











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introducción
Un incidente se define como un evento en el que el servicio de TI se interrumpe inesperadamente (Yandri et al., 2019). A nivel internacional, según (Kaspersky, 2022) la mayor respuesta a incidentes de clientes en Europa corresponde al 30,1%, Comunidad de Naciones de la CEI 24.7%, Oriente Medio 23,7%, y América Latina 15,5%. Según (Caldarulo et al., 2022; Inter American Development Bank (BID) & Organization of American States (OEA), 2020; Urueña López et al., 2019), el número de solicitudes de incidentes relacionados con la seguridad informática ha ido en aumento desde 2019 con 2.217, 2020 con 2.798 y 2021 con 3.948, que se clasifican entre "Alta" y "Muy alta" según su gravedad. Al respecto, (Sadri et al., 2022) menciona que los incidentes por ciberataques representan más del 1% del Producto Interno Bruto (PIB) del Perú. Sin embargo, en las empresas latinoamericanas, (Iparraguirre-Villanueva, Guevara-Ponce, Sierra-Liñan, et al., 2022) menciona que el 13% de los gestores de incidentes no tienen la capacidad para hacer frente al aumento de las amenazas y necesitan implementar nuevas técnicas. En el último año, el 60% de las empresas han tenido incidentes de seguridad. Por ejemplo, en Perú, las detecciones de Ransomware lo ubican en el primer lugar con un 20% en comparación con otros países de Latinoamérica. Sin embargo, la inversión en el área de TI por parte de la alta dirección en las organizaciones es mínima, se entiende a partir de (Ray et al., 2023) que a los ojos de la alta dirección, las actividades de TI sólo son útiles en el momento de eventos (podemos entender eventos como fallas, incidentes u otros) que son de mayor preocupación para los administradores de TI; Ante esto, la asignación de tareas para la Gestión de Incidentes (GI) es una actividad importante, ya que su ligereza implicaría que no se asigne el especialista necesario, posponiendo su resolución (Gómez-Jaramillo et al., 2022), por lo que se deben asignar rápidamente para evitar reclamos, que la resolución no tome más tiempo y mejorar la satisfacción de los usuarios con el servicio (Rodriguez & Mune, 2022),(Sever Iscen & Zahid Giirbiiz, 2019). Estos agentes automáticos, con el tiempo, pueden mejorar su capacidad de resolución de problemas mediante el aprendizaje automático, utilizando la retroalimentación de los usuarios y la información recopilada (Araujo-Ahon et al., 2023; Huallpa et al., 2023).
Es importante tener en cuenta que, durante la GI, se deben utilizar tecnologías emergentes, por lo que es necesario conocer las diferentes metodologías y marcos utilizados para cubrir las necesidades en las fases del proceso de GI, a través de la evolución tecnológica se encuentran las soluciones más adecuadas basadas en el conocimiento generado a causa de la investigación. Para ello, se han investigado diferentes casos relacionados con el tema de la investigación en GI. Por ejemplo: en (Kostadinov et al., 2020), analizaron métodos de clasificación de texto para la asignación automática de elementos de configuración a incidentes; también, en (Jittawiriyanukoon, 2019) utilizaron técnicas de clasificación de conjuntos (Bagging y Boosting) para superar el preprocesamiento de datos de incidentes de TI y realizar la clasificación automática de incidentes. Según (Mahmood et al., 2023), la aplicación del aprendizaje automático (AA), apoyado en modelos (regresión, árboles, bosque aleatorio, análisis lineal discriminante), permite la clasificación automática de incidentes de TI. Demostrando que el AA ayuda en la GI. Por otro lado, en la ref. (Peña-Torres et al., 2021) se realizó un análisis del enfoque de correlación centrado en la IA y la gestión del cambio digital en las operaciones de TI para encontrar el vínculo en las clases de incidentes en la infraestructura convergente. En, (V V Nikulin et al., 2021) realizaron un estudio para tener una clasificación automática de incidentes y permitir la gestión de solicitudes restaurar la operatividad de los servicios de TI, lo que permitió la reducción de errores humanos y el tiempo de respuesta. También, en (Mohammad Agus Prihandono et al., 2020) realizaron una comparación de los factores causantes de incidentes utilizando técnicas como Random Forest, SVM, perceptrón multicapa, así como AA, RNN, LSTM y GRU para predecir incidentes informáticos. Mientras que en (Alagarsamy et al., 2023) analizaron una metodología para la detección de incidentes en ciudades inteligentes, incorporaron la eficacia del apilamiento de modelos para lograr la clasificación de incidentes según su tipo y grado de impacto. Existen casos de GI en redes ópticas, por ejemplo, en el estudio de (Sousa et al., 2019), se realizó una simulación con el objetivo de minimizar las interrupciones relacionadas con dichas redes ópticas. A raíz de los diversos incidentes de seguridad, en (Ahmad et al., 2021) se propone un modelo de proceso con conocimiento para que las organizaciones respondan a sus incidentes frente a las ciber amenazas. Finalmente, en el estudio (Blaj et al., 2022) implementaron un chatbot para optimizar y automatizar el soporte TI, donde los clientes pueden gestionar sus incidencias y tener acceso a funcionalidades recreativas.
