










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkRISTI - Revista Ibérica de Sistemas e Tecnologias de Informação
versão impressa ISSN 1646-9895
RISTI no.39 Porto out. 2020
https://doi.org/10.17013/risti.39.100-113
ARTÍCULOS
Sistema de recomendación para contenidos musicales basado en el análisis afectivo del contexto social
Recommender system for musical contents based on the affective analysis of the social context
Mauricio Sánchez Barragán1, Gabriel Elías Chanchí G2, Wilmar Yesid Campo M3
1 Institución Universitaria Colegio Mayor del Cauca, Carrera 7 # 2-41, 19003, Popayán, Colombia. mausanbar93@gmail.com
2 Universidad de Cartagena, Avenida del Consulado, calle 30 No. 39 B - 192, 130001, Cartagena de Indias, Colombia. gchanchig@unicartagena.edu.co
3 Universidad del Quindío, Cra. 15 Cll 12 norte, 630004, Armenia, Colombia. wycampo@uniquindio.edu.co
RESUMEN
En la actualidad gracias a la difusión de las redes sociales, se hace necesario aprovechar el contexto social de un usuario, con el fin de enriquecer la toma de decisiones en los sistemas inteligentes. Así, este artículo se centra en el estudio afectivo del contexto social de un usuario, para enriquecer la recomendación de contenidos multimedia musicales más relevantes. De este modo, se propone como aporte un sistema de recomendación de contenidos musicales, el cual relaciona el análisis sentimental del contexto social de un usuario a través de la red social twitter con el análisis sentimental de las letras de las canciones. Así, este artículo presenta los diferentes componentes asociados al sistema de recomendación, tales como: dataset de contenidos musicales, método computacional basado en un clasificador bayesiano encargado de la predecir contenidos musicales a partir del análisis del contexto social del usuario y servicio de música en línea.
Palabras-clave: Análisis de sentimientos; contenidos musicales; contexto; sistema de recomendación.
ABSTRACT
Nowadays, thanks to the diffusion of social networks, it is necessary to take advantage of the social context of a user, in order to enrich decision-making in intelligent systems. Thus, this paper focuses on the affective study of the social context of a user, to enrich the recommendation of more relevant musical multimedia content. In this way, we propose as a contribution a system of recommendation of musical contents, which relates the sentimental analysis of the social context of a user through the social network twitter with the sentimental analysis of the lyrics of the songs. Thus, this paper presents the different components associated to the recommendation system, such as: musical content dataset, computational method based on a Bayesian classifier in charge of predicting musical contents from the analysis of the user's social context and online music service.
Keywords: context; musical contents; recommendation system; sentiment analysis.
1. Introducción
El concepto de las emociones en la música se relaciona al tipo de género o clase de contenidos que una persona escucha (Lundqvist, Carlsson, Hilmersson, & Juslin, 2009), donde incluso se considera la música como un lenguaje de emociones (Ahlberg, 1994) y la importancia de reconocer estas a través de la música y los efectos que genera en el ser humano (Patterson, Uppenkamp, Johnsrude, & Griffiths, 2002). Es por ello que se han abordado una serie de trabajos que permiten ver la importancia de las emociones con la música o contenidos de video. En este trabajo se consideran dos temáticas principales: sistemas multimedia basados en emociones y sistemas de análisis de las emociones.
En cuanto a la primera temática, existen trabajos relacionados con las emociones y contenidos multimedia, tales como (Rho, Han, & Hwang, 2009), donde los autores proponen la relación del estado de ánimo inferido a partir de variables de contexto de usuario, con la recomendación de contenidos musicales. De igual manera este trabajo asocia la emoción de usuario con el contenido a través de las características afectivas de energía y valencia, tradicionales en este tipo de estudios. En (Cunningham, Caulder, & Grout, 2008) definen 9 diferentes tipos de estados emocionales de usuario a partir de variables del contexto como: temperatura, cantidad de luz, entre otros; y los cuales generan uno u otro tipo de contenido multimedia musical previamente clasificado. Trabajos como (Perik, Ruyter, Markopoulos, & Eggen, 2004; Park, Yoo, & Bae, 2006; Chanchí, Campo & Arciniegas, 2018) proponen la recomendación de contenidos multimedia a partir del contexto, emoción o actividad física del usuario; donde unifican que las emociones ayudan en la clasificación y recomendación de contenidos multimedia. Adicionalmente, se tienen plataformas inteligentes de música, tales como: Spotify, rockolaFM y AllMusic las cuales proporcionan contenidos musicales al usuario, de acuerdo a una emoción o categoría; todas ellas se basan en las características musicales tales como: tempo, tono, energía, entre otros; para la asociación del contenido a una emoción. Las anteriores propuestas no consideran el uso del contexto social de usuario para la recomendación de contenidos musicales.
