











 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introdução
As técnicas atuais de computação que utilizam a cloud estão-se a tornar insustentáveis, visto que bilhões de dispositivos, impulsionados sobretudo pelo rápido crescimento da Internet of Things (IoT) estão conectados à Internet. Os dados obtidos pelos sensores e aplicações têm aumentado exponencialmente e muitos destes dispositivos permitem agregar num único aparelho funcionalidades de execução de aplicações, comunicação, entretenimento, jogos, entre outros. Além disso, uma das suas principais características é a sua capacidade de identificar e partilhar diferentes tipos de informações ao nível de utilizadores, dispositivo, aplicações e rede. Por outro lado, eles possuem várias limitações como: capacidade de processamento reduzida, escassez de recursos, autonomia reduzida da bateria, baixa conetividade, entre outras. Estas limitações impõem aos analistas e desenvolvedores a adoção de serviços que ampliam a capacidade dessas aplicações em execução nesses dispositivos através da utilização de serviços hospedados na cloud (Fernando, Loke, & Rahayu, 2013).
Não obstante as vantagens, em algumas situações, não é benéfica a utilização da arquitetura cloud. Ela é centralizada e consequentemente o processamento é feito em data centers concentrados, para otimização de custos energéticos e de comunicações. Diferentes técnicas que minimizam a execução na cloud através do processamento local em elementos periféricos que permitem resolver limitações deste modelo têm sido propostas. E uma dessas técnicas passa pela utilização do paradigma fog (Bonomi et al., 2014) que Segundo OpenFog (2017), é uma extensão da cloud e tem sido proposta para colmatar as inconveniências deste, visto que visa reduzir, entre outros, o tempo de resposta, consumo de energia e latência. No entanto, devido a sua densidade e heterogeneidade o escalonamento de tarefas precisa ser tratado com perícia e continuam a apresentar alguns desafios aliciantes que nos levam a questionar a forma como as tarefas são encaminhadas entre os diferentes dispositivos físicos, nós da fog e cloud.
Na fog, devido à maior densidade e heterogeneidade de dispositivos, o escalonamento é muito complexo e, na literatura, ainda existem poucos estudos. Contrariamente, o escalonamento na cloud que é amplamente estudado. Muitas pesquisas abordam, no entanto, essa questão na perspetiva de provedores de serviço ou otimizam os níveis da qualidade de serviço (QoS) da aplicação. Ignoram, porém, informações contextuais ao nível do dispositivo e dos utilizadores finais e as suas experiências de utilização (QoE).
Neste artigo, fizemos um levantamento dos trabalhos relacionados tanto na arquitetura cloud como no paradigma fog, explorámos as suas limitações e sugerimos algumas perspetivas de melhorias. Com base nas sugestões, propomos um modelo de escalonamento sensível ao contexto para o paradigma fog e analisamos o seu desempenho.
Sendo o objetivo principal deste artigo, a elaboração de uma proposta que tenha como âmbito a criação de conhecimento na forma de técnicas, métodos, modelos e teoria, a metodologia de investigação utilizada na sua conceção foi o Design Science Research (DSR). Está dividido em seis secções sendo a primeira, a introdução, a segunda, a contextualização, a terceira, o levantamento dos trabalhos relacionados. Na quarta, são descritos os contextos previstos, o modelo proposto e as suas arquiteturas. Na quinta, é avaliado o desempenho do modelo proposto e feita a comparação com propostas não sensíveis ao contexto e na sexta, é feita a conclusão do artigo.
Como resultado e com base no levantamento dos trabalhos relacionados e na identificação das suas limitações, propomos um modelo de escalonamento de tarefas sensível ao contexto para a arquitetura fog e analisamos o seu desempenho comparando-o com propostas não sensíveis ao contexto.
2. Contextualização
Escalonamento de tarefas refere-se à atribuição de recursos necessários para a execução de uma tarefa. Assume-se como um processo essencial para melhorar a confiabilidade e a flexibilidade dos sistemas e exige algoritmos capazes de escolher o recurso mais adequado disponível para executar a tarefa (Swaroop, 2019).
Pretende-se que os pedidos sejam executados tendo em consideração as restrições definidas, como: tempo, custo, duração da bateria, níveis de sinal da rede, QoS da aplicação, entre outros (Swaroop, 2019). Avança ainda, que devido sua a complexidade, o paradigma fog, apresenta alguns desafios aliciantes que nos leva a questionar a forma como as tarefas são encaminhadas entre dispositivos clientes, nós da fog, servidores cloud, entre outros.
Sistemas lidam com pedidos prioritários, tarefas prioritárias e/ou com requisitos restritos de QoS. Para garantir o seu bom funcionamento e a sua execução dentro dos limites de tempo definidos, o escalonamento precisa ser tratado com perfeição. Escalonamento eficiente de tarefa deve garantir processamento simultâneo e eficiente independentes do seu fluxo. No paradigma fog, o escalonamento constitui um desafio e exige algoritmos avançados capazes de escolher o recurso mais adequado e disponível para executar a tarefa (Mahmud et al., 2016).
2.1 Conceção de algoritmos de escalonamento
Conforme Swaroop (2019), na conceção de um algoritmo de escalonamento, devem ser obedecidas restrições como: custo de tarefas; dependências entre as tarefas e a sua localização. Avança ainda, que as decisões de escalonamentos podem ser estáticas - onde decisão é tomada durante a compilação. Ou dinâmicas - onde são utilizadas informações sobre o estado do fluxo de tarefas num determinado instante durante a execução para a tomada de decisões de escalonamento. Constitui a melhor abordagem, porque possibilita que vários problemas tenham solução que podem ser representados numa árvore de pesquisa. Por outro lado, esses problemas são exigentes computacionalmente, requerem estratégia de paralelização e balanceamento de carga dinâmico.
2.2 Contexto
Segundo Sousa (2017), o termo “contexto” é algo que, à partida, pode parecer simples, mas à medida que refletimos sobre ela, a sua definição torna-se cada vez mais complexa. Em computação móvel o contexto de um utilizador é muito dinâmico. Ao utilizar aplicações nesse ambiente, o comportamento dessa aplicação deve ser personalizado para a situação atual do utilizador. Para promover uma utilização efetiva do contexto, muitos autores disponibilizam as suas definições de contexto. Bazire & Brézillon (2005), examinaram 150 definições de contexto, nas diferentes áreas de investigação e concluíram que a criação de uma única definição é um esforço árduo e provavelmente, impossível visto que a mesma varia com a área científica e depende principalmente do campo em que ela está a ser aplicada. No entanto, avançam que contexto é um conjunto de restrições que influenciam o comportamento relativo a uma determinada tarefa.
A definição de contexto mais utilizada atualmente, mesmo noutros campos, como na vertente da operacionalização foi proferida em Dey (2001), onde ela é descrita como: “Any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between user and an application, including the user and applications themselves.”
3. Trabalhos relacionados
Segundo o conhecimento dos autores, pesquisas sobre algoritmos de escalonamento sensíveis ao contexto no paradigma fog são muito recentes e, na arquitetura cloud, encontramos algumas propostas. Os autores em Deng et al. (2016), Li et al. (2017), Lawanyashri et al. (2017) e Yang et al. (2018) propuseram abordagens que enfatizam a redução do consumo de energia dos data centers e nota-se uma grande preocupação com a eficiência energética.
