en la Sección 4 se propone la solución y su consecuente validación con un caso de laboratorio; las conclusiones y el trabajo futuro se discuten en la Sección 5.
2. Marco conceptual
2.1. Simulación en la Industria 4.0
Baygin et al. (2016) establecen como uno de los fines de la Industria 4.0 la posibilidad de unir las tecnologías de información con la industria, de modo que se puedan crear fábricas inteligentes. Esa visión se materializa con nueve áreas tecnológicas diferentes: Big Data y Analítica, Robots Autónomos, Simulación, Integración Horizontal y Vertical de Sistemas, Internet de las Cosas, Ciberseguridad, Cloud, Manufactura Aditiva y Realidad Aumentada. Tanir (2017) define la simulación como una técnica de propósito general de gran valor para evaluar espacios de solución de múltiples facetas de manera temprana durante las fases de planeación y diseño sin tener necesidad de un despliegue físico de las posibles alternativas de diseño. Por ello, Tanir (2017) establece que la simulación permite evaluar los impactos que se generen en los procesos de negocios y en las tecnologías de la información, tomando en consideración que se pueden requerir procesos de rediseño. Para Gunal (2019) la simulación puede desempeñar un rol primordial en la realización de la Industria 4.0.
2.2. Representación de eventos en esquemas conceptuales
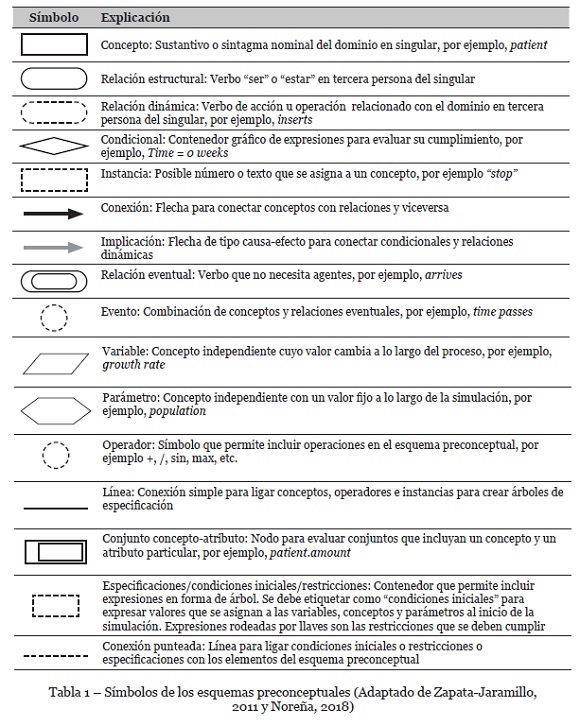
Luckham (2011) define un evento como algo que ocurre en un sistema o dominio en particular y que sirve para dirigir automáticamente los procesos de negocio. Los eventos se representan en diferentes esquemas conceptuales. Narciso y Piera (2017) emplean transiciones entre los diferentes estados en una red de Petri. En BPMN (Object Management Group, 2011), se representan los estados con círculos que encierran diferentes elementos dependiendo de la naturaleza del evento (sobres de carta para eventos de mensaje, relojes para eventos de tiempo, triángulos para eventos tipo señal, etc.). Para efectos de este artículo, se usa la notación de eventos que se define en esquemas preconceptuales (Zapata-Jaramillo, 2011; Noreña (2018), ya que existe ya un conjunto de reglas heurísticas que, a partir de estos esquemas, permiten la traducción a código PL/SQL (Zapata-Tamayo, 2019). Los principales símbolos de los esquemas preconceptuales (incluyendo la notación correspondiente a eventos) se muestran en la Tabla 1.
2.3. PL/pgSQL
Worsley y Drake (2001) definen PostgreSQL como un sistema de gestión de bases de datos objeto relacional de código abierto que incluye los comandos típicos del SQL junto con varias características adicionales, como búsquedas complejas, disparadores (triggers) y control de concurrencia multiversión. Además, el usuario puede extender PostgreSQL con lenguaje PL/pgSQL, que es el lenguaje de programación de este sistema de gestión de base de datos. Por ser el tema de este artículo, se muestra seguidamente la estructura de las funciones:
CREATE FUNCTION function_identifier () RETURNS opaque AS '
DECLARE
declarations;
[...]