En lo referente a la segunda temática, en (Westerink, van den Broek, Schut, van Herk, & Tuinenbreijer, 2008) se presenta la forma de caracterizar las emociones (negativas, positivas, mixtas y neutrales) a partir de señales biomédicas. Por otra parte, en (Sharma & Kapoor, 2008) se propone un sistema portátil para la medición de bioseñales que permiten el reconocimiento de emociones o estrés mental en usuarios, por medio de un algoritmo de autoaprendizaje. En (Patil, Singh, Singh, & Sharma, 2015) se presenta el estudio de diferentes técnicas para la evaluación y reconocimiento del estrés mental, permitiendo obtener datos que posibiliten la predicción del estado de ánimo de una persona.
De igual modo, trabajos como (Laurier, Grivolla & Herrera, 2008; Yang & Lee, 2009; Hu, Downie & Ehmann, 2010) muestran el estudio para la clasificación de contenidos musicales por emociones, de acuerdo al análisis del audio y componentes de la pista con la letra; esté ultimo presenta diferentes puntos de vista en las soluciones propuestas, ya que para algunos estados de ánimo difieren los resultados esperados en comparación con los obtenidos. Lo anterior, a causa de los diferentes tipos de géneros de las pistas musicales y los idiomas asociados a las letras de las canciones. Finalmente, en (Chanchí & Cordoba, 2019) se realiza un análisis afectivo del discurso de firma del acuerdo de paz en Colombia, mediante el análisis de sentimientos del texto del discurso y el análisis de emociones sobre el audio del mismo. El trabajo mostró concordancia a lo largo del tiempo entre la propiedad valencia de la pista de audio y la polaridad del sentimiento identificado en diferentes partes del discurso. Así, en este artículo se propone una combinación del estudio tanto auditivo como lingüístico de las pistas musicales con el contexto social del usuario, para la recomendación contenidos musicales. Cabe resaltar que tanto a nivel del análisis del contexto social, como en el análisis de las letras de las canciones se toma en consideración los tres estados asociados al análisis de sentimientos: positivo, negativo y neutro.
De este modo, a partir de lo anterior, se plantea como aporte investigativo un sistema de recomendación (SR) de contenidos musicales, basado en el uso del análisis de sentimientos del contexto social de usuario y el estudio lingüístico de las pistas musicales, el cual busca enriquecer la recomendación de contenidos de los enfoques tradicionales.
2. Metodología
Para la conformación del SR de contenidos musicales construido, se proponen cuatro fases a saber: generación del dataset, método computacional para el análisis de sentimientos a partir del contexto social, diseño e implementación del SR de contenidos musicales basado en el contexto social y evaluación del SR a través de un servicio de música en línea (ver Figura 1). En la fase uno (I) se conformó el catálogo de contenidos musicales latinos a ser recomendados al usuario a través del SR; para ello se realizó la clasificación sentimental de los contenidos a partir del análisis emocional-lingüístico. En la fase dos (II) se hizo un análisis del contexto social del usuario por medio de información recolectada a través de twitter, proponiendo a partir de ello un método computacional para el análisis y clasificación del sentimiento asociado al contexto social. En la fase tres (III) se realizó el diseño e implementación del SR de contenidos musicales a partir del método computacional y los datos de entrada del usuario suministrados a través de la red social. Finalmente, en la fase cuatro (IV) el SR es evaluado mediante la implementación de un servicio de música en línea.