Em Zhou et al. (2015), é proposto um algoritmo que se baseia na QoS para a Mobile Cloud Server, onde os atributos de tarefas como: privilégios dos utilizadores; tamanho da tarefa; expetativa e o tempo suspenso na fila são utilizados para calcular a prioridade.
Cardellini et al. (2015), propuseram um escalonador distribuído sensível ao QoS para o processamento de fluxo de dados no paradigma fog. No entanto, em topologias que envolvem muitos operadores funciona de forma instável.
Em Stavrinides & Karatza (2019), é proposto um algoritmo leva em consideração o custo da comunicação decorrente da transferência de dados dos sensores e dispositivos da camada da fog durante o processo de escalonamento e em Aazam et al. (2016), é proposto um algoritmo que visa otimizar a utilização dos recursos e QoS.
Skarlat et al. (2017), definiram uma política de escalonamento que visa a colocação de aplicações sensíveis à QoS em nós da fog. Em Intharawijitr, Iida & Koga (2016), tentam garantir a melhor utilização da largura de banda disponibilizada.
Em Sheikhalishahi et al. (2015), Deng et al. (2016), Lawanyashri et al. (2017), há uma evidente preocupação dos autores com a eficiência energética dos recursos. O algoritmo proposto em Shojafar et al. (2015) e Fun et al. (2017), pretende cumprir o deadline das tarefas e aumentar os lucros do provedor de serviços da fog. Nestas cinco últimas propostas, há uma evidente preocupação dos autores em focar e defender principalmente os interesses dos provedores de serviços, ao invés de considerarem os contextos dos utilizadores finais e as suas experiências de utilização.
Li et al. (2017), desenvolveram um algoritmo de escalonamento cooperativo focado em melhorar as recompensas associado as recolhas de dados nas regiões suburbanas.
O algoritmo proposto por Ghouma e Jaseemuddin (2015), explora contexto como níveis da conetividade da rede do dispositivo e o nível de bateria, para a definição das tarefas a serem escalonadas. Enquanto que o proposto por Zhou et al. (2017), exploram os níveis da conectividade da rede e os recursos de Maquinas Virtuais (MV) alugados para disponibilizar decisões de code offloading. Mahmud et al. (2016), propõem uma política de escalonamento de aplicação sensíveis ao contexto para Mobile Cloud Computing que é executado em uma Cloudlet.
O algoritmo proposto em Zhu et al. (2015), é utilizado em tarefas agrupadas com objetivo de minimizar o tempo de execução. O proposto em Oueis, Strinati & Barbarossa (2015), apesar de proporcionar ganho de latência e baixo consumo de energia, tal como os propostos em Cardellini et al. (2015), e Zhu et al. (2015), o desempenho degrada-se quando é utilizado em arquitetura fog de grande escala.
Em Gill, Garraghan & Buyya (2019), é proposta uma técnica de gestão de recursos para ambientes cloud e fog sensíveis ao QoS que, contrariamente ao escalonador padrão da fog, aproveita da otimização Particle Swarm para otimizar em simultâneo vários parâmetros do contexto.
Em Aazam et al. (2016), é proposto um algoritmo que objetiva estimar os recursos da fog com intuito de otimizar a QoE. Em vez disso, Skarlat et al. (2017), propuseram uma abordagem que visa escalonar aplicações sensíveis à QoS em recursos virtualizados da fog. Contrariamente, em Zhu et al. (2015), Oueis, Strinati & Barbarossa (2015), Mahmud et al. (2016) e Aazam et al. (2016), foram tidas em conta as questões relacionadas com o aprimoramento da QoE do utilizador final.
Muitas propostas, como as descritas em Sheikhalishahi et al. (2015), Lawanyashri et al. (2017), Tiwary et al. (2018) e Shinde et al. (2018), abordam o problema da otimização sob a perspetiva dos provedores de serviço e ignoram questões contextuais dos utilizadores finais e as suas experiências de utilização. Outras, como as definidas em: Cardellini et al. (2015), Aazam et al. (2016), Skarlat et al. (2017) e Gill, Garraghan & Buyya (2019), pretendem sobretudo otimizar os níveis de QoS da aplicação e alguns concentram apenas no escalonamento de tarefas na arquitetura cloud e no paradigma fog. Outros, ainda, preocupam-se com a eficiência energética.
3.1 Limitações dos trabalhos relacionados
Diferentes escalonadores têm as suas próprias deficiências, seguidamente destacaremos algumas limitações dos trabalhos relacionados:
Análise de políticas na perspetiva de serviços, a maioria dos escalonadores analisa as políticas apenas na perspetiva de serviço. A otimização dos custos para utilizadores, bem como, o aperfeiçoamento da QoE dos utilizadores não é tido em consideração.
Desconhecimento do contexto do utilizador final, nas técnicas de escalonamento sensíveis ao contexto estudados, os pedidos dos utilizadores finais são analisados num escopo restrito. A força do sinal associado a um pedido, por exemplo, não é tida em consideração. Como consequência, qualquer dispositivo pode ficar desconectado antes ou enquanto obtém resposta de um pedido. O nível da bateria do dispositivo dos utilizadores finais também é ignorado. Para garantir que um pedido sempre tenha respostas em tempo oportuno, um limite para o nível da bateria deve ser preservado.
Escalonamento deficiente de tarefas, escalonadores de tarefas básico como as definidas em Yang et al. (2018), Li et al. (2017), Lawanyashri (2017), Deng et al. (2016) e Qiu et al. (2015), são aqueles que privilegiam a eficiência energética e não consideram a sensibilidade ao contexto, a QoS e a QoE.
Priorização inadequada de tarefas, alguns escalonadores baseados em prioridade foram estudados. No entanto, muitos não descrevem a forma como a prioridade é definida e outros não explicam claramente a metodologia utilizada para a priorização de tarefas.
Aumento do tempo médio de espera, geralmente à medida que os pedidos aumentam, o tempo médio de espera tende também a aumentar proporcionalmente. Nos escalonadores analisados, nenhuma compensação para esse problema é proposta.
Qualidade de experiência subtil, apesar de existirem alguns algoritmos de escalonamentos na arquitetura cloud e no paradigma fog que privilegiam a QoS para a priorização das tarefas, elas não se focalizam em otimizar a QoE do utilizador.
Supervisão para a preservação da QoS, os escalonadores analisados não fazem supervisão com objetivo de preservar adequadamente a qualidade de serviço. Isto é, o tempo máximo permitido para a obtenção de respostas não é considerado em algumas propostas e em outras, é considerado de forma inadequada.
3.2 Perspetivas de melhoria dos trabalhos relacionados
Alguns aspetos podem ser explorados por forma a melhorar as estratégias existentes:
Consciencialização do contexto no escalonamento de tarefas: várias pesquisas asseguram que os escalonadores sensíveis ao contexto são eficientes no aperfeiçoamento da QoS e otimizam os custos, tanto do ponto de vista dos utilizadores como dos provedores de serviço.
Priorização de tarefas sensíveis ao contexto: devem ser introduzidos modelos de escalonamento onde as prioridades são definidas com base no contexto dos pedidos.
Preservação da restrição de energia: a restrição energética deve ser levada em consideração durante o escalonamento de tarefas. O nível da bateria do dispositivo do utilizador final associado a um pedido deve disponibilizar um nível limite da bateria, para que o dispositivo solicitante seja preservado até ao fim da execução.
Conservação da força do sinal da rede: a intensidade do sinal associada a um pedido deve assegurar a força mínima do sinal de forma a possibilitar ao utilizador solicitar recursos e ter respostas em tempo hábil.