2.Método y materiales
En esta sección se describe la metodología utilizada para este estudio. Se trata de un estudio aplicado con un enfoque cuantitativo y un diseño preexperimental, que se desarrolló siguiendo el plan de investigación. El diseño de la investigación se presenta en la ecuación (1):
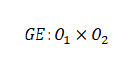 ***
***
Dónde: GE: Grupo experimental; O1: Preprueba; O2: Posprueba; X: Variable de manipulación.
Para este estudio se aplicaron cuestionarios en dos momentos, tanto para el pretest como para el postest a una muestra de representativa del estudio. También, para el diseño e implementación de la solución se ha seleccionado la metodología ágil "Scrum". Scrum es una metodología ágil que apoya a individuos, grupos o entidades en la generación de valor (Schwaber et al., 2020), y se aplica al desarrollo de proyectos, donde las tareas se asignan en Sprints (Iparraguirre-Villanueva, Guevara-Ponce, Paredes, et al., 2022). Scrum consta de 5 fases: iniciación, planificación, estimación, ejecución, revisión y retrospectiva (SCRUMstudy, 2017). 1) Iniciación: esta fase incluye la creación de la visión del proyecto; el Scrum Máster y las partes interesadas se formalizan. El Equipo Scrum (ES) con diversas habilidades y competencias (Shamoon et al., 2023), también se introduce y se entrena, y las historias de usuario se crean priorizando el backlog del producto. Además, se realiza una planificación general de cada componente Scrum (Udanor et al., 2016); 2). Planificación-estimación: en esta fase las partes interesadas se reúnen para establecer o identificar las historias de usuario, estimar las tareas para el backlog del producto (Kadenic et al., 2023), y asignar una caja de tiempo de ocho horas durante un sprint de un mes (Chiru et al., 2021). En este proceso, el ES identifica las actividades a realizar a partir del backlog de producto priorizado para cumplir el objetivo del sprint. 3) ejecución: del mismo modo, en esta fase se ejecutan los Sprints previamente planificados y priorizados, identificando las historias de usuario que los componen. Los objetivos del Sprint no se alteran, ya que aseguran la calidad del Sprint, y permiten renegociar los entregables con el Product Owner (Satheesh et al., 2020); 4) Revisión y retrospectiva: se analiza cada sprint que se desarrolla, es decir, se evalúa el desempeño y se crean recomendaciones para el siguiente sprint. En la revisión se demuestra y valida el sprint, el ES presenta los entregables del sprint al Product Owner, en la retrospectiva se realizan reuniones de hasta 4 horas (Cucolaş & Russo, 2023) y finalmente, 5) despliegue: si bien es cierto, esta fase no se encuentra dentro de scrum, es importante considerarla para cerrar el proceso, dado que en esta etapa se entregan los entregables desarrollados a los interesados del proyecto. Estos entregables son totalmente funcionales. Tras la finalización de cada sprint, se cierra y se realiza el despliegue y comienza el siguiente sprint (Ozcelikkan et al., 2022), sucesivamente hasta completar todos los Sprints del proyecto, en la Figura 1, se presenta la arquitectura del sistema.