3. Generación del catálogo musical
El dataset fue constituido a partir de la exploración de las fuentes de datos que permitieron obtener un listado clasificado de canciones latinas populares. Así, se encontró que la revista Billboard es una fuente especializada en evaluar semanalmente las mejores canciones sugeridas por los usuarios de distintas plataformas musicales. Definida la fuente para la recolección, se estableció un mecanismo de clasificación de contenidos, por lo que se optó por el uso de herramientas para el análisis de sentimientos basado en la letra de las canciones. Lo anterior considerando que muchos usuarios se identifican con una canción no solo por la música, sino también por su letra. En la Tabla 1 se presentan un conjunto de APIs para el análisis y clasificación del contenido.

A partir de lo anterior, se pudo analizar cómo cada una de éstas brinda como aspecto común el análisis ilimitado y de textos en idioma español, lo cual es adecuado para la clasificación de contenidos musicales latinos. Del mismo modo cada una de estas API contempla tres niveles de polaridad para el análisis de sentimientos: positivo (1), neutro (0) y negativo (-1).
En la Figura 2, se presenta un diagrama de flujo del proceso de generación del dataset, donde se incluyen seis etapas: generación de listado de contenidos populares, obtención del contenido lírico, clasificación de contenidos por tipo de sentimiento, obtención URL YouTube, consolidación del catálogo y descarga de contenidos. Para generar el dataset musical se usó la API de Billboard para Python, en la cual se consultaron las canciones latinas más populares del último año.
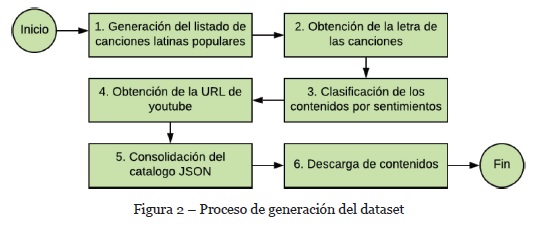
En el paso “1” a través de la API de Billboard, se procede a generar un listado con las canciones latinas más populares del catálogo de la revista Billboard. Para lo anterior, un script se encarga de realizar la consulta de las 100 mejores canciones cada semana en el último año, seleccionando las de mayor ranking.
En el paso “2” se obtienen las letras de las canciones seleccionadas, para ello se llevó a cabo la correlación de los resultados obtenidos por distintas APIs para la consulta del contenido lírico, tales como: lyricwikia, PyLyrics y Musixmatch. Adicionalmente, se complementa el dataset con el contenido lírico de cada canción, para posteriormente realizar el análisis sentimental de cada contenido.
En el paso “3” se genera la clasificación de los contenidos por tipo de sentimiento (positivo, neutral o negativo), lo cual es realizado mediante los métodos matemáticos provistos por las APIs de la Tabla 1. Estas APIs brindan información sobre la polaridad de las letras de las canciones, por lo cual se correlacionaron los resultados y se seleccionó aquel con mayor posibilidad de éxito.
En el paso “4” se procede a obtener para cada contenido musical, la URL disponible en YouTube del video oficial asociado a este, para lo cual se hizo uso de la librería youtube-dl y la API de YouTube. La librería de youtube-dl permite filtrar, seleccionar, descargar el contenido de YouTube por medio de las características como la calidad, título, formato, categorías, fechas, entre otros. Con ayuda de dicha librería se realiza la búsqueda de los títulos para todos los videos en la categoría de música de la API de YouTube y se hace una comparación con los proporcionados por la API de Billboard. Para ello, son filtradas las canciones con una correlación más alta a nivel del texto, haciendo uso del método SequenceMatcher de la librería difflib de Python. De este modo, se seleccionan las URL que sobrepasen el valor de 0.8 de correlación y que correspondan al de mayor número de visitas.
En el paso “5”, una vez obtenidas las direcciones URL, se consolida el dataset en un archivo JSON, administrado por la base de datos libre de Python “tinydb”. Finalmente, en el paso “6” se descargan los contenidos musicales en formato .mp3 haciendo uso de la librería youtube-dl. Así, fueron descargadas 120 canciones para la conformación del catálogo de contenidos musicales latinos, agrupando alrededor de 40 canciones por sentimiento (positivo, neutral y negativo).
