











 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
Introdução
O ChatGPT (Chat Generative Pre-Trained Transformer) é um modelo de linguagem baseado em Inteligência Artificial (IA), desenvolvido pela OpenAI. É uma feramenta capaz de gerar texto coerente a partir de prompts fornecidos pelos utilizadores. Consiste, assim, num chatbot optimizado para o diálogo, mimetizando uma conversa humana.1,2 As versões mais recentes do software são a versão 3.5 (v3.5) e 4.0 (v4.0), lançadas em Novembro de 2022 e Março de 2023, respetivamente. A utilização da v4.0 implica, até ao momento, o pagamento de uma subscrição mensal, sendo a v3.5 de utilização gratuita.
Desde o seu lançamento, esta ferramenta tem ganho progressiva popularidade, tendo sido amplamente discutidas as suas possíveis utilizações em inúmeras áreas, entre as quais a saúde. Por ser facilmente acessível, possibilita que a população em geral procure informação e formule perguntas relacionadas com a sua saúde, obtendo respostas sucintas e compreensíveis acerca de tópicos da medicina. Contudo, é importante clarificar a correção e validade das respostas geradas pelo ChatGPT.3-5
O interesse crescente em perceber as implicações do ChatGPT na medicina, conduziu ao desenvolvimento de um número considerável de publicações científicas. Na área da otorrinolaringologia (ORL), foram já divulgados vários trabalhos que procuravam avaliar a prestação do software na resposta a perguntas e casos clínicos6-9ou avaliar o seu contributo na investigação clínica. (10-13 Por outro lado, outros autores procuraram também perceber o papel desta ferramenta no esclarecimento dos doentes quanto a patologias ou cirurgias da ORL, tendo obtido resultados promissores. (14-19
A amigdalectomia é uma das cirurgias mais frequentemente realizadas a nível mundial, sendo a maioria realizada em idade pediátrica. (20 Assim, é de prever que muitos pais e cuidadores possam recorrer a informação disponível online, em ferramentas como o ChatGPT, por forma a responder às suas dúvidas quanto ao procedimento, as suas indicações e cuidados a ter no período pós-operatório.
O objetivo do presente trabalho foi avaliar a correção e validade das respostas geradas pelo ChatGPT a perguntas de pais e cuidadores acerca de amigdalectomia em idade pediátrica, à luz da melhor evidência científica disponível. Foi ainda feita a comparação das versões 3.5 e 4.0 do software.
Material e Métodos
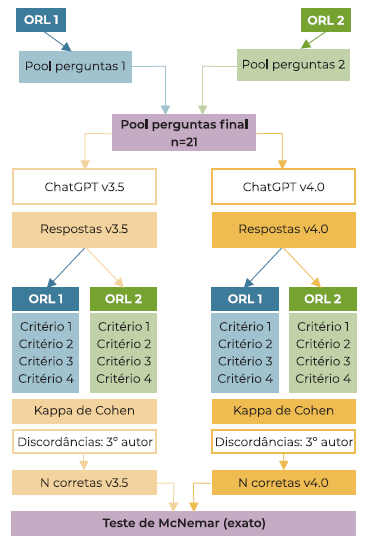
Dois otorrinolaringologistas desenvolveram, de forma independente, questões com base na mais recente versão da guideline de amigdalectomia pediátrica publicada pela Academia Americana de Otorrinolaringologia (AAO). (20 Estas perguntas foram formuladas sob a perspectiva dos pais/cuidadores. Após discussão, foi estabelecido um conjunto final de 21 questões, as quais foram colocadas às v3.5 e 4.0 do ChatGPT. O texto das perguntas foi formulado e introduzido no software em inglês. Não foram incluídos prompts que visassem restringir as referências utilizadas pela ferramenta ou direcionar a resposta de acordo com as características do utilizador.