Salvaguarda da QoS: atendendo que as tarefas descarregadas na fog são heterogéneas, o escalonador de tarefas deve considerar que o tempo necessário para a obtenção de resposta deve estar confinado dentro dos limites temporais previstos.
Redução do tempo médio de espera: um mecanismo de compensação relativamente ao tempo médio de espera deve ser introduzido pelo escalonador de tarefas de forma a que o aumento do tempo de espera seja proporcionalmente menor em relação à chegada das tarefas.
Otimização da QoE: os algoritmos de escalonamentos devem também concentrar em otimizar tanto a QoE dos utilizadores finais como a QoS.
Propomos na secção 4, um modelo e arquitetura de escalonamento de tarefas sensível ao contexto para o paradigma fog, que incorporam estas sugestões.
4. Modelo e arquitetura proposta
Segundo Fun et al. (2017), ao contrário da arquitetura cloud, o paradigma fog é composta por, no mínimo, três camadas, isto é, nós da borda adicionais são introduzidos entre o utilizador e a cloud.
No nosso modelo assumimos que uma técnica de code offloading adequado (por exemplo, MAUI definido em Bahl et al. (2010), COMET apresentado em Gordon et al. (2012), entre outros) esteja a ser executada nos dispositivos móveis a fim de tomar a melhor decisão em relação ao descarregamento ou não de códigos e em quais nós da fog (Berg, Durr & Rothermel, 2014).
Consideramos que um pedido inclui o atraso máximo permitido para executar a aplicação, o nível de bateria do dispositivo e os valores da força do sinal da rede. Também assumimos, tal como em Deng et al. (2016), que a fog disponibiliza capacidades computacionais muito maiores que os dispositivos móveis e deve ter a capacidade de extrair os contextos associados aos pedidos e tomar a decisão de escalonamento em conformidade.
Musumba e Nyongesa (2013), definiram como os principais contextos que podem ser explorados em qualquer ambiente de computação móvel: a ligação a rede; processadores disponíveis; nível de bateria, a localização; a largura de banda da rede; o tráfego na rede; as maquinas virtuais alugadas e requisitos de QoS da aplicação.
No nosso domínio do problema, os contextos dos provedores de serviços foram ignorados. Também, depois de descarregado a tarefa na fog, torna-se desnecessário considerar os processadores no dispositivo móvel. A localização do dispositivo também não afetará a tarefa do escalonamento, bem como o tráfego na rede e a largura de banda que é igual para todos os utilizadores. Com base nestas considerações, previmos três parâmetros de contexto: nível da bateria; relação sinal-interferência-ruído da rede (SIN) e QoS da aplicação.
4.1 Modelo proposto
Os nós da fog, com a nossa proposta ativada, é constituída por várias unidades de trabalho: Unidade de recuperação de informações de contexto - compreende uma arquitetura, conforme definido em La e Kim (2010). Ela recupera as informações de contexto (C i ) de cada pedido (r ∈ R). As informações de contexto recuperadas são encaminhadas para a unidade de priorização de tarefas sensíveis ao contexto; Unidade de priorização de tarefas sensíveis ao contexto - estima o valor da prioridade de contexto (P r ) para cada pedido individual r ∈ R e o encaminha para a unidade de QoE e escalonamento sensível ao contexto. A Unidade de QoE e escalonamento sensível ao contexto - escalona as tarefas para serem executadas nas MVs em servidores de forma que a QoE do utilizador final seja otimizada.
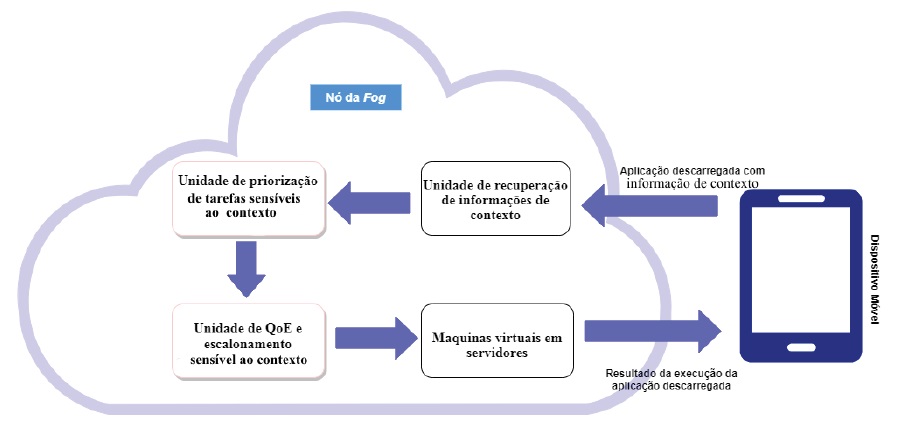
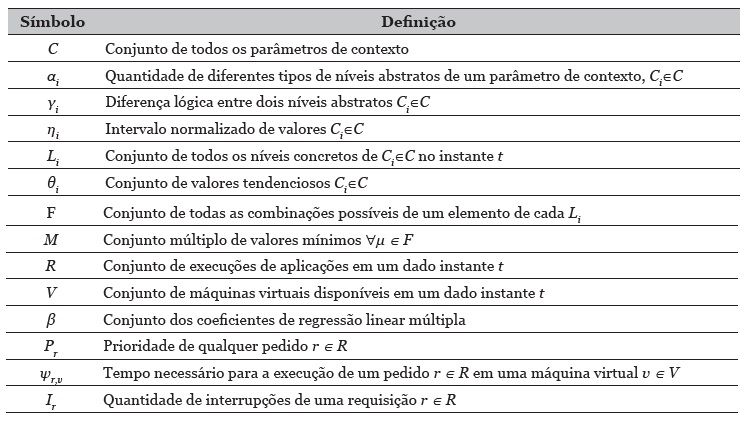
A figura 1, ilustra as diferentes unidades do modelo proposto. As notações relevantes utilizadas na unidade priorização de tarefas sensíveis ao contexto e na unidade de QoE e escalonamento sensíveis ao contexto estão listadas na tabela 1.
Assumimos que algumas MVs estejam criadas com diferentes configurações o que permite minimizar as sobrecargas relativas aos processos de criação e eliminação de MVs, conforme referido em Skarlat et al. (2017). A provisão ótima de MVs para os pedidos e as suas afetações energeticamente eficientes estão fora do escopo deste artigo. Foram, no entanto, discutidas em Li et al. (2017) e Yang et al. (2018).
4.2 Arquitetura do modelo proposto
Em Han (2011), foi proposto um resolvedor de heterogeneidade de contexto, que processa vários parâmetros de contexto, num intervalo normalizado, através da normalização Min-Max. Nas subsecções seguintes são definidas a arquitetura do modelo proposto, a começar pela unidade de priorização das tarefas sensíveis ao contexto.
4.2.1 Unidade de priorização de tarefas sensíveis ao contexto
Esta unidade é composta pelo repositório de contexto, que armazena as informações de contexto das tarefas atuais e anteriormente recebidas e pela unidade de previsão de contexto que explora a informação de contexto num determinado instante de tempo e alimenta a tabela de previsão. Assim, conseguimos eliminar a heterogeneidade das informações de contexto na alimentação da tabela de previsão.