BEGIN
statements;
[...]
END;
' LANGUAGE 'plpgsql';
Los triggers se usan para invocar las funciones en el caso de que se requiera su ejecución de manera automática ante un evento. La sintaxis, en ese caso, es la siguiente:
CREATE TRIGGER function_identifier
[AFTER/BEFORE] [CREATE/UPDATE/DELETE] OF field ON table
FOR EACH ROW
EXECUTE PROCEDURE function_identifier ();
3. Antecedentes
Para Boulanger (2018), una élite de expertos realiza la programación de una aplicación de software, aunque ese proceso se puede automatizar con la asistencia manual de un conjunto de reglas heurísticas o incorporando esas reglas en una herramienta con fines de automatización. Dado que el tema central de este artículo es la generación de código PL/pgSQL desde modelos que incluyan eventos, una revisión sistemática de literatura arroja que no existen propuestas asociadas con ese tópico en particular, pero hay similitudes que son de utilidad para el proceso.
3.1. Desde modelos hacia SQL
Awiti et al. (2020) parten de BPMN para obtener expresiones SQL. Teorey et al. (2005) y Chochlik et al. (2015) parten del diagrama entidad-relación para generar SQL. De manera similar, Chaverra (2011) emplea el esquema preconceptual para generar el diagrama entidad-relación correspondiente y, simultáneamente, la estructura de las tablas en SQL. El diagrama entidad-relación es un esquema conceptual que se usa para representar la estructura del dominio, por lo cual los eventos no se pueden representar en él. En los esquemas preconceptuales se pueden representar los eventos, pero esta porción del esquema no es la que emplea Chaverra (2011) para su proceso de generación de código. Además, si bien SQL es el punto de partida para PL/pgSQL, el SQL tampoco posee sintaxis que permita representar los eventos. Se resalta de estas propuestas la adición de reglas heurísticas para transformar esquemas preconceptuales en sentencias SQL.
3.2. Desde PL/SQL hacia esquemas conceptuales y viceversa
La ingeniería inversa se usa para recuperar esquemas conceptuales cuando existe alguna porción de código legado. Methakullawat y Limpiyakorn (2014) utilizan código legado PL/SQL para generar el diagrama de clases de UML (Unified Modeling Language). Las sentencias que incluyen procedimientos sólo las utilizan para generar la parte estructural del diagrama de clases. De forma similar, Habringer et al. (2014) usan procedimientos almacenados en PL/SQL para generar el diagrama de flujo de datos, que en cierta forma es también estructural. Ni en el diagrama de clases de UML ni en el diagrama de flujo de datos se toman en cuenta los eventos, aunque el lenguaje PL/SQL sí los soporta. Fernández et al. (2019) usan triggers de PL/SQL para obtener código Java usando diagramas de clases.
El-Hayat et al. (2020) parten de un diagrama de clases enriquecido con OCL para definir triggers en PL/SQL. Zapata-Tamayo (2019) parte de esquemas preconceptuales que incluyen eventos y, con base en un conjunto de reglas heurísticas, genera sentencias PL/SQL con la sintaxis completa, de forma tal que se puede ejecutar en un gestor de Oracle". Sin embargo, Oracle" no es un gestor de código abierto y requiere licenciamiento para su uso. En esta propuesta, sin embargo, no se considera la traducción de las reglas a código PL/pgSQL, que sí es de código abierto. Al igual que el PL/SQL, su homólogo de código abierto PL/pgSQL también tiene una sintaxis apropiada para soportar eventos.
4. Solución y validación
Gunal (2019) define para la simulación en Industria 4.0 un “gemelo digital”, que es un software para controlar elementos físicos de una plataforma colaborativa de procesos industriales de negocios y para recolectar datos de esa plataforma que permitan predecir y mejorar su funcionamiento. En las empresas de software no se desarrolla un producto tangible y, por ello, el gemelo digital de Gunal (2019) adquiere su sentido cuando se emplean modelos para simular las aplicaciones definitivas y su comportamiento, como es el caso de la epidemia de influenza que se estudia en este artículo. Por esta razón, el tipo de simulación que se propone con la conversión de un modelo basado en eventos (en este caso el esquema preconceptual) en triggers ejecutables en PL/pgSQL posibilitan la adquisición de datos desde etapas preliminares del diseño, actuando como gemelo digital de una aplicación definitiva que permita estudiar un fenómeno desde el punto de vista del modelado.