Foram criadas duas novas contas de ChatGPT - uma para cada versão da ferramenta. Os dois conjuntos de respostas foram avaliados de forma independente por dois autores, de acordo com a guideline da AAO. Cada questão foi avaliada considerando quatro critérios: conformidade com a informação presente na guideline; citação ou referência à guideline; indicação para discutir o conteúdo da resposta com o médico assistente e clareza da resposta. As discordâncias entre avaliadores foram resolvidas por um terceiro autor. O grau de concordância entre os avaliadores foi analisado com o teste Kappa de Cohen. As avaliações das respostas geradas pelas versões 3.5 e 4.0 foram comparadas utilizando o teste de McNemar (versão exata). Os testes estatísticos foram realizados com recurso ao software IBM SPSS Statistics v.29. Os resultados foram considerados estatisticamente significativos para valores de p ≤0.05. A Figura 1 apresenta o fluxograma do estudo descrito anteriormente.
Resultados
Do conjunto final de 21 perguntas escolhidas pelos autores para serem inseridas no software, as primeiras abordavam tópicos relativos às indicações cirúrgicas (questões #1 a #7) e os últimos aspetos relacionados com o procedimento (questões #8 a #21). O segundo grupo subdivide-se em questões relacionadas com os resultados operatórios (#8), riscos do procedimento (#15 a #18) e cuidados pós-operatórios (#9 a #14, #20 e #21).
Das 21 respostas geradas pelo ChatGPT, 13 (61.9%) foram consideradas corretas na versão 3.5 e 19 (90.5%) na versão 4.0, sendo esta diferença estatisticamente significativa pelo teste de McNemar (p=0.031). As restantes respostas foram consideradas incorretas ou incompletas. (Tabela 1). A lista completa das respostas geradas pelo ChatGPT está disponível na Tabela Suplementar.
Tabela 1: Perguntas colocadas às v3.5 e v4.0 do ChatGPT e avaliação das respostas
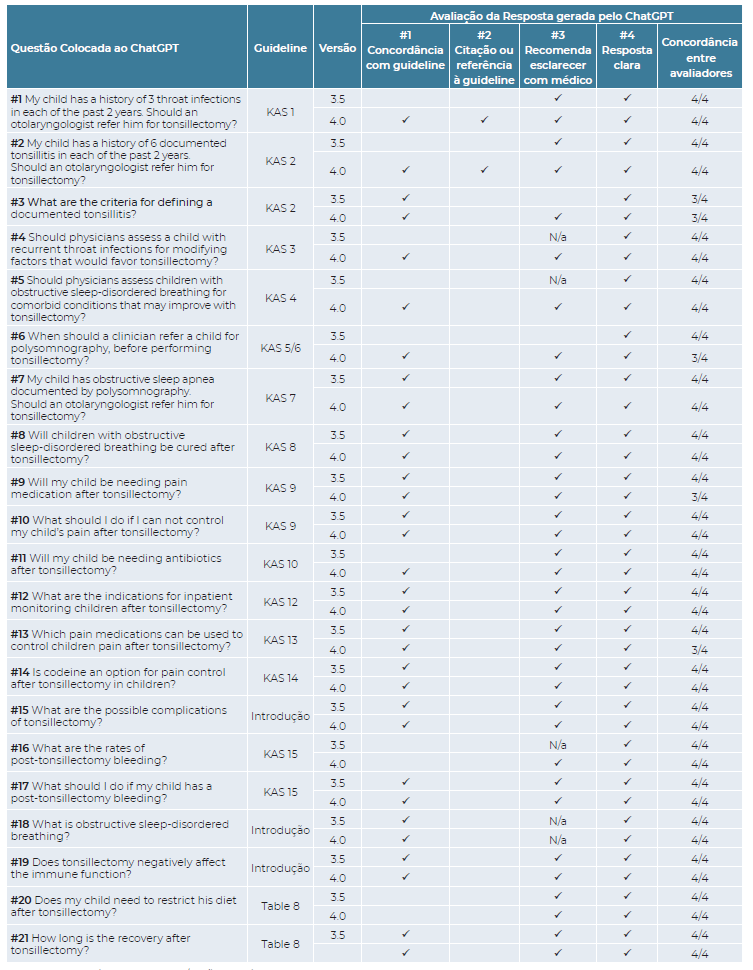
Legenda: critério cumprido; N/a: não aplicável; KAS: Key action statement.