En la Figura 3 se muestran los campos asociados a cada uno de los contenidos musicales que constituyen el dataset de contenidos musicales latinos. Cada campo de la pista es representado mediante un color, el cual se presenta en la Tabla 2.
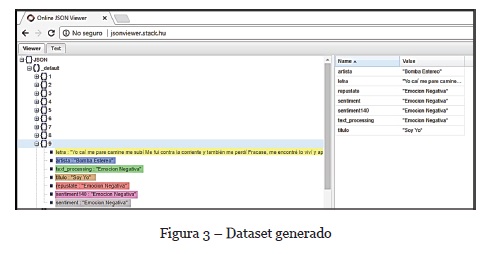
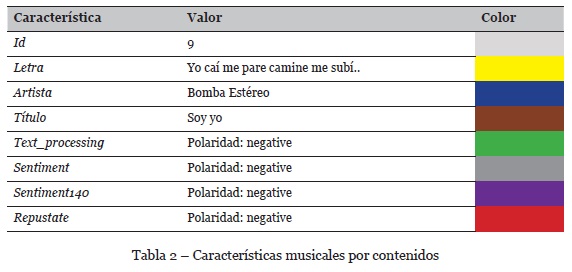
Cada contenido del dataset incluye los campos de la Tabla 2, dentro de los cuales se destaca la letra y los resultados de las APIs de la Tabla 1, las cuales se usaron para hallar la polaridad de los contenidos. Finalmente, se implementó un algoritmo basado en correlación para integrar los resultados de las cuatro (4) tecnologías.
4. Análisis de sentimientos a partir del contexto social
El contexto de un usuario puede entenderse como cualquier información que puede ser utilizada para caracterizar el estado de una entidad, siendo la entidad, una persona, lugar u objeto relevante para las interacciones entre el usuario y la aplicación (Moreno, Segrera, López, Muñoz, & Sánchez, 2015). Dentro del contexto de usuario, se puede determinar tres aspectos importantes: dónde está el usuario, con quién está el usuario y qué recursos hay cerca (Yang, 2009). El uso compuesto de los tres aspectos para caracterización del usuario permite obtener información precisa acerca de las interacciones del individuo. Es por ello que el estudio del contexto abre interrogantes sobre cómo utilizar el contexto de usuario para creación de sistemas inteligentes, los cuales a partir de las preferencias de un usuario recomienden información relevante (Furht & Agarwal, 2013).
4.1. Modelado del contexto de usuario
Para modelar el contexto del usuario, es necesario tener en cuenta los datos del contexto personal, social, de aplicación e histórico. Los datos del contexto personal incluyen elementos como: el perfil de usuario, ubicación del usuario, hora del día o de la semana (día de la semana, fin de semana, vacaciones, entre otros); actividades del usuario (caminar, dormir, hablar, correr, conducir, entre otros); información fisiológica del usuario (ritmo cardiaco, variabilidad del ritmo, sensibilidad de la piel, entre otros); dispositivos personales (móvil, reloj inteligente, tv, entre otros). Dentro de los datos del contexto social se incluyen listas de contactos, vínculos en redes sociales e interacciones y tipos de información compartida. En cuanto a los datos del contexto de aplicación se encuentran: tipos de servicios web utilizados, requisitos de ancho de banda y confiabilidad de cada servicio, tipos de protocolos y mecanismos de acceso necesarios para cada servicio. Dentro de los datos del contexto histórico están: información histórica de las redes sociales, páginas web que navega un usuario, videos y música preferida, compras que ha realizado, entre otros. Así, el modelado del contexto de usuario se puede llevar a cabo tomando como base los tipos de contexto y el uso de técnicas para el análisis de este.