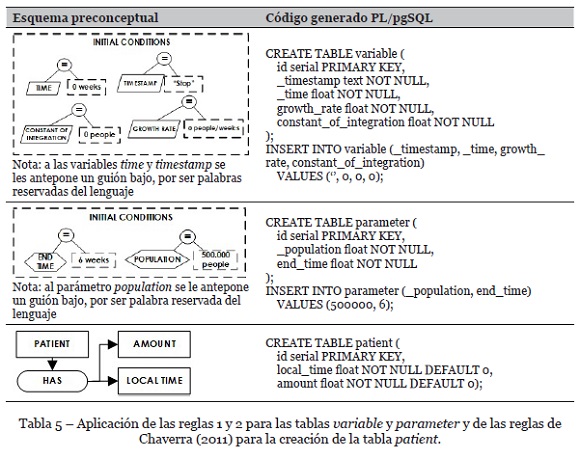
Zapata-Tamayo (2019) usa las reglas heurísticas de Chaverra (2011) para generar las sentencias SQL correspondientes a la creación de tablas, especialmente aquellas en las cuales se van a almacenar los datos. Además de esas reglas, en este artículo se aprovechan las reglas 1 y 2 de Zapata-Tamayo (2019), en las cuales se generan las tablas correspondientes a las variables (regla 1) y parámetros (regla 2), pues su funcionamiento es idéntico en su traducción a lo que allí se presenta para el lenguaje SQL. Finalmente, se considera el caso de los nombres de variables y parámetros que coinciden con palabras reservadas del lenguaje, adicionando un guión bajo (_) antes del nombre. Adicionalmente, se consideran algunas variaciones a las reglas de Zapata-Tamayo (2019):
• Sintaxis del PL/pgSQL. La sintaxis específica del PL/pgSQL tiene algunas diferencias con el PL/SQL. La diferencia fundamental radica en el hecho de que los triggers se deben programar como funciones y el código de creación del trigger sólo se utiliza para llamar la función correspondiente. En la regla 3 de Zapata-Tamayo (2019) hay que adicionar algunas líneas de la sintaxis específica, como se muestra en la Tabla 2.