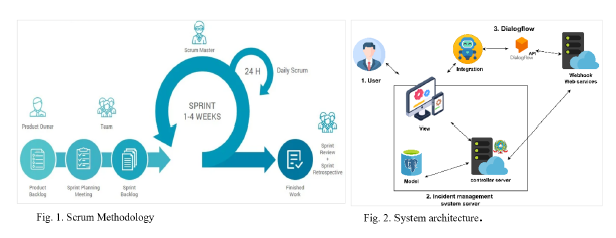
2.1. Caso de estudio
En el siguiente apartado se detalla el procedimiento de desarrollo del AI para la GI, siguiendo la metodología indicada en el apartado anterior. La tabla 1 muestra las herramientas de software a utilizar.
Tabla 1 Lista de herramientas de software usados en la aplicación.
| Herramientas | descripción | versión |
|---|---|---|
| Sistema Operativo | Plataforma | Windows (10) |
| PHP | Lenguaje de programación | 7.4.28 |
| Visual Studio | IDE | 1.71.2 |
| PostgreSQL | Gestor de bases de datos | 14.6 |
| Plataforma Dialogflow | API Chatbot | No aplicable |
| Webhook | Servidor web | No aplicable |
| Laravel | Framework PHP Backend | 8 |
| GitHub | Repositorio en la nube | No aplicable |
| GitHub Desktop | Control de versiones | 2.34.1 |
| Bootstrap | Marco Frontend | 3.0.8 |
| Composer | Gestor de paquetes | 2.24.2 |
2.2. Planificación-estimación
En esta etapa se realizan reuniones para establecer o identificar las historias de usuario a implementar que se contemplan dentro del product backlog priorizado para el cumplimiento del sprint.
Tabla 2 Lista de EPICAS
| Ep | Lista de productos pendientes | ||
|---|---|---|---|
| EP01 | Historial de incidentes | EP09 | Perfiles |
| EP02 | Encuesta | EP10 | Estado |
| EP03 | Acuerdo SLA | EP11 | Incidentes |
| EP04 | Comentarios Incidentes | EP12 | Prioridad |
| EP05 | Técnicos | EP13 | Panel de control |
| EP06 | Colaborador | EP14 | Chatbot |
| EP07 | Usuarios | EP15 | Consulta - chatbot |
| EP08 | Oficinas | EP16 | Tipo de incidente |
Estimación: Esta fase consiste en determinar el tiempo en el que el ES realiza la implementación del backlog del producto, asignándose la prioridad, complejidad y duración de las historias de usuario. Además, los puntos de las historias se estiman utilizando Planning Pocker para identificar su complejidad. La estimación del proyecto dio lugar a cuatro Sprints, como se muestra en la Tabla 3.
Tabla 3 Duración de cada sprint
| N. Sprints | Duración de cada sprint (en días) | Tiempo total en días |
|---|---|---|
| 4 | 16 | 64 |
| Duración en meses | 2.13 |
Tabla 4 Sprints y actividades del proyecto
| EP | HU | Lista de productos pendientes | prioridad | Dificultad | Esfuerzo | Sprint |
|---|---|---|---|---|---|---|
| EP03 | HU-3 | Gestión de contratos | 1 | 20 | 8 | Sprint 1 |
| EP06 | HU-6 | Gestión de técnicos | 2 | 27 | 3 | Sprint 1 |
| EP08 | HU-8 | Gestión de colaboradores | 3 | 21 | 5 | Sprint 1 |
| EP11 | HU-11 | Gestión de usuarios | 4 | 28 | 3 | Sprint 1 |
| EP13 | HU-13 | Gestión de la oficina | 5 | 23 | 5 | Sprint 1 |
| EP14 | HU-14 | Gestión de perfiles | 6 | 25 | 3 | Sprint 1 |
| EP15 | HU-15 | Gestión de estados | 7 | 26 | 3 | Sprint 1 |
| EP16 | HU-29 | Gestión del tipo de incidente | 8 | 29 | 3 | Sprint 1 |
| EP02 | HU-2 | Gestión de encuestas | 9 | 22 | 5 | Sprint 1 |