4.2. Tecnologías para el análisis del contexto social
En la Tabla 3 se presenta un conjunto de APIs explorados para la obtención de las publicaciones en twitter de los usuarios del sistema musical. Mediante la exploración de estas APIs, se escogió la librería REST API, considerando que es la que presenta menos restricciones en el acceso a las publicaciones. La obtención de las publicaciones se hizo con el fin de inferir un sentimiento a partir del análisis de las publicaciones del usuario en twitter, para posteriormente recomendarle contenidos musicales previamente clasificados y dispuestos en el dataset.

5. Construcción del SR basado en contexto
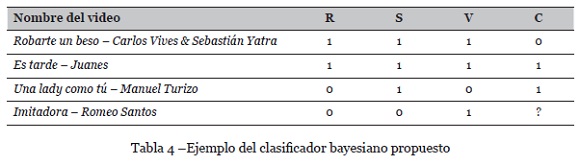
El SR de contenidos musicales se diseñó a partir de un SR clásico tipo booleano basado en el algoritmo de Naive Bayes. El clasificador ordena el contenido relevante al estado afectivo del usuario e infiere sus posibles gustos musicales mientras interactúa con el sistema. La Tabla 4 presenta un ejemplo de clasificador bayesiano, el cual considera la siguiente información relevante del dataset: título, ranking(R), semanas de ranking(S), número de visualizaciones(V) y calificación(C).
Para obtener las características del contenido multimedia, se consultan los parámetros musicales al dataset. Dado que los rangos de valores de las variables utilizadas: ranking Billboard, semanas de ranking en Billboard y número de visualizaciones en YouTube, corresponden a valores no booleanos, es necesario discretizar sus valores (“0” y “1”), para ser usados en el clasificador bayesiano. Para ello se utiliza la ecuación 1, la cual permite discretizar como 1 un valor cuya resta con la media es mayor a 0 y como 0 si la resta con la media es menor a 0.
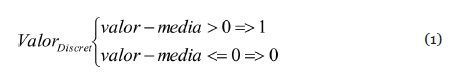
En el caso de la calificación, también es necesario discretizar ya que sus valores oscilan entre 1 y 5, para ello se considera como un “1” las calificaciones mayores a 3 y con un “0” las menores o iguales a este valor. En la Ecuación 2 se presenta la ecuación para discretizar en un valor booleano la calificación.
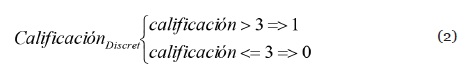
Los valores de ranking, semanas, visualizaciones y calificación discretizados conforman los atributos de entrada del clasificador booleano de Naive Bayes, el cual fue implementado en Java usando la API de la herramienta de análisis de datos weka. Un ejemplo para la obtención de los valores booleanos se muestra en la Tabla 5, donde se tiene para una canción con los siguientes valores de ranking, semanas, visualizaciones y calificación como se aprecia a continuación. Luego del cálculo de la lista de valores booleanos, el clasificador predice la posible valoración que el usuario daría al contenido “Imitadora - Romeo Santos” (columna C de la Tabla 5) teniendo como base calificaciones anteriormente realizadas, generando un listado de videos ordenados según la hipótesis de clasificación más probable.

A continuación, se presenta un esquema de las herramientas utilizadas en la construcción (ver Figura 4) del prototipo del servicio. Este servicio está compuesto por varios componentes tal como: una interfaz web, servidor lógico, sistema de recomendación, base de datos y servidor de contenidos.