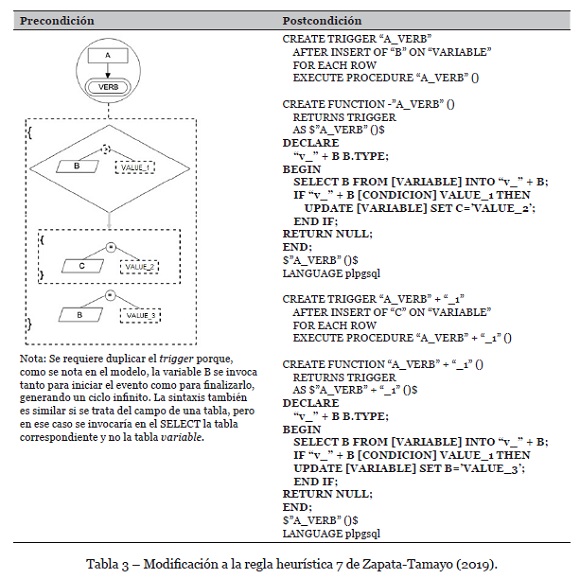
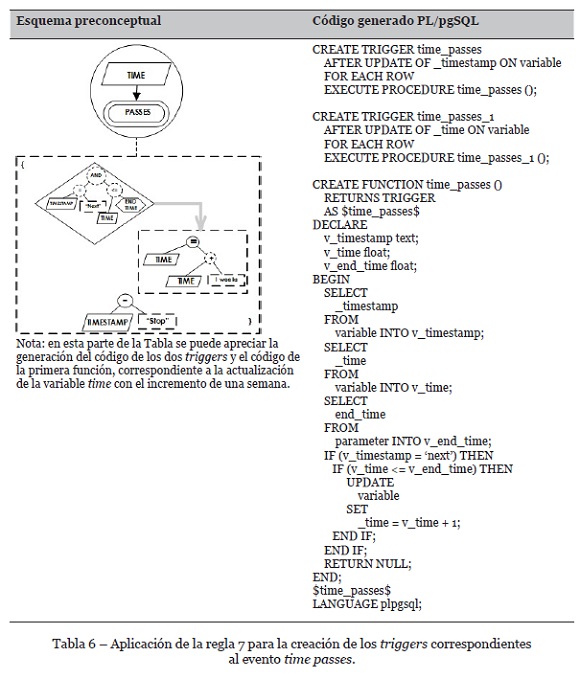
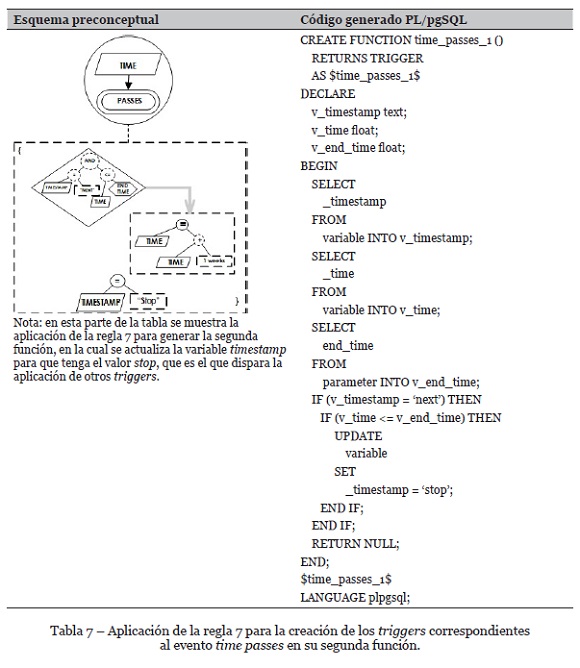
• Efecto de dividir un evento en el modelo en dos triggers en lenguaje de programación para evitar los problemas de las tablas mutantes. Se deben incluir todos los elementos de la condición inicial del evento del modelo en cada uno de los triggers en lenguaje de programación, dado que es posible que se presenten problemas de simultaneidad que hagan disparar otro trigger con la misma condición final. Ésta es una variación de la Regla 7 de Zapata-Tamayo (2019), tal como se muestra en la Tabla 3.
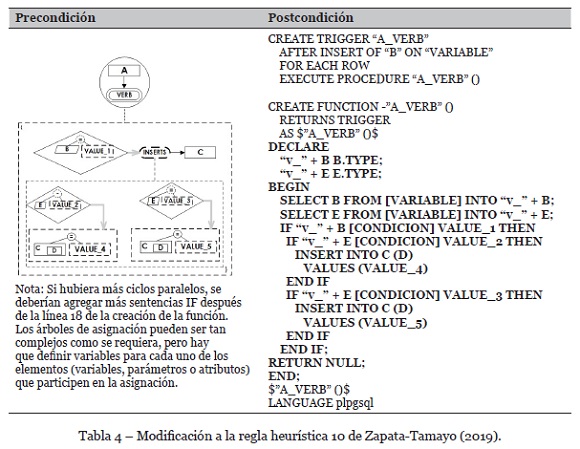
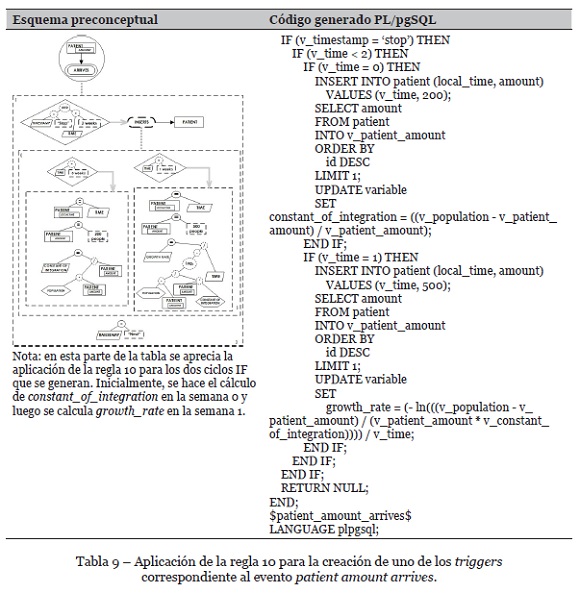
• Presencia de dos o más condicionales en paralelo en una especificación de evento. Hay que adicionar un bloque de código por cada condicional en paralelo que se tenga, tomando la precaución de incluir en el bloque DECLARE todas las variables y parámetros que se requieran en la evaluación de los condicionales. Ésta es una variación a la regla 10 de Zapata-Tamayo (2019), como se ilustra en la Tabla 4.