| EP12 | HU-18 | Gestión de prioridades | 10 | 24 | 3 | Sprint 2 |
| EP16 | HU-16 | Gestión de incidencias | 11 | 17 | 13 | Sprint 2 |
| EP10 | HU-22 | Reconocer intenciones - chatbot | 12 | 19 | 8 | Sprint 2 |
| EP14 | HU-23 | Responder chat - chatbot | 13 | 10 | 5 | Sprint 2 |
| EP07 | HU-7 | Crear perfil y asignar oficina a los técnicos | 14 | 15 | 3 | Sprint 2 |
| EP09 | HU-9 | Crear perfil y Asignar oficina a colaboradores | 15 | 14 | 3 | Sprint 2 |
| EP07 | HU-24 | Registrar usuario mediante chatbot | 16 | 18 | 5 | Sprint 2 |
| EP01 | HU-1 | Ver historial de incidencias | 17 | 9 | 3 | Sprint 3 |
| EP04 | HU-4 | Gestionar comentarios de incidentes | 18 | 12 | 5 | Sprint 3 |
| EP05 | HU-5 | Comentar incidentes notificados | 19 | 13 | 3 | Sprint 3 |
| EP10 | HU-10 | Ver incidentes notificados | 20 | 2 | 5 | Sprint 3 |
| EP14 | HU-17 | Registro de incidentes mediante chatbot | 21 | 1 | 8 | Sprint 3 |
| EP02 | HU-26 | Consultar incidencia por ticket | 22 | 3 | 13 | Sprint 3 |
| EP14 | HU-25 | Validar datos al interactuar con el chatbot | 23 | 11 | 8 | Sprint 4 |
| EP14 | HU-27 | Mostrar opciones de incidencias en el chatbot | 24 | 4 | 5 | Sprint 4 |
| EP07 | HU-28 | Validar usuario | 25 | 5 | 3 | Sprint 4 |
| EP12 | HU-12 | Asignar funciones a los usuarios | 26 | 16 | 5 | Sprint 4 |
| EP13 | HU-19 | Mostrar gráfico de barras del número de tickets según su estado | 27 | 7 | 8 | Sprint 4 |
| EP13 | HU-20 | Gráfico del tiempo de resolución de incidencias | 28 | 6 | 3 | Sprint 4 |
| EP02 | HU-21 | Mostrar la satisfacción del cliente | 29 | 8 | 5 | Sprint 4 |
2.3. Implementación
Sprint 1 y 2: Módulos de Gestión del Administrador del Sistema y Diseño de la Interactividad del Agente Inteligente. En esta etapa se ejecutan los Sprints previamente planificados y priorizados identificando las historias de usuario que los componen.
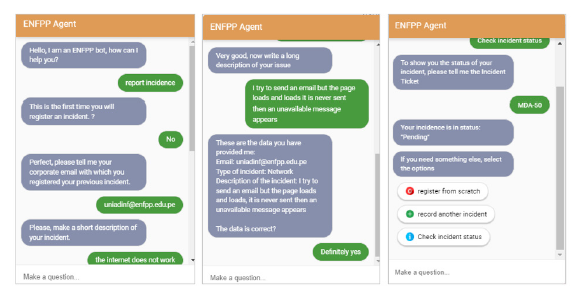
Por ejemplo, los sprints 3 y 4, que incluyen el diseño y la implementación de funcionalidades para la interacción con el usuario, validaciones e informes de cuadros de mando, como se muestra en la figura 2.
2.4. Revisión retrospectiva
En esta etapa se analiza cada sprint que se desarrolla, se evalúa el rendimiento y se crean recomendaciones para el siguiente sprint. En los 3 primeros sprints todo fue bien, con algunas dificultades en: registro de usuarios, inscripción y edición de datos. En el sprint 4, a pesar de algunas complicaciones, se resolvieron con éxito.
2.5. Lanzamiento
La liberación es la fase en la que los productos desarrollados se ponen en funcionamiento y se liberan al público usuario. Durante la liberación se realizan una serie de pruebas para garantizar que el producto funciona correctamente antes de su lanzamiento. Esto ha quedado demostrado, ya que los entregables son totalmente funcionales.