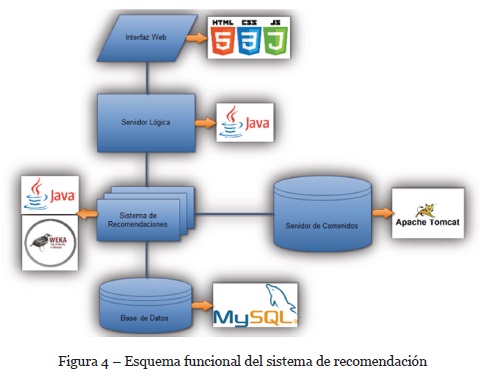
Dentro de los componentes del SR que permitieron la caracterización y recomendación de contenidos al usuario, se encuentra la plataforma y red social de twitter y su widget de chats. Para ello es necesario tener vinculada la cuenta de SRMusical con una cuenta de usuario en Twitter. Como medio de prueba se utilizó una cuenta no oficial “@UsuarioSR1”. La cuenta de Twitter tiene tanto interfaz web como móvil donde el usuario interactúa con los eventos, notificaciones y las publicaciones de otros y propias. Cabe mencionar que el fin de tomar como base la red social de Twitter es poder extraer a partir del análisis computacional afectivo de cada tweet que el usuario realice o replique. Una vez registrada la cuenta de prueba en la red social se procedió con la cuenta “admin” a registrar los datos asociados a cada usuario en la plataforma SRMusical (nombres, cuenta de twitter, contraseña, correo). Cuando el usuario entra a la interfaz del sistema y se valida con los datos puede acceder a la interfaz principal del sistema la cual se presenta en la Figura 5.
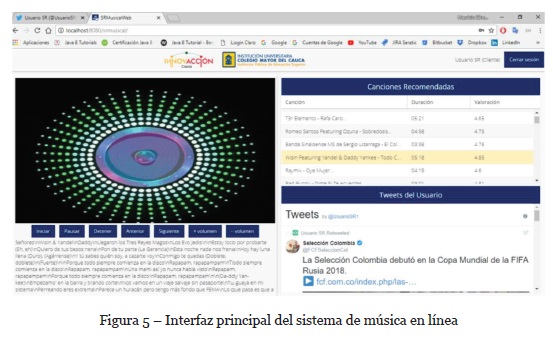
En la pantalla del menú principal se puede observar tres tipos de componentes: un listado de contenidos recomendados, un listado con los tweets publicados o retweets en tiempo real del usuario y un componente de reproducción de los contenidos musicales. Es así como finalmente, se realiza la recomendación de contenidos musicales latinos al usuario a través del servicio de música en línea que tiene como base el SR
6. Evaluación del SR
La conformación del sistema de recomendación y los componentes que permiten la aplicación y uso de las recomendaciones de canciones, se pudo establecer a partir del servicio de música en línea el cual facilita la navegación y pruebas del sistema de recomendación; para ello se analizaron las recomendaciones que el sistema proporcionó al usuario a partir de un mensaje o tweet de entrada, el cual puede estar vinculado a un tipo o estado de emoción (negativa, neutral y positiva) que siente el usuario al momento de publicar el tweet. Las medidas se pudieron definir a partir de los datos recolectados de cuatro (4) diferentes usuarios registrados y los cuales estuvieron interactuando con el servicio de música en línea durante un período de tiempo mientras mantenían igual interacción en la red social de Twitter.
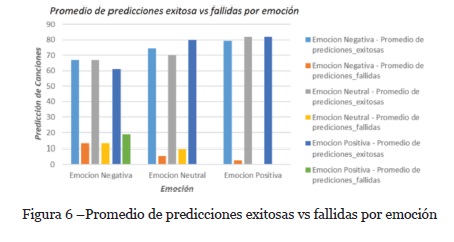
6.1. Promedio de predicciones exitosas vs fallidas por emoción
La primera evaluación que se realizó corresponde al número de predicciones exitosas en comparación a las fallidas por cada sentimiento de entrada asociado a los tweets de los usuarios. En la Figura 6 se pueden observar los resultados del análisis, donde se observa que para el sentimiento negativo el número de predicciones fallidas fue mayor que a los otros sentimientos, esto puede deberse a que el sistema al arrancar necesita como insumo un sentimiento de entrada al sistema y en su mayoría los usuarios no se sintieron identificados con la polaridad negativa, por lo tanto la valoración de las canciones negativas fue variante e inferior, lo cual hace que la probabilidad de recomendar contenidos musicales con polaridad negativa sea variante para el SR. Adicionalmente, la predicción promedio para las polaridades positiva y neutral fue superior a las 70 predicciones de los 80 contenidos musicales que hacen parte de cada sentimiento en el dataset.