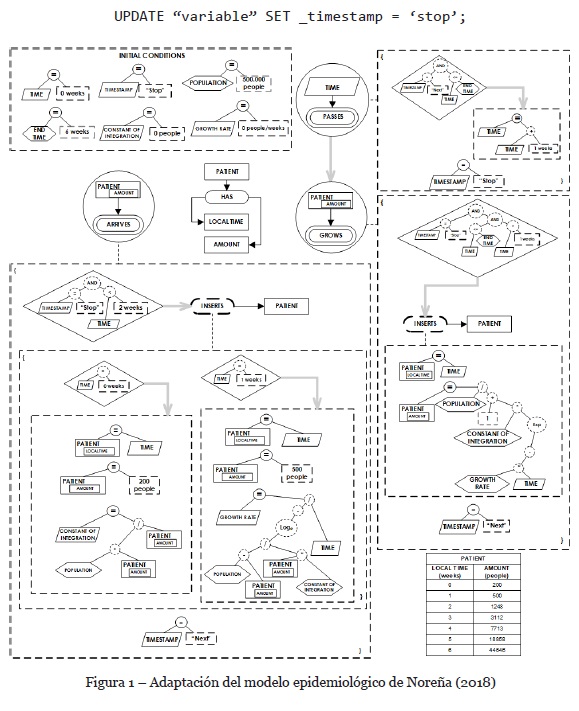
Con el fin de validar el efecto de las modificaciones a las reglas, se selecciona un caso de laboratorio de la literatura especializada. Noreña (2018) presenta un esquema preconceptual correspondiente al modelo epidémico de una ciudad infectada con influenza. Ese esquema preconceptual incluye los diferentes eventos que controlan el incremento en la cantidad de pacientes que sufren la enfermedad. Como el esquema se encuentra originalmente en el idioma inglés, la aplicación de las reglas se realiza respetando este lenguaje. En el esquema se hacen algunas modificaciones en relación con el original:
• La constante de integración, que en el modelo de Noreña (2018) se consideraba un parámetro, se considera ahora una variable, pues depende del número de pacientes infectados en la semana cero. El valor inicial de esta variable es cero.
• La tasa de crecimiento, que también se consideraba un parámetro, también se considera ahora una variable, pues depende del número de pacientes infectados en la semana 1 y de la constante de integración. El valor inicial de esta variable es cero.
• Se excluyen de las condiciones iniciales los vectores de tiempo y número de pacientes que se consideran registros iniciales en la tabla paciente, necesarios para el cálculo de la constante de integración y la tasa de crecimiento. En su lugar, se modela un evento denominado patient amount arrives (número de pacientes llega), que sirve para actualizar la tabla de pacientes con los valores correspondientes a los infectados en las semanas 0 y 1, valores que se requieren para el cálculo de las variables constante de integración y tasa de crecimiento y su actualización con los valores definitivos en dicha tabla.
• Se incluyen en las condiciones iniciales el parámetro end time para ponerle fin a la simulación en un tiempo de 6 semanas y la variable timestamp, que puede tomar los valores next y stop, con el fin de controlar la ejecución de los eventos en la simulación. Nótese que al final de cada uno de los eventos hay una asignación diferente del valor de timestamp.
• Se reemplazan los vectores tiempo y paciente por los atributos local time y amount, correspondientes a la tabla patient.