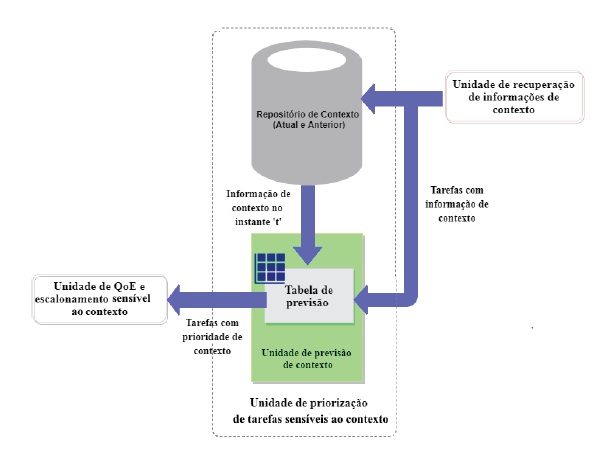
A tabela de previsão, disponibiliza um conjunto de dados para a análise da Regressão Linear Múltipla (RLM) que visa definir a prioridade de contexto dos pedidos atuais. A figura 2, ilustra arquitetura da unidade de priorização de tarefas sensíveis ao contexto do modelo proposto.
4.2.2 Criação da tabela de previsão de prioridade de contexto
Para a resolução de problemas relacionados com a heterogeneidade de informações do contexto, com base na normalização Min-Max, foi concebido um modelo que alimenta a tabela de previsão de prioridade de contexto. O repositório de contexto disponibiliza informações do contexto de tarefas previamente recebidas num determinado instante t. ∀ C i ∈C, todas as informações do contexto são normalizadas em relação aos extremos, os valores ficam concentrados num intervalo entre 0 e 1. Esta abordagem permite minimizar a heterogeneidade dos diferentes parâmetros do contexto em termos de valores e unidades. Definimos o intervalo normalizado, 𝜂 𝑖 , para um parâmetro de contexto, 𝐶 𝑖 ∈𝐶, conforme a equação 1.
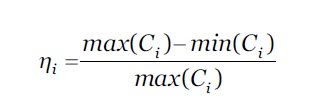 ***
***
Dentro deste intervalo normalizado de um 𝐶 𝑖 ∈𝐶, assumimos que existem 𝛼 𝑖 níveis abstratos. Estes níveis abstratos representam a medição qualitativa do parâmetro de contexto correspondente. Permitem que as variações de valores de um determinado parâmetro de contexto possam ser classificadas internamente. As diferenças lógicas entre dois níveis abstratos consecutivos, 𝛾 𝑖 , de um contexto 𝐶 𝑖 ∈𝐶 são definidas conforme a equação 2.
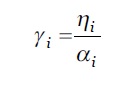 ***
***
A representação numérica desta abstração compreende um conjunto em concreto de níveis, 𝐿 𝑖 , para qualquer 𝐶 𝑖 ∈𝐶. Esta abordagem transforma a medição qualitativa em quantitativa, necessários para cálculos posteriores. O 𝐿 𝑖 é definido conforme a equação 3.
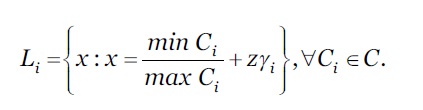 ***
***
Onde z = 0,1,2,…,( 𝛼 𝑖 −1).
O cálculo do produto cartesiano, permitem definir o conjunto combinatório de todos os níveis de contexto a partir dos diferentes parâmetros de contexto. Este produto cartesiano é formulado conforme indicado na equação 4.
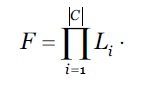 ***
***
Todas as combinações possíveis dos diferentes parâmetros do contexto de uma requisição (𝑟 ∈ 𝑅) são determinadas.
Também é criado um multiconjunto M com os valores mínimos de cada combinação de F, definido conforme a equação 5.
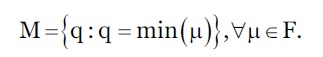 ***
***
Este multiconjunto identifica o estrangulamento de todas as possíveis combinações do contexto de um pedido 𝑟 ∈𝑅 que influência a priorização das combinações simbólicas. Além dos parâmetros de estrangulamento, os valores de enviesamento, associados aos diferentes níveis dos vários parâmetros de contexto, utilizados na priorização, também influenciam a priorização. Este valor de enviesamento permite enfatizar os outros parâmetros. Basicamente, é um mapeamento um-para-um entre os elementos de 𝐿 𝑖 e o conjunto enviesado, 𝜃 𝑖 para um determinado parâmetro de contexto, 𝐶 𝑖 ∈𝐶.
Seja, 𝜃 𝑖,𝑗 refere ao valor mínimo de enviesamento de 𝐶 𝑖 , no seu j-ésimo nível associado a uma combinação candidata em F. Para mapear, 𝜃 𝑖 para L i , 𝜃 𝑖,0 , presume-se, ∀ 𝐶 𝑖 ∈𝐶.
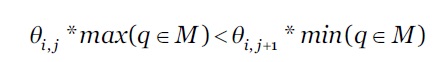 ***
***
As prioridades destas combinações são definidas de forma que a informação do contexto de qualquer pedido possa ser mapeada sobre ela mesma a fim de prever a prioridade desse pedido.
O cálculo da prioridade é feito utilizando os valores relevantes de enviesamento ∀ 𝐶 𝑖 ∈𝐶 e o seu parâmetro de contexto de estrangulamento. Assumimos que 𝛿 𝑖 ( 𝜇 𝑘 ) define a prioridade do contexto 𝜇 𝑘 ∈𝐹 enviesado em 𝐶 𝑖 ∈𝐶. 𝛿 𝑖 𝜇 𝑘 é representado conforme a equação 7.
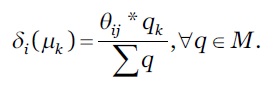 ***
***
Onde, 0≤𝑘 ≤( 𝐹 −1) e 𝑞 𝑘 ∈𝑀 está associada à 𝜇 𝑘 .
A prioridade estimada, 𝛿 𝑖 (𝜇 𝑘 ) de 𝜇 𝑘 é calculada através da equação 8.
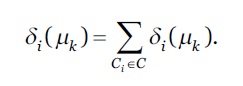 ***
***
4.2.3 Previsão da prioridade do contexto
A RLM é um dos métodos estatísticos multivariados cuja a principal preocupação consiste em estabelecer as relações entre várias variáveis independentes ou preditoras e uma variável dependente ou critério. Ao identificar como estas múltiplas variáveis independentes se relacionam com a variável dependente, as informações sobre as variáveis independentes podem ser utilizadas para fazer previsões precisas e poderosas (Quinn & Keough, 2002). Consideremos, m observações de um conjunto de p número do variável preditor Xs e um variável critério Y associado a elas. O modelo de RLM, que geralmente se ajusta a este cenário, é definido conforme a equação 9.