6.2. Promedio de predicciones exitosas vs fallidas por usuario
Continuando la evaluación del SR se pudo analizar también el promedio de predicciones por usuario. En la Figura 7, se puede observar el análisis de los datos recolectados para cada uno de los cuatro usuarios durante 3 ciclos de ingreso diferentes y la recomendación de contenidos a partir de los tweets publicados en cada una de las sesiones de interacción.
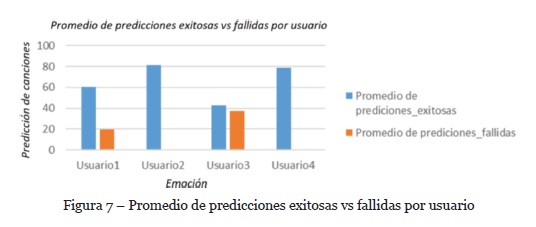
En la Figura 7 se puede evidenciar como los usuarios dos (2) y cuatro (4) obtuvieron un alto promedio de predicciones exitosas o de acuerdo a la polaridad inferida de los tweets publicados, mientras que para el usuario tres (3) la probabilidad de éxito fue similar a la fallida, por lo que para este usuario la predicción del sistema no fue acertada a partir del análisis de los tweets publicados, lo cual pudo ocurrir porque el usuario no tenía un número suficiente de valoraciones de las canciones para tener como base la predicción.
6.3. Promedio de exitosas vs fallidas general
Una vez analizado la predicción de contenidos exitosos por emoción y usuario, se buscó un indicador que permitiera medir el grado o probabilidad de predicciones exitosas y fallidas totales del sistema, para lo cual se generó la gráfica de la Figura 8, donde se puede observar el porcentaje de predicciones exitosas vs fallidas totales de la plataforma durante las pruebas. Este indicador evidencia que el sistema de recomendación tuvo por cada nueve (9) recomendaciones exitosas una (1) recomendación fallida, una probabilidad de 90% de precisión frente a un 10% de margen de error en cada recomendación realizada al usuario.

7. Conclusiones y trabajos futuros
El dataset de contenidos musicales latinos, constituye un aporte importante para el diseño e implementación de servicios de video basados en computación afectiva, integrando las ventajas del dataset musical de Billboard y la información de video provista por la API de YouTube.
El estudio permitió realizar una investigación exhaustiva sobre librerías para la clasificación y descarga de contenidos musicales latinos, los cuales van a ser el insumo principal del sistema de recomendación a proponer. Además, la vinculación del análisis lírico para la clasificación por emoción permitió acotar y mejorar la clasificación por polaridad todos los contenidos que conforman el dataset.
El estudio del contexto de usuario permitió analizar a más detalle las variables que pueden ayudar a caracterizar el perfil o preferencias del usuario, y así poder determinar los gustos o sentimientos que el usuario puede presentar y de alguna manera poder brindar un tipo de contenido musical de acuerdo a sus gustos.
La plataforma SRMusical permite al usuario escuchar un catálogo de contenidos musicales recomendados de acuerdo a su preferencia y polaridad presente en los tweets registrados en la red social de Twitter bajo la cuenta del usuario.
La evaluación del SR permite determinar la precisión de las predicciones de contenidos musicales latinos, en los resultados se pudo evaluar el porcentaje de precisión exitoso es mucho superior a la precisión de error; lo cual permite considerar que la clasificación e inferencia de la emoción o polaridad de un tweet permite la retroalimentación para la clasificación de contenidos por parte del SR.
Como trabajo futuro, se espera vincular más variables del contexto para el análisis de emociones, tales como: la voz, la vista, ritmo cardiaco, entre otros. Adicionalmente, se espera evaluar la experiencia de usuario con el SR
REFERENCIAS
Ahlberg, L. (1994). Susanne Langer on representation and emotion in music. The British Journal of Aesthetics, 34(1), 69-80. [ Links ]
Chanchí, G., & Cordoba, A. (2019). Análisis de emociones y sentimientos sobre el discurso de firma del acuerdo de paz en Colombia. RISTI - Revista Ibérica de Sistemas y Tecnologías de la Información, (E22), 95-107. [ Links ]
Chanchí, G., Campo, W., & Arciniegas, J. (2018). Arquitectura basada en contexto para el soporte del servicio de VoD. RISTI - Revista Ibérica de Sistemas y Tecnologías de la Información, (29), 55-71.