El modelo completo, modificado según las consideraciones anotadas, se presenta en la Figura 1. Las flechas de conexión posibilitan la lectura entre los conceptos y las relaciones (por ejemplo “paciente tiene hora local y cantidad”). Las flechas de implicación generan relación causa-efecto (por ejemplo, “cuando el tiempo pasa, la cantidad de pacientes crece”). Las conexiones punteadas permiten detallar los eventos y los operadores permiten complementar las fórmulas (por ejemplo, la parte inicial de “llega cantidad de pacientes” se lee “si la marca de tiempo es igual a pare y el tiempo es menor a dos semanas, se inserta un paciente”). Con base en el modelo de la Figura 1, se inicia la aplicación de las reglas 1 y 2, correspondientes a la creación de las tablas variable y parameter, como se muestra en la Tabla 5. Además, aplicando las reglas de Chaverra (2011) se crea la tabla patient, que sirve para almacenar los datos correspondientes a la cantidad de personas infectadas en la población en cada semana.
El evento time passes requiere la variable timestamp tanto en el condicional como en el final del evento, por lo cual requiere la aplicación de la regla 7, generando dos triggers diferentes tal como se muestra en las Tablas 6 y 7. Además, con la aplicación de la regla 3 se crea el código tanto de cada uno de los triggers como de las funciones correspondientes. Ahora, en el caso del evento patient amount arrives se debe aplicar la regla 10 para generar las sentencias IF paralelas que se dan en el cuerpo del trigger, como se muestra en las Tablas 8 y 9. Dado que el evento termina con la actualización de la variable timestamp, que también se necesita en el condicional, se aplica también la regla 7 para generar un segundo trigger, pero, por efectos de espacio, ese segundo trigger no se incluye en este artículo, al igual que los que corresponden al evento patient amount grows, pero su código es similar al que se muestra en los otros eventos.

Una vez se genera la totalidad del código PL/pgSQL mediante la utilización de las reglas, es necesario cambiar los valores en el PostgreSQL para que se inicie la ejecución de los diferentes triggers.Como se aprecia en la Tabla 5, antes de iniciar la simulación el valor de timestamp está vacío, por lo cual se debe colocar en el valor stop, que es la primera condición para ejecutar el proceso. Eso se logra con el siguiente comando en PostgreSQL:
Cuando se inicia ese proceso y con los valores que ya se tienen en las tablas variable, parameter y patient se generan los siete valores que se muestran en la Figura 1 para la tabla patient en local_time 0 a 6.
Ahora, si se hace un UPDATE suficientemente grande del parámetro end_time, es posible determinar cuándo la epidemia alcanzará toda la población en la ciudad. Para este caso en particular, se encuentra que en la semana 23 se alcanza un amount en patient de 499999.1327998074, un número suficientemente cercano al de la población total de la ciudad, que es de 500000. Si se quiere ser suficientemente preciso, en la semana 49 se llega a ese número exactamente.
5. Conclusiones y trabajo futuro
En este artículo se propuso un conjunto de reglas heurísticas que posibilitan la generación de código PL/pgSQL a partir de modelos que incluyen eventos representados en esquemas preconceptuales.
Estas reglas constituyen un ejemplo de la manera en que la industria del software emplea el área clave de simulación correspondiente a la Industria 4.0 para predecir el comportamiento de sistemas complejos, lo cual se pudo comprobar mediante un caso de laboratorio correspondiente a la literatura especializada y en el cual se ejemplifica la expansión de una epidemia de influenza en una ciudad. Con el código generado fue posible la generación automática de los valores que se predijeron para el modelo. El código se generó completamente a partir de las reglas y fue completamente funcional en el gestor de bases de datos PostgreSQL, de código abierto.
Como líneas de trabajo futuro, se proponen las siguientes:
• Elaboración de una herramienta que incluya las reglas que se definen en este artículo y las que define Zapata-Tamayo (2019) para la generación automática de código fuente, tanto en PL/SQL como en PL/pgSQL a partir de las representaciones en esquemas preconceptuales.
• Estudio de otros fenómenos relacionados con eventos complejos para determinar reglas heurísticas adicionales en situaciones que así lo requieran para el funcionamiento autónomo de los eventos en este tipo de simulación.
• Exploración de otras maneras en que la simulación basada en eventos pueda contribuir en la Industria 4.0.