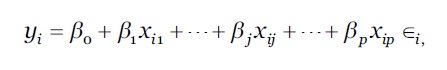 ***
***
onde, para a i-ésima observação, 𝑦 𝑖 = Y e 𝑥 𝑗𝑖 = 𝑋 𝑗 , ∀ 𝑋 𝑗 ∈𝑋. O coeficiente do RLM, 𝛽 0 , é a interceção da população e 𝛽 𝑗 , é a variação de Y em uma unidade de variação em 𝑋 𝑗 , ∀ 𝑋 𝑗 ∈𝑋 𝑒 1≤𝑗≤𝑝, mantendo as outras variáveis independentes constantes, 𝜖 𝑖 é o erro aleatório ou inexplicável associado à i-ésima observação. Os valores estimados dos coeficientes da RLM são calculados através dos valores conhecidos da equação (8) de cada observação, e resolvidos algebricamente. Estimando 𝛽 = { 𝛽 0 , 𝛽 1 , …, 𝛽 𝑝 }, ∀ 𝛽 0 ∈𝛽 e 𝜎 𝜖 2 (erro da variância), a reta de regressão ajustada, que prevê Y para qualquer observação desconhecida, é expressa conforme a equação 10:
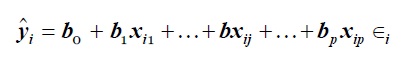 ***
***
onde, 𝑦 𝑖 é o valor previsto para qualquer observação desconhecida, 𝑏 𝑗 é a estimativa da amostra de 𝛽 𝑗 ∀ 𝛽 𝑗 ∈ 𝛽.
Ao invés de calcular as regressões para cada variável preditora individualmente, a RLM utiliza informações de todas as variáveis independentes simultaneamente para prever uma única variável critério. Como resultado, ela é naturalmente mais rápida do que os outros métodos de análise multivariada (Mertler & Reinhart, 2016).
Fazemos o mapeamento da tabela de previsão de contexto para o modelo RLM, considerando cada tuplo da tabela de previsão como uma observação de um conjunto de dados da RLM em que, o conjunto de variáveis independentes, X = C i , ∀ 𝐶 𝑖 ∈𝐶 de cada combinação 𝜇∈𝐹, a variável dependente, Y = 𝛿 𝑖 𝜇 𝑘 é a prioridade prevista de qualquer requisição desconhecida, 𝑃 𝑟 = 𝑦 𝑖 .
Para qualquer pedido 𝑟∈𝑅, quanto menor for o valor 𝑃 𝑟 , maior será a prioridade. A tabela de previsão de prioridade de contexto é criada através dos valores quantitativas ∀ 𝐶 𝑖 ∈𝐶 e dos parâmetros de contexto que são independentes entre si. Após a definição da prioridade do contexto, as informações do contexto desta tarefa são armazenadas no repositório de contexto.
4.3 Otimização do escalonamento das aplicações
A unidade de QoE e escalonamento sensível ao contexto do sistema proposto escalona as tarefas prioritárias para serem executadas em MVs na fog após um intervalo de escalonamento (IE), 𝜏.
De modo a otimizar a QoE dos utilizadores, o escalonador proposto explora a prioridade de contexto (P r ) de um pedido 𝑟∈𝑅 e a sua duração estimada do tempo de execução (T r,v ) para definir o escalonamento desse pedido 𝑟∈𝑅 em uma MV, 𝑣∈𝑉. Se em virtude da quantidade limitada de MVs e à baixa prioridade, um pedido 𝑟∈𝑅 não poder ser escalonada num intervalo de escalonamento, ela deverá ser escalonada nos próximos intervalos. Na nossa proposta, a execução de tarefa com menores prioridades é interrompida em virtude da chegada de tarefa com maiores prioridades. Considerando que essa preempção pode propiciar a espera por tempo indeterminado para a execução de um determinado pedido 𝑟∈𝑅, exploramos também o número de intervalos de escalonamento (I r ), em que um pedido de escalonamento numa MV é adiado desde a sua chegada, com o objetivo de evitar a condição de starvation. Com vista a otimizar a QoE dos utilizadores foi utilizada a técnica de otimização de Programação Não Linear Multiobjetivo (MONLP) para escalonar os pedidos.
Segundo Miettinen (1998), a técnica MONLP é geralmente aplicada aos problemas de otimização onde existem mais de uma função objetivo (FO) não lineares a serem otimizada simultaneamente. Ela possui alguns elementos como: conjunto de funções objetivos não lineares que devem ser otimizadas; variáveis de decisão que constituem o domínio no qual cada FO deve operar; restrições que delimitam o espaço de pesquisa.
Nas secções 4.3.1 e 4.3.2, são definidas as funções objetivos e as restrições para o escalonamento otimizado de aplicações.
4.3.1 Definição da função objetivo
Um dos objetivos desta artigo consiste em escalonar pedidos, 𝑟∈𝑅 em MV, 𝑣∈𝑉, visando otimizar a QoE dos utilizadores para todos os pedidos num determinado intervalo de escalonamento. Assumindo que a execução de todos os pedidos, 𝑟∈𝑅 não são preemptivas e que todas as MVs, 𝑣∈𝑉 estão criadas na fog, a FO é definida conforme a equação 11.
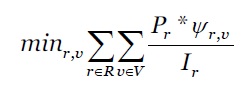 ***
***
E está sujeita a algumas restrições, (inequações (12) à (17)).
Esta equação indica que a QoE de todos os pedidos de aplicações dos utilizadores podem ser otimizadas através da minimização da soma dos seus tempos de execução. Ela também leva em consideração a execução prioritária das tarefas com maiores prioridades através da minimização da soma das prioridades de todas os pedidos, dado que, quanto menor for o resultado, maior será a prioridade obtida. Além disso, a soma dos valores inversos do (I r ), ∀𝑟∈𝑅 mostra que os pedidos, em que foram adiados os seus escalonamentos num determinado intervalo, terão maior prioridade para serem escalonadas nos atuais intervalos, atenuando assim a situação de starvation.
4.3.2 Definição das restrições
Para o escalonamento ótimo definimos as seguintes restrições:
Restrição de capacidade: é apresentada conforme a inequação 12.
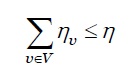 ***
***
Onde, 𝜂 𝑣 representa o tamanho da máquina virtual e 𝜂 é a capacidade total do nó da fog.
Restrição de afetação de MV: é apresentada conforme a inequação 13.
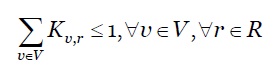 ***
***
Restrição de escalonamento de pedidos: é escrita conforme a inequação 14.
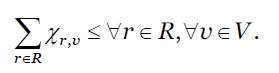 ***
***
Restrição de QoS: é representada conforme a inequação 15.
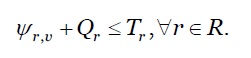 ***
***
onde, 𝜓 𝑟,𝑣 representa o tempo necessário para executar um pedido 𝑟∈𝑅 em uma máquina virtual 𝑣∈𝑉, Q r é o tempo de espera na fila do pedido r. e T r corresponde à QoS da aplicação.
Restrição de consumo de energia: é apresentada conforme a inequação 16.
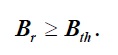 ***
***
onde, B r representa o nível de bateria do dispositivo do utilizador final associado a um pedido, 𝑟∈𝑅 e B th indica o nível mínimo de bateria, para que o dispositivo requisitante se permaneça ligado até ao final da execução.
Restrição da qualidade do sinal: é escrita conforme a inequação 17.
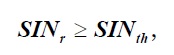 ***
***
onde, SIN r representa a intensidade do sinal associado a um pedido 𝑟 ∈ 𝑅 e SIN th indica a intensidade mínima do sinal necessário para a submissão de um pedido do dispositivo do utilizador final.
4.4 Definição dos parâmetros
Comparado com os outros parâmetros de contextos, o requisito de QoS da aplicação tem maior impacto no aperfeiçoamento da QoE dos utilizadores finais. Por isso, calculamos os valores de enviesamento, 𝜃 associados principalmente a este parâmetro.