Cunningham, S., Caulder, S., & Grout, V. (2008). Saturday night or fever? Context aware music playlists. In Proceedings of the 3rd International Audio Mostly conference on Sound in Motion, (pp.1-8). https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.489.7774&rep=rep1&type=pdf [ Links ]
Furht, B., & Agarwal, A. (2013). Handbook of Medical and Healthcare Technologies. Springer. [ Links ]
Hu, X., Downie, J., & Ehmann, A. (2010). Lyric text mining in music mood classification. In 10th International Society for Music Information Retrieval Conference, (pp. 411-416). http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=07F1D93AD8D61977789D777FC2B27D00?doi=10.1.1.205.8487&rep=rep1&type=pdf [ Links ]
Laurier, C., Grivolla, J., & Herrera, P. (2008). Multimodal Music Mood Classification Using Audio and Lyrics. In The Seventh International Conference on Machine Learning and Applications, (pp. 1-6). http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.182.426&rep=rep1&type=pdf [ Links ]
Lundqvist, L., Carlsson, F., Hilmersson, P., & Juslin, P. (2009). Emotional responses to music: experience, expression, and physiology. Psychology of Music, 37(1), 61-90. [ Links ]
Moreno, M., Segrera, S., López, V., Muñoz, M., & Sánchez, A. (2015). Web mining based framework for solving usual problems in recommender systems. A case study for movies' recommendation. Neurocomputing, 176(2), 72-80. [ Links ]
Park, H., Yoo, J., & Bae, S. (2006). A Context-Aware Music Recommendation System Using Fuzzy Bayesian Networks with Utility Theory. Fuzzy Systems and Knowledge Discovery, 4223, 970-979. [ Links ]
Patil, K., Singh, M., Singh, G., & Sharma, A. (2015). Mental stress evaluation using heart rate variability analysis: a review. International Journal Of Public Mental Health And Neurosciences, 2, 10-16. [ Links ]
Patterson, R., Uppenkamp, S., Johnsrude, I., & Griffiths, T. (2002). The processing of temporal pitch and melody information in auditory cortex. Neuron, 36(4), 767-776. [ Links ]
Perik, E., Ruyter, B., Markopoulos, P., & Eggen, B. (2004). The Sensitivities of User Profile Information in Music Recommender Systems. In Second Annual Conference on Privacy, (pp. 137-141). http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=185E88759DC8C677F656A5D919FB2330?doi=10.1.1.84.9880&rep=rep1&type=pdf [ Links ]
Rho, S., Han, B., & Hwang, E. (2009). SVR-based music mood classification and context-based music recommendation. In Proceedings of the 17th ACM International Conference on Multimedia, (pp. 713-716). https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.661.6746&rep=rep1&type=pdf [ Links ]
Sharma, T., & Kapoor, B. (2008). Intelligent data analysis algorithms on biofeedback signals for estimating emotions. In International Conference on Reliability, Optimization and Information Technology, (pp. 335-340) . https://doi.org/10.1109/ICROIT.2014.6798350 [ Links ]
Westerink, J., van den Broek, E., Schut, M., van Herk, J., & Tuinenbreijer, K. (2008). Computing Emotion Awareness Through Galvanic Skin Response and Facial Electromyography. En Computing Emotion Awareness Through Galvanic Skin Response and Facial Electromyography, (pp. 149-162). Springer. https://doi.org/10.1007/978-1-4020-6593-4_14 [ Links ]
Yang, D., & Lee, W. (2009). Music Emotion Identification from Lyrics. In Proceedings of the 11th IEEE International Symposium on Multimedia, (pp. 624-629). IEEE. https://doi.org/10.1109/ISM.2009.123 [ Links ]
Yang, Y. (2009). Personalized Redirection of Communication and Data (pp. 902-915). IGI Global. https://doi.org/10.4018/978-1-60566-046-2.ch062 [ Links ]
Recebido/Submission: 22/07/2020. Aceitação/Acceptance: 29/09/2020