REFERENCIAS
Awiti, J., Vaisman, A., & Simányi, E. (2020). Design and implementation of ETL processes using BPMN and relational algebra. Data and knowledge engineering, 129,1-14. 10.1016/j.datak.2020.101837 [ Links ]
Baygin, M., Yetis, H., Karakose, M., & Akin. E. (2016). An Effect Analysis of Industry 4.0 to Higher Education. In 15th International Conference on Information Technology Based Higher Education and Training (ITHET). [ Links ] Istanbul.
Boulanger, J. (2018). Certifiable software applications 3: Downward cycle. Elsevier Ltd. [ Links ]
Chaverra, J. J. (2011). Generación Automática de Prototipos Funcionales a Partir de Esquemas Preconceptuales. (Tesis de Maestría). Departamento de Ciencias de la Computación y de la Decisión, Universidad Nacional de Colombia, Medellín.
Chochlik, M., Kostolny, J., & Martincova, P. (2015). Metamodel describing a relational database schema. Central European Researchers Journal, 1(1), 94-102. [ Links ]
El-Hayat, S., Toufik, F., & Bahaj, M. (2020). UML/OCL based design and the transition towards temporal object relational database with bitemporal data. Journal of King Saud University-Computer and information sciences, 32, 398-407. [ Links ]
Fernández, C., Molina, J., Bermúdez, F., Hoyos, J., Sevilla, D., & Cuesta, B. (2019). Developing a model-driven reengineering approach for migrating PL/SQL triggers to Java: a practical experience. The journal of systems and software, 151, 38-64. [ Links ]
Gunal, M. (2019). Simulation and the Fourth Industrial Revolution. In Simulation for Industry 4.0: past, present, and future (pp. 1-17). Springer. [ Links ]
Habringer, M., Moser, M., & Pichler, J. (2014). Reverse Engineering PL/SQL Legacy Code: An Experience Report. In IEEE International Conference on Software Maintenance and Evolution. [ Links ] Victoria, Canada.
Luckham, D. (2011). Event Processing for Business: Organizing the Real-time Enterprise. John Wiley & Sons. [ Links ]
Methakullawat, N., & Limpiyakorn, Y. (2014). Reengineering Legacy Code with Model Transformation. International Journal of Software Engineering and Its Applications, 8(3), 97-110. [ Links ]
Narciso, M., & Piera, M. A. (2017). Modeling Discrete Event Systems Using Petri Nets, in Robust Modelling and Simulation (pp. 49-85). Springer. [ Links ]
Noreña, P. (2018). An Extension to Pre-conceptual Schemas for Refining Event Representation and Mathematical Notation. In 21st Conferencia Iberoamericana en Software Engineering (CIbSE) (pp. 589-596). Bogotá, Colombia. [ Links ]
Object Management Group (2011). About the business process modelling and notation specification version 2.0 [Internet]. http://www.omg.org/spec/BPMN/2.0 [ Links ]
Tanir O. (2017). Simulation-Based Software Engineering. In Guide to Simulation-Based Disciplines. Simulation Foundations, Methods and Applications. Springer. [ Links ]
Teorey, T., Lightstone, S., Nadeau, T., & Jagadish, H. V. (2005). Database Modeling and Design (4th Edition). Morgan Kaufmann. [ Links ]
Worsley, J. & Drake, J. (2001). Practical PostgreSQL. O’Reilly. [ Links ]
Zapata-Jaramillo, C. M. (2011). The UNC-Method revisited: elements of the new approach. Lambert Academic Publishing. [ Links ]
Zapata-Tamayo, J. S. (2019). Generación Semiautomática de Código PL/SQL a partir de Representaciones de Eventos Basadas en Esquemas Preconceptuales. (Tesis de Maestría). Departamento de Ciencias de la Computación y de la Decisión, Universidad Nacional de Colombia, Medellín.
Agradecimiento
Este artículo es parte del proyecto de Maestría titulado “Generación Semi-automática de Código PL/SQL a partir de Representaciones de Eventos Basadas en Esquemas Preconceptuales”, patrocinado por la Facultad de Minas de la Universidad Nacional de Colombia, sede Medellín.
Recebido/Submission: 29/07/2020. Aceitação/Acceptance: 17/09/2020