O desempenho da solução proposta é influenciado grandemente pelo intervalo de escalonamento, 𝜏. Atendendo que o tempo médio de execução de diferentes pedidos 𝑟 ∈ 𝑅 𝑡 nas diferentes MVs 𝑣 ∈ 𝑉 𝑡 são conhecidos a partir das experiências anteriores. Podemos calcular a previsão do escalonamento estático ( 𝜏 𝑠 ) conforme definido na equação 18.
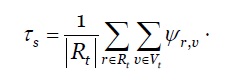 ***
***
O valor 𝜏 estático nem sempre permite uma boa utilização dos recursos. Um valor de 𝜏 alto reduz a sobrecarga do escalonamento, contudo, poderá não conseguir manter a exigência de QoS da aplicação do utilizador nem garantir uma melhor utilização dos recursos computacionais. Do mesmo modo, um valor de 𝜏 muito baixo pode provocar uma grande sobrecarga no escalonamento, assim como poderá possibilitar a existência de alguns intervalos de escalonamento, sem a chegada de pedidos. Portanto, um valor 𝜏 dinâmico permite aumentar o desempenho da nossa proposta, assumindo que a taxa média de chegada dos pedidos varia muito ao longo do tempo. No entanto, na prática, nem a sequência da chegada dos pedidos, nem os respetivos tempos de execução nas MVs obedecem o intervalo de escalonamento estático ( 𝜏 𝑠 ), que é calculada como média aritmética dos valores das experiências anteriores. Por isso, visando aumentar o desempenho do modelo proposto optamos, pelo cálculo do intervalo de escalonamento dinâmico ( 𝜏 𝑑 ), que utiliza a fórmula do Exponentially Weighted Moving Average (EWMA) (Wold, 1994), conforme a equação 19:
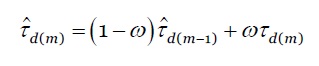 ***
***
onde, 𝜔 é a constante de ponderação, ou o fator de alisamento, onde 0 < 𝜔 < 1 e 𝜏 𝑑(𝑚) , é a média aritmética dos tempos de execução dos pedidos em todas as MVs no intervalo de escalonamento m-éssimo. Conforme a equação 20.
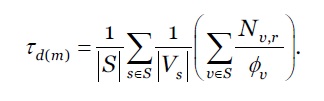 ***
***
onde, S e V s significam respetivamente o conjunto de servidores e de MVs em cada servidor. N v,r representa o número de instruções de um pedido 𝑟∈𝑅 executada numa MV 𝑣∈ 𝑉 𝑠 com velocidade de processamento 𝜙 𝑣 .
Na secção seguinte, é feita a avaliação do desempenho do modelo proposto.
5. Avaliação de desempenho do modelo proposto
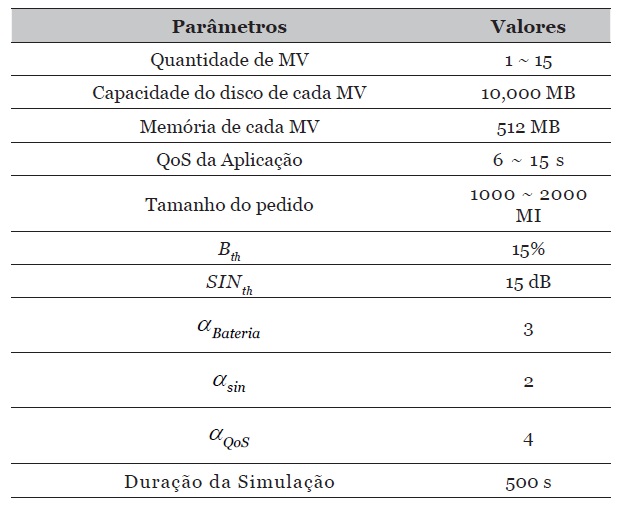
O ambiente de simulação do modelo proposto foi desenvolvido no kit de ferramentas de simulação iFogSim e modela uma fog composta por três hosts com parâmetros conforme a tabela 2.
5.1 Métricas de desempenho da análise do modelo proposto
As seguintes métricas de desempenho foram utilizadas para comparar a nossa proposta de escalonamento (com Intervalo de Escalonamento (IE) estático e dinâmico) com abordagens de escalonamento não sensíveis ao contexto como: FCFS, SJF e QoS-based:
Percentagem de execução dos pedidos bem-sucedidos: é calculada através da razão entre a quantidade de tarefas que preservam os diferentes parâmetros de contexto e a totalidade de tarefas solicitadas. Quanto maior for esta percentagem, maior será a quantidade de tarefas que preservam os diferentes parâmetros de contexto.
Tempo médio de espera de uma tarefa: é o tempo decorrido desde a sua chegada até a sua disponibilização numa MV. Q r indica o tempo de espera de um pedido 𝑟∈𝑅. O tempo médio de espera de uma tarefa é calculado conforme a equação 21.
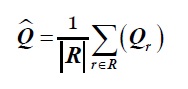 ***
***
onde R representa a totalidade dos pedidos recebidos durante o período de simulação. Quanto menor for o valor de 𝑄 maior será o desempenho.
Qualidade da Experiência (QoE): é o grau de satisfação global dos utilizadores relativamente à utilização de um produto ou serviço. Pode ser aperfeiçoada através da diferença entre o tempo máximo permitido para a obtenção da resposta (requisito QoS da aplicação), T r e o tempo de resposta de um pedido.
Calculamos a média de QoE de todos os pedidos R expedidos durante a simulação conforme a equação 22.
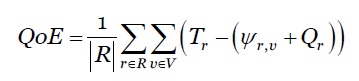 ***
***
Quanto maior for este valor, melhor será a capacidade do sistema em otimizar a QoE do utilizador.
Os resultados da avaliação, obtidos através da simulação implementada com base nos parâmetros da tabela 2, são descritos na subsecção 5.2.
5.2 Resultados e discussões
Uma análise detalhada ao ficheiro da simulação permite-nos concluir que a taxa de sucesso no escalonamento das aplicações sensíveis ao contexto é superior em comparação com os escalonamentos não sensíveis ao contexto. No modelo proposto, os pedidos dos dispositivos em situações de vulnerabilidades, com baixos valores de contextos, possuem maior precedência de execução. Isto é, é-lhes assegurado o funcionamento prioritário por forma a poderem receber o feedback da fog. No entanto, como a fog possui recursos limitados, o que afeta a performance de serviço, a taxa de sucesso diminui quando aumentam a quantidade dos pedidos.
Seguidamente, apresentamos e discutimos a variação dos pedidos executados com sucesso em relação ao aumento de pedidos, MVs e requisitos QoS da aplicação.
5.2.1 Impactos do aumento de pedidos
As percentagens dos pedidos executados com sucesso preservando os diferentes parâmetros de contexto (mantendo constante a quantidade de MVs), são apresentadas nos gráficos 1, 2 e 3. O tempo médio de espera e a QoE neste cenário são apresentadas nos gráficos 4 e 5, respetivamente.
Na nossa proposta, os pedidos provenientes de dispositivos com nível de bateria baixo têm maior prioridade. São executadas com maior precedência. Como resultado, os dispositivos obtêm as respostas aos pedidos antes do dispositivo se desligar devido a insuficiência da bateria. Consequentemente, o sistema proposto possui um melhor desempenho em comparação com as outras abordagens em estudo, conforme ilustrado no gráfico 1. Isto deve-se ao facto de que nenhum dos outros algoritmos estudados se preocupa com o contexto do nível da bateria. Além disso, o sistema proposto (com IE dinâmico) diminui o tempo de inatividade dos recursos da MV nos servidores o que permite aumentar as hipóteses para os pedidos com contextos críticos serem executadas com maior prioridade.