A v4.0 do ChatGPT gerou 2 (9,5%) respostas consideradas incompletas ou incorretas pelos autores, ambas referentes a aspetos relacionados com o procedimento cirúrgico - questão #16 relativa ao risco de hemorragia pós-amigdalectomia (HPA) e questão #20 sobre a necessidade de restrição dietética no pós-operatório. Por outro lado, os autores consideraram incorretas 8 (38,1%) das respostas dadas pela v3.5, 5 das quais referentes às indicações para amigdalectomia (questões #1, #2, #4, #5 e #6). Na sua maioria, as respostas geradas a estas questões eram pouco concretas e evasivas, colocando no médico a responsabilidade sobre a decisão, falhando em remeter os utilizadores para o conteúdo da guideline.
Nenhuma das respostas geradas pela versão 3.5 citou ou fez referência à guideline da AAO e apenas 2 das fornecidas pela versão 4.0 referiram explicitamente a mesma: as respostas às questões #1 e #2, ambas relativas à indicação para amigdalectomia em crianças com amigdalites frequentes.
Quando aplicável, a maioria das respostas mencionou a importância de discutir a informação apresentada com o médico assistente (88.2% na versão 3.5; 100% na versão 4.0). Todas as respostas geradas por ambas as versões ChatGPT foram consideradas claras, usando linguagem adequada ao público de pais e cuidadores (100% para a v3.5 e 4.0).
O grau de concordância entre avaliadores foi muito bom (Kappa de Cohen=0.97 e 0.83 para as versões 3.5 e 4.0, respetivamente).
Discussão
A IA encontra-se em rápido desenvolvimento, surgindo diariamente novas tecnologias e ferramentas que visam facilitar e acelerar diversos processos do quotidiano, nas mais variadas áreas. Desde o seu lançamento em Novembro de 2022 o ChatGPT tem ganho popularidade crescente, apresentando atualmente mais de 180 milhões de utilizadores, a nível mundial. Na área da medicina, poderá ter diversas utilizações por parte dos utentes, os quais têm à sua disposição uma ferramenta acessível, rápida e potencialmente gratuita que lhes permite formular questões sobre a sua saúde. Assim, prevê-se que o ChatGPT possa vir a introduzir alterações no exercício da profissão médica e da relação médico-doente. Torna-se, portanto, essencial avaliar a qualidade da informação gerada, garantindo que esta é fidedigna e se encontra de acordo com a melhor e mais recente evidência disponível.
O presente estudo procurou averiguar se o ChatGPT - nas suas versões 3.5 e 4.0 - poderia esclarecer corretamente pais e cuidadores que fizessem perguntas acerca de amigdalectomia em idade pediátrica. Para tal, comparou-se as respostas geradas pela ferramenta com a mais recente guideline da AAO, um dos documentos mais robustos e consensuais a nível mundial acerca desta temática. Após avaliação por 2 médicos otorrinolaringologistas, considerou-se que apenas 61.9% das respostas geradas pelo ChatGPT v3.5 espelhavam corretamente o conteúdo da guideline. Esta percentagem aumentou para 90.5% com a utilização da v4.0. Assim, os resultados parecem sugerir que a versão paga do software (4.0) gera informação significativamente mais fidedigna que a sua versão gratuita e amplamente difundida (v3.5). Estes achados são concordantes com outros trabalhos previamente publicados, nos domínios da ORL e Oftalmologia. (12,13,21
Comparando o desempenho das duas versões do ChatGPT, observou-se que a v3.5 respondeu de forma incompleta ou incorreta a 5 das 7 questões formuladas acerca de indicações para amigdalectomia. Tal relacionou-se com o facto de as respostas dadas por esta versão da ferramenta terem sido notoriamente mais evasivas, não se comprometendo com uma orientação específica a dar ao doente, remetendo a resposta para o clínico. Por outro lado, a v4.0 respondeu corretamente a todas as questões relativas às indicações cirúrgicas, tendo inclusive, referido o texto da guideline da AAO na resposta às questões #1 e #2. Perante as perguntas acerca do procedimento cirúrgico (resultados, riscos e recomendações), o desempenho das duas versões da ferramenta foi semelhante: 3 respostas incorretas na v3.5 (#11, #16 e #20) e 2 na v4.0 (#16 e #20). Este aspeto parece prender-se com o facto de este segundo conjunto de perguntas avaliar conhecimento objetivamente explanado em diversas fontes; por oposição às questões do primeiro grupo, que requerem integração e interpretação de quadros clínicos com informação presente na literatura, formulando uma resposta. (17