3.Resultados y discusión
En este apartado se presentan los resultados concretos en forma de tablas y gráficos obtenidos del desarrollo del caso de estudio. Asimismo, se genera la discusión, ya que permite analizar e interpretar los resultados obtenidos, en este apartado también se comparan con los resultados de otros estudios similares.
Tabla 5 Elementos del estudio preexperimental
| Elementos Descripción | |
|---|---|
| Ge | Grupo experimental: las pruebas se realizan en el departamento de informática de la Escuela Policial del Perú (EPP) durante un periodo de 30 días. |
| O1 | Medición de la variable dependiente respecto a la GI antes de implantar el sistema web con el bot integrado. |
| X | Sistema web con chatbot = Objetivo a probar |
| O2 | Medición de la variable dependiente en la gestión de incidentes (Postest). |
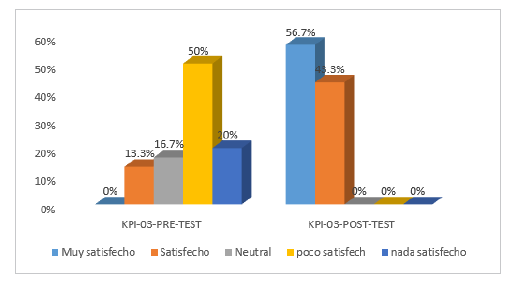
La tabla 6 muestra los indicadores (datos procesados a 30 días). En el indicador satisfacción de los usuarios (KPI-03), la escala Likert de medición es: Nada satisfecho = 1, Poco satisfecho = 2, Neutro = 3, Satisfecho = 4 y Muy satisfecho = 5.
Tabla 6 Valores obtenidos del Pretest y Postest
| # día | KPI-01 | KPI-02 | KPI-03 | |||
|---|---|---|---|---|---|---|
| Pre | Post | Pre | Post | Pre | Post | |
| 1 | 1.5 | 0.5 | 115 | 50.5 | 2 | 5 |
| 2 | 0.5 | 0.5 | 74 | 14.5 | 1 | 4 |
| 3 | 0.5 | 0.5 | 60 | 0.5 | 1 | 5 |
| 4 | 2.5 | 0.5 | 122 | 66.5 | 2 | 4 |
| … | … | … | … | … | … | … |
| 30 | 2.5 | 0.5 | 222 | 0.5 | 2 | 5 |
El EPP fue el centro de investigación donde se desarrolló la investigación, concretamente en el área de tecnologías de la información. Para la implantación del AI para la GI, se propuso el cumplimiento de los siguientes indicadores: conocer el número de incidencias no resueltas (KPI-01); el tiempo de respuesta a las incidencias (KPI-02) y mejorar la satisfacción de los usuarios (KPI-03). Por la literatura estudiada, se sabe que los agentes inteligentes ayudan en los procesos que implican conversación con los usuarios, ya que pueden mantener un diálogo con ellos; además, las incidencias informáticas son una tarea que debe ser atendida a escalada según prioridad para evitar problemas informáticos que impacten profundamente en el negocio. Para medir los datos del Pretest se utilizaron tarjetas de observación, mientras que los datos del Postest se obtuvieron utilizando el AIy el sistema de GI que éste alimenta; los resultados obtenidos se muestran en la Tabla 6 para cada indicador. La Tabla 7 muestra el resumen de los tres indicadores. El KPI-01 tiene una media de 0,55 en cuanto al número de incidencias no resueltos, lo que supone una reducción del 55%; en el KPI-02: tiempo de respuesta a incidencias, se observa que el tiempo de respuesta disminuyó de 137,53 a 31,60; por otro lado, en el KPI-03, según la escala Likert aplicada, la satisfacción media aumentó un 50%.