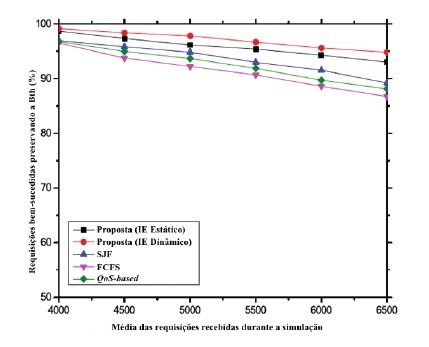
Gráfico 1 Tarefas executadas com sucesso preservando o nível da bateria em relação ao aumento de pedidos.
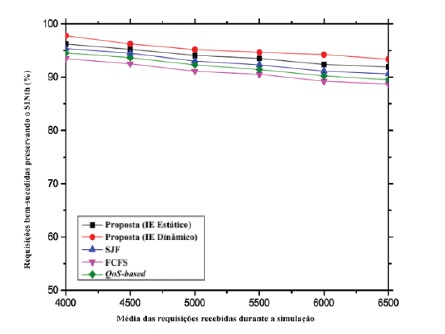
Gráfico 2 Tarefas executadas com sucesso preservando o nível do sinal em relação ao aumento de pedidos.
Da mesma forma, podemos observar através do gráfico 2 que em todas as abordagens estudadas, a percentagem de pedidos de aplicações executados com sucesso preservando o nível do sinal, também diminui gradualmente devido ao aumento de receção dos pedidos. Como teoricamente esperado, a quantidade de pedidos com valores críticos do SIN aumentam em função do aumento da quantidade de pedidos e, como consequência, o desempenho total diminui ao longo do tempo.
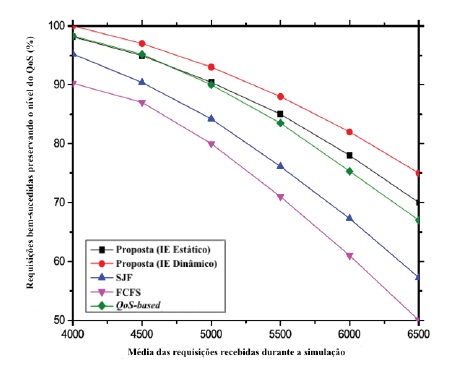
Gráfico 3 Tarefas executadas com sucesso preservando o nível da QoS em relação ao aumento da quantidade de pedidos.
O gráfico 3 ilustra que a percentagem dos pedidos executados com sucesso, preservando as exigências da QoS, diminui drasticamente em todas as abordagens de escalonamento estudadas em função do aumento da quantidade de pedidos. A razão subjacente a este resultado é explicada pelo facto de que o aumento dos pedidos também permite aumentar o tempo de espera, o que obriga muitas tarefas a violarem os requisitos de QoS. No entanto, o desempenho da nossa proposta supera o dos outros algoritmos (FCFS, SJF, QoS-based). No modelo proposto, o impacto dessa diminuição é significativamente menor, dado que ela privilegia o escalonamento de acordo com os seus requisitos de QoS. Por fim, o resultado demonstra que, para todos os casos, o intervalo de escalonamento dinâmico produz um impacto ainda melhor de desempenho em comparação com o seu equivalente estático.
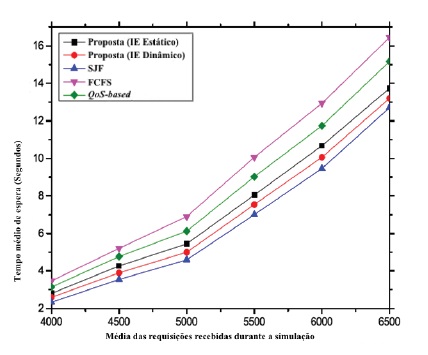
O gráfico 4 ilustra que o tempo médio de espera no modelo proposto é inferior em comparação com a maioria das outras técnicas não sensíveis ao contexto.
Isto deve-se ao facto de o escalonamento no modelo proposto não considerar apenas o contexto das tarefas, mas também as interrupções dos mesmos enquanto estão na fila de espera para serem escalonadas e ao seu tamanho individual. Por conseguinte, uma tarefa deve ser penalizada por um período curto devido a outros fatores e uma tarefa trivial não deve esperar muito tempo para ser executada, devido à execução de uma tarefa maior.
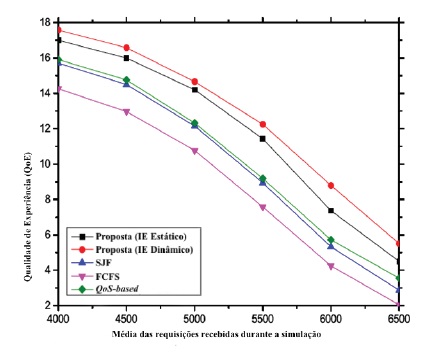
O gráfico 5 ilustra a otimização da QoE dos utilizadores finais.
O sistema proposto privilegia a execução de tarefas com valores de contexto mais baixos. Como resultado elas são executadas respeitando um tempo mínimo e atraso de resposta tolerável. Relativamente às outras tarefas com parâmetros de contexto adequados, este cenário é suportado de forma intrínseca. Assim, a QoE dos utilizadores é otimizada em todos os cenários possíveis. Em comparação com a maioria das outras técnicas não sensíveis ao contexto, elas muitas vezes não conseguem otimizar a QoE, porque de acordo com os seus critérios de escalonamento, enquanto satisfazem um pedido com maior prioridade, o pedido com menor prioridade pode não conseguir manter a sua tolerância de QoS. Nos piores cenários, poderá resultar em valores de QoE negativos, enquanto que, no modelo proposto, o valor de QoE é sempre positivo.
5.2.2 Impactos do aumento de MVs na fog
As percentagens das tarefas executadas com sucesso preservando os diferentes parâmetros de contexto, assumindo que a quantidade de pedidos recebidos durante a simulação é constante em relação ao aumento da quantidade de MVs, são ilustrados nos gráficos 6, 7 e 8. Os gráficos 9 e 10 ilustram respetivamente o tempo médio de espera e QoE dos utilizadores no critério impactos do aumento de MVs.
Se o número de MVs aumentar, também aumenta a taxa de sucesso na execução dos pedidos que satisfazem os vários condicionalismos contextuais. Este cenário é apresentado nos gráficos 6 e 7 tanto em termos de níveis da bateria como em relação à força do sinal da rede.
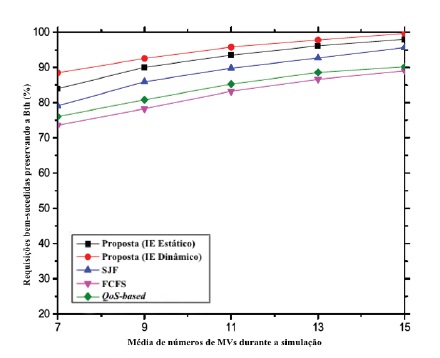
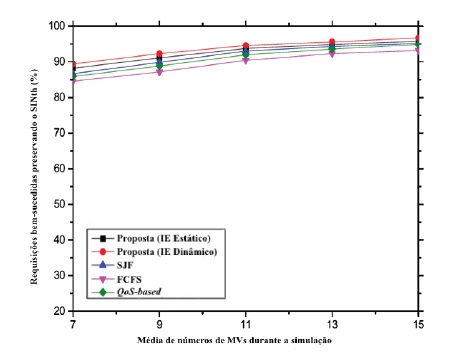
O gráfico 8 ilustra que a percentagem dos pedidos executados com sucesso preservando o nível de QoS em relação ao aumento das máquinas virtuais. Excetuando o comportamento normal para valores mais altos no eixo X, a taxa de sucesso é consideravelmente mais alta no sistema proposto em comparação com os outros algoritmos, o mesmo também se verifica em relação aos valores mais baixos do eixo X.