Verificou-se que a maioria das respostas dadas por ambas as versões recomenda a discussão da informação transmitida com o médico/otorrinolaringologista assistente (88.2% na versão 3.5; 100% na versão 4.0). Este aspeto aumenta a segurança da utilização da ferramenta por pais e cuidadores, incentivando o esclarecimento de dúvidas junto dos profissionais, que poderão integrar a informação apresentada com o quadro clínico em questão. Esta tendência é congruente com os resultados de trabalhos anteriores. (15,19
O presente estudo distingue-se dos trabalhos previamente publicados na área da ORL por procurar validar ambas as versões do ChatGPT enquanto instrumentos de esclarecimento da população, através da comparação da informação gerada com a mais recente guideline da AAO sobre amigdalectomia. Com efeito, a validação das respostas foi feita com base num instrumento objetivo, robusto e único, que reúne a melhor evidência disponível à presente data, acerca do tema. Procurou-se, assim, minimizar os possíveis vieses introduzidos por outras metodologias de avaliação, baseadas em opiniões de peritos ou pesquisa bibliográfica não estruturada.
Contudo, os resultados obtidos neste estudo devem ser interpretados cuidadosamente já que foi realizado com uma amostra limitada de 21 perguntas acerca de um único procedimento cirúrgico em ORL. Destaca-se ainda a ausência de avaliação da clareza das respostas do ChatGPT por leigos, tendo estas sido avaliadas apenas por médicos. O próprio ChatGPT apresenta limitações inerentes ao seu funcionamento que influenciaram o desenho do estudo. Destaca-se a importância da qualidade da formulação da pergunta para maximizar a adequação da resposta gerada, algo que pode comprometer a aplicabilidade prática dos resultados encontrados - já que os pais e cuidadores podem ser menos detalhados e específicos nas questões que formulam, obtendo informação menos útil ou clara. Por outro lado, o ChatGPT não fornece espontaneamente referências bibliográficas passíveis de serem consultadas, por forma a verificar a origem da informação apresentada. Uma vez que a ferramenta tem acesso a uma enorme quantidade de informação científica com distintos graus de robustez (livros de texto, guidelines e artigos científicos vs. páginas web sem revisão por pares), é importante que os utilizadores possam consultar as fontes da informação, sendo também essencial programar o software para priorizar informação de maior grau de fiabilidade. Assim, torna-se necessária a realização de mais estudos para a validação formal do ChatGPT enquanto instrumento de educação de doentes na ORL.
Conclusão
O presente estudo, embora numa amostra limitada, sugere que a versão gratuita e amplamente difundida do ChatGPT (3.5) não pode ser considerada uma fonte fidedigna de informação médica, no que concerne à amigdalectomia em idade pediátrica. Por outro lado, a sua versão paga (4.0) parece ser uma ferramenta significativamente mais fiável para esclarecimento dos pais e cuidadores, encontrando-se a maioria das respostas de acordo com o conteúdo da guideline da AAO. Dada a sua preponderância no quotidiano da população, destaca-se a importância de continuar a realizar estudos que visem avaliar e validar a utilização do ChatGPT e outras ferramentas de IA na medicina.
Conflito de Interesses
Os autores declaram que não têm qualquer conflito de interesse relativo a este artigo.
Confidencialidade dos dados
Os autores declaram que seguiram os protocolos do seu trabalho na publicação dos dados de pacientes.
Proteção de pessoas e animais
Os autores declaram que os procedimentos seguidos estão de acordo com os regulamentos estabelecidos pelos diretores da Comissão para Investigação Clínica e Ética e de acordo com a Declaração de Helsínquia da Associação Médica Mundial.