Tabla 7 Media de indicadores utilizados en el pretest y postest
| Indicadores | Pretest | Post test | |
|---|---|---|---|
| KPI-01 | Incidentes no resueltos | 1.23 | 0.55 |
| KPI-02 | Tiempo de atención de incidentes | 137.53 | 31.60 |
| KPI-03 | Nivel de satisfacción | 2.23 | 4.46 |
3.1. KPI-1: Incidencias no resueltas
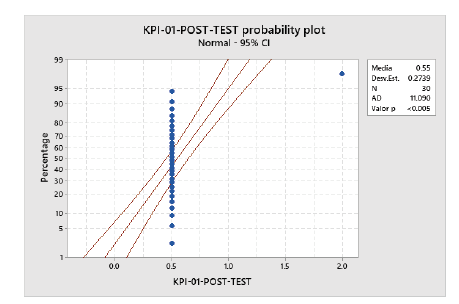
Se realizó una prueba de probabilidad normal para el KPI-01, mostrando que la desviación estándar es de 0,2739 en relación con la media, que tiene un valor de 0,55 incidentes no resueltos por día, y que el p-valor es inferior a 0,05, comprobando que el comportamiento de los datos no es normal. Como se puede observar en la figura 3.
Prueba de Wilcoxon: PRE-KPI-01; POST-KPI-01
Esta prueba muestra que el p-valor es de 0,500, que supera el nivel de significación de 0,05 de aceptación de hipótesis, por lo que se rechaza la hipótesis nula, ya que no se puede demostrar que se haya reducido el número de incidencias no resueltas. Aunque existe una reducción evidente entre las medianas.
Método
η: mediana de PRE-KPI1; POST-KPI1
Tabla 9 Prueba de Wilcoxon
| Hipótesis nula | H₀: η = 0.5 | ||
| Hipótesis alternativa | H₁: η > 0.5 | ||
| KPI | Número de prueba | Estadística de Wilcoxon | p-valor |
| PRE-KPI-01 | 12 | 78.00 | 0.001 |
| POST-KPI-01 | 1 | 1.00 | 0.500 |
3.2. KPI-2: Tiempo de atención de incidencias
Se realizó la prueba de probabilidad normal para el KPI-02, mostrando que la desviación estándar es de 23,62 con relación a la media, que tiene un P-valor de 31,6 minutos con relación al tiempo de respuesta a incidentes, y que el p-valor es mayor que 0,05, comprobando que el comportamiento de los datos es normal. Como se muestra en la figura 4.
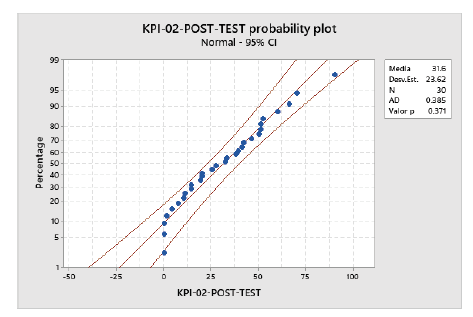
Prueba de Wilcoxon: PRETEST-KPI-2; POSTEST-KPI-2
Esta prueba muestra que el p-valor es de 0,492, que supera el nivel de significancia de 0,05 para la aceptación de la hipótesis, por lo que se rechaza la hipótesis nula; sin embargo, entre la diferencia de medianas, se observa una reducción considerable del tiempo de atención a incidentes. Como se muestra en las tablas 10 y 11
Método
η: Mediana de PRETEST-KPI2; POSTEST-KPI.2
3.3. KPI-3: Nivel de satisfacción
La Figura 5 muestra los resultados del KPI-3, que mide el nivel de satisfacción de los usuarios. Antes de la aplicación del AI, en el pretest aplicado a una muestra de 30 incidencias atendidas, las escalas de satisfacción fueron "Nada satisfecho" = 9%, "Poco satisfecho" = 44,8%, "Neutral" = 22,4% y "Satisfecho" = 23,9%. Mientras que, tras el uso de la herramienta los resultados muestran una variación positiva obteniendo mejoras en la satisfacción de los usuarios como se muestra en las escalas resultantes: para "Satisfecho" = 50,7% y "Muy Satisfecho" = 49,3%, esto prueba y evidencia que el AI implementado eleva el nivel de satisfacción en contraste con el resultado del Pretest.