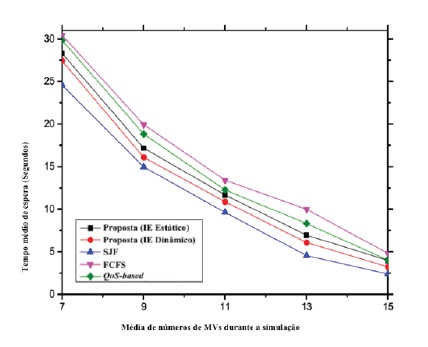
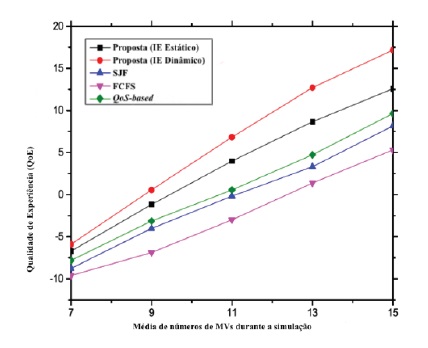
Quanto ao tempo de espera e QoE em relação ao aumento de MV, conforme os gráficos 9 e 10, apresentam cenários teoricamente comprovados. Mesmo assim, o desempenho do modelo proposto é sempre superior em comparação com as outras políticas.
5.2.3 Impactos do requisito QoS da aplicação
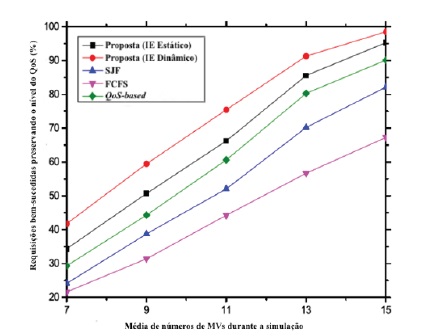
Nos gráficos 11 e 12 é ilustrado o impacto do requisito QoS dos pedidos no desempenho do modelo proposto. Ilustram que à medida que aumenta o tempo médio admissível de resposta aos pedidos, aumentam também as percentagens das tarefas satisfeitas em termos de QoS e QoE. Isto acontece porque o tempo de execução dos pedidos diminui. Consequentemente, é possível executar tarefas de acordo com a sua exigência de QoS e dentro do tempo mínimo estabelecido. Este facto permite o aperfeiçoamento da QoE dos utilizadores. As outras técnicas de escalonamento não sensíveis ao contexto, em comparação com o modelo proposto, revelam menos eficiência neste cenário.
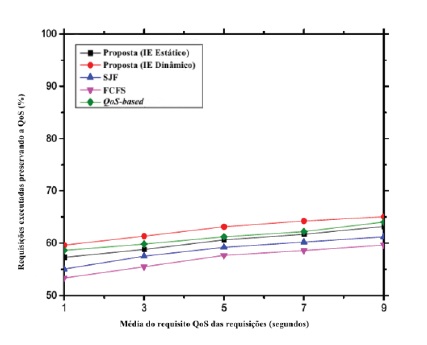
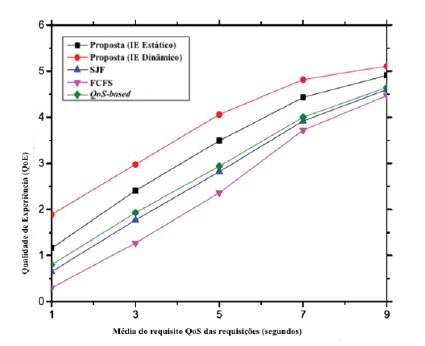
5.3 Resumo das simulações
Em síntese a esta experiência, afirmamos sem dúvida que a política de escalonamento sensível ao contexto proposta, é eficiente em relação à quantidade de tarefas escalonadas e que satisfazem a QoS, diminuição do tempo de resposta, otimização de QoE, redução do tempo médio de espera, entre outros, em comparação com as políticas de escalonamentos não sensíveis ao contexto. Tendo em consideração as observações fundamentadas apresentadas, podemos afirmar que a nossa proposta de escalonamento possui condições para ser implementada em ambientes práticos.
6. Conclusões
O objetivo principal deste artigo consiste em definir um modelo de escalonamento de tarefas sensíveis ao contexto para o paradigma fog. Como apresentado, o modelo proposto é suficientemente eficiente para priorizar tarefas independentemente da heterogeneidade das suas informações de contextos. Ademais, consegue otimizar a QoE dos utilizadores e permite situações vantajosas em termos de utilização de recursos e tempo de execução.
As principais conclusões alcançadas com base no levantamento de trabalhos relacionados tanto na arquitetura cloud como no paradigma fog foram que o escalonamento na cloud, foi amplamente estudado. Enquanto que na fog, devido densidade e heterogeneidade de dispositivos, o escalonamento é complexo e ainda existem poucos estudos. Muitos dos algoritmos estudados possuem várias limitações: não descrevem a forma como a prioridade é definida; não explicam o método utilizado na priorização de tarefas e nem definem a priorização de tarefas com base em informações do contexto; muitos defendem a perspetiva dos provedores de serviços; outros são aplicados em tarefas agrupadas para diminuir o tempo de execução; alguns otimizam apenas a QoS. Outros, exploram alguns contextos. Identificamos e sugerimos algumas perspetivas de melhorias podem ser explorados e melhorados como: a utilização do contexto no escalonamento; priorização de tarefas sensíveis ao contexto; consideração da restrição energética no escalonamento; preservação da força do sinal da rede; preservação da QoS; redução do tempo médio de espera e otimização da QoE.
Com base nessas sugestões de melhorias propomos um modelo de escalonamento de tarefas sensíveis ao contexto para o paradigma fog que utiliza a normalização Min-Max, para resolver o problema da heterogeneidade dos diferentes parâmetros de contexto, o método da RLM para a definição das prioridades dos pedidos e a técnica MONLP para o escalonamento ótimo visando otimizar a QoE dos utilizadores. A definição dos parâmetros do sistema permitiu um escalonamento mais eficiente, que garante a boa utilização dos recursos, bem como a execução eficaz das tarefas.
A validação do modelo e da arquitetura proposta, foi feita com base em simulações realizadas no kit de ferramentas iFogSim, que nos possibilitou fazer comparações experimentais e teóricas da nossa proposta sensível ao contexto, tanto para intervalos de escalonamento estáticos como dinâmicos com escalonadores não sensíveis ao contexto (FCFS, SJF, QoS-based) com base nas seguintes métricas: taxa de sucesso dos pedidos; tempo médio de espera e QoE dos utilizadores.
Apesar de considerarmos vários parâmetros de contextos na nossa proposta, acreditamos que outros ainda podem ser escolhidos por forma a influenciarem ainda mais significativamente o escalonamento. Concluímos afirmando que todos os objetivos propostos foram alcançados.