En cuanto al presente estudio del AI para la GI, se diseñó e implementó con la API de Dialogflow, se utilizó la librería Glicht de node js para hacer un servidor con el fin de alojar el webhook, Mientras tanto, que el webhook hace las peticiones, Dialogflow utiliza fulifilememnt para crear la lógica de negocio y hace las peticiones a webhook en este servidor se configura las peticiones y el webhook lo reconoce de acuerdo a la petición webhook server, No-dejs, para gestionar las historias de usuario se utilizaron Google Docs, Google meet para el trabajo colaborativo en videoconferencia, lo que facilitó un trabajo eficiente por parte del ES y Product Owner. Trabajos relacionados con incidencias, donde utilizan la tecnología aplicada a incidencias de TI, se tiene, en (Jittawiriyanukoon, 2019), categorizó los incidentes agrupándolos según problemas relacionados con hardware, sistema operativo, red, software, redes virtuales, entre otros; considerándolo como un problema multiclase; además, la muestra estudiada presentaba características no deseadas, los datos de incidencias se dividieron en el grupo de entrenamiento con 7519 incidencias y 3223 incidentes para las pruebas de validación; El investigador obtuvo que el modelo Bagged-SVM tenía una mejor precisión de 87. 78% sobre SVM con 71%, seguido de Adaboost-SVM 86% que se posicionó por encima de SVM base 85%; el estudio afirma que la herramienta clasificadora de incidencias favorece la correcta asignación de las incidencias al grupo de soporte adecuado, mejorando la experiencia del usuario y reduciendo el tiempo de respuesta. Sin embargo, en el estudio (Kadenic et al., 2023) exploraron un enfoque basado en redes neuronales convolucionales (CNN) utilizando Deep Learning para la clasificación automática de textos de quejas, capturando características semánticas y clasificándolas automáticamente en categorías predefinidas. Tras la aplicación, sus resultados indicaron que CNN funciona bien para la clasificación de quejas en comparación con las actividades realizadas mensualmente. En ambas investigaciones los autores nos ofrecen como objeto la clasificación, en el primer caso de incidencias y en el segundo de quejas las relacionadas con usuarios finales de un servicio o producto. Los resultados de los dos estudios antes mencionados se correlacionan con los hallazgos de este trabajo, considerando que el desarrollo de aplicaciones inteligentes contribuye de forma directa en la gestión de las incidencias, generando espacios de trabajo con mayor armonía entre los colaboradores, dado que con estas herramientas se desarrolla y optimiza mejor la gestión.
4.Conclusión
En este trabajo de investigación científica, se implementó un Agente In-Smart (chatbot) para la GI, basado en la metodología ágil Scrum, utilizando la Plataforma Dialogflow como API para el Chatbot, Webhook Server para comunicar el Agente con el Sistema de GI. Después del despliegue y uso de la tecnología, la reacción en el resultado tuvo un cambio positivo significativo que redujo en un 14% el número de incidentes no resueltas por día. Con relación al Pretest que presentaba un 57%, a diferencia del Postest con un 43%, también disminuyó en un 63% el tiempo de atención, considerando el 82% del Pretest y el 18% final para el Postest. Asimismo, se observó que el nivel de satisfacción se elevó a "Satisfecho" equivalente al 43,3% y "Muy Satisfecho" al 56,7%, considerando que en el Pretest la percepción fue "Nada satisfecho" = 20%, "Poco satisfecho" = 50%, "Neutral" = 16,7% y "Satisfecho" = 13. Estos resultados demuestran que, aunque la GI de forma manual y física no genera una curva de aprendizaje, disponer de un sistema automatizado con un AI de apoyo a la GI contribuye significativamente a la satisfacción de los usuarios, a la productividad y a su medición. Este estudio científico supone una importante contribución para futuras implantaciones de diseños o desarrollos relacionados con la automatización de la GI mediante agentes inteligentes. A partir de la información encontrada en el trabajo, es posible identificar patrones de clasificación de incidencias, integración de plataformas necesarias para el funcionamiento del chatbot interactivo, aportando fácil usabilidad y valor a la entidad que lo implante. Finalmente, se ha demostrado que el software implementado ha sido capaz de aumentar el nivel de satisfacción de los usuarios, reducir las incidencias pendientes y minimizar el tiempo de atención de incidencias informáticas.

