











 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introdução
No contexto econômico contemporâneo do Brasil, a inadimplência se destaca como uma preocupação persistente e de significativa amplitude. De acordo com (Serasa, 2023), que apresenta o Mapa da Inadimplência no Brasil, observa-se uma realidade alarmante: mais de 71 milhões de cidadãos brasileiros enfrentam a inadimplência, o que corresponde a aproximadamente 43% da população (Serasa, 2023). Essa estatística impactante, além de espelhar uma realidade econômica complexa e desafiadora, evidencia a imperativa necessidade de aprofundar nosso entendimento sobre a questão e aprimorar a eficácia das estratégias de recuperação de dívidas.
A inadimplência é caracterizada como a falta de pagamento ou o não-cumprimento de um contrato ou cláusula, ou seja, a não-satisfação da obrigação no prazo determinado (Sehn e Carlini Junior, 2007). A inadimplência e a cobrança de dívidas estão ligadas em um ciclo financeiro envolvendo credores e devedores, e nesse contexto tem-se a operação de cobranças de dívidas visando recuperar valores em débito (Tambellini, 2021). Essas operações têm evoluído significativamente, impulsionado por diversos fatores econômicos, sociais e tecnológicos. Inicialmente ancoradas em métodos tradicionais, como o envio de correspondências e telefonemas diretos, as estratégias de cobrança têm gradualmente migrado para abordagens mais sofisticadas devido ao avanço tecnológico e à crescente digitalização (Tambellini, 2021).
A inadimplência transcende a mera questão do cumprimento de obrigações financeiras, convertendo-se em um problema de relevância crítica que afeta não apenas a economia do país, mas também a vida cotidiana de milhões de brasileiros. E neste cenário observa-se uma crescente demanda por parte das instituições financeiras em busca de soluções eficazes para a gestão de dívidas e a recuperação de crédito, assim como a adoção de medidas governamentais de apoio, exemplificado pelo programa "Desenrola Brasil". Oficialmente lançado pelo Governo Federal em junho de 2023 e posteriormente regulamentado pelas Portarias Normativas MF Nº 634/23 (Brasil, 2023a) e MF Nº 733/23 (Brasil, 2023b), este programa representa uma iniciativa significativa para enfrentar o problema da inadimplência, buscando facilitar a renegociação de dívidas e estimular o potencial de consumo da população. Essa abordagem conjunta reflete a urgente necessidade de ações coordenadas e eficazes diante dos desafios econômicos atuais.
Entretanto, além das medidas macroeconômicas e das políticas governamentais, é crucial considerar a inovação e a adaptação de estratégias específicas para a gestão da inadimplência em um mundo cada vez mais influenciado pela tecnologia e pelos avanços na ciência de dados. Conforme observado por Schwab (2018), a Inteligência Artificial (IA) representa uma das características definidoras da quarta revolução industrial, com avanços notáveis ocorridos nos últimos anos. Além do aumento na capacidade de processamento dos computadores como um dos seus impulsionadores, o crescimento exponencial de dados, também conhecido como o fenômeno "big data", tem contribuído para esse avanço. Ele alavancou uma subcategoria da IA, o Aprendizado de Máquina ou Machine Learning (ML). A expressão "machine learning", atribuída a Samuel (1959), delineia a área que confere a sistemas computacionais a habilidade de adquirir conhecimento de maneira autônoma, sem requerer programação explícita.
Esse aprendizado do algoritmo pode se dar segundo diferentes estratégias (Russel e Norvig, 2022):
Aprendizado Supervisionado (Supervised Learning): Algoritmos são treinados em conjuntos de dados com exemplares contendo uma série de suas características (atributos) e uma categoria (rótulos) do exemplar. O objetivo é que o modelo aprenda a estabelecer correspondências entre características e rótulos
Aprendizado Não-Supervisionado (Unsupervised Learning): Neste caso, algoritmos exploram conjuntos de dados sem rótulos para identificar padrões, estruturas ou agrupamentos intrínsecos.
Aprendizado por Reforço (Reinforcement Learning): Este é um tipo de aprendizado em que um agente autônomo aprende a melhorar seu comportamento interagindo com seu ambiente e recebendo um feedback na forma de recompensas ou penalidades Sutton (1999). O agente deve aprender a escolher as ações que maximizam a recompensa ao longo do tempo.
O ML oferece vastas oportunidades de aplicação em diversas áreas do conhecimento. No campo das finanças, em particular, houve um aumento significativo na adoção de ML ao longo da última década, conforme atestam Warin & Stojkov (2021) que apresentam uma detalhada revisão bilbliográfica, fornecendo uma ampla visão do estado da arte na área. Em outras áreas, como a saúde, técnicas de ML são empregadas na identificação de doenças cardiovasculares (Johan et al, 2024). No campo da educação, ML auxilia na previsão do abandono universitário, possibilitando intervenções direcionadas para aumentar a retenção de estudantes (Tito et al, 2023). E até mesmo para predição de tendências de furto (Ordóñez et al., 2020).
Assim, a motivação para estudar aplicações de ML na cobrança de dívidas seria para mostrar lacunas de pesquisa e as possibilidades de personalizar negociações, refinando táticas de comunicação. O ML pode ser aplicado em todas as etapas do ciclo de crédito e cobrança do cliente, abrangendo desde a prospecção até a recuperação de dívidas, mas os estudos começam a explorar essas técnicas, de forma ainda embrionbária, conforme este artigo irá mostrar.
Este artigo procura trazer uma visão do estado da arte das pesquisas com aplicações de ML nas operações de cobranças de dívidas, e isto é feito, por meio de uma revisão sistemática da literatura (RSL), baseada na metodologia PICO (PAI et al., 2004). Busca-se compreender as motivações para a adoção de soluções baseadas em ML, o contexto no qual são utilizadas, os métodos de implementação, os algoritmos empregados, as métricas de avaliação de performance utilizadas, bem como as conclusões e avanços obtidos na interpretação dos resultados.
Além desta seção de introdução, tem-se no artigo, a seção 2, com a descrição da metodologia da pesquisa, e a seção 3 apresentando o desenvolvimento da RSL e os resultados obtidos. Na seção 4, tem-se uma discussão e análise dos resultados. E a seção 5, contém as considerações finais e recomendações do estudo.
2. Métodos e Materiais
O procedimento metodológico adotado para este estudo é o RSL Esta escolha se fundamenta em sua capacidade de empregar uma metodologia rigorosa e bem definida, que possibilita a identificação, análise e interpretação de pesquisas pertinentes à questão de pesquisa específica, como delineado por Kitchenham (2004). O MSL é uma ferramenta valiosa para investigar a literatura existente e aprofundar a compreensão das aplicações de técnicas de ML na cobrança de dívidas.
O protocolo metodológico seguido neste estudo está em conformidade com as diretrizes estabelecidas por kitchenham e Charters (2007), que delineiam um processo estruturado em três macro etapas essenciais: Planejamento, Condução do Mapeamento e Divulgação dos Resultados. Esse enfoque metodológico fornece um arcabouço sólido para conduzir uma análise sistemática e abrangente da literatura relevante a fim de responder às questões de pesquisa estabelecidas.
A seguir é apresentado o planejamento da RSL e depois a condução da busca nas bibliotecas digitais selecionadas.
2.1. Planejamento da RSL
O primeiro passo na elaboração desta RSL foi a definição do objetivo de pesquisa, que consiste em identificar na literatura científica estudos primários que proponham a aplicação de técnicas de ML nas operações de cobrança de dívidas. Além disso, busca-se compreender a forma como esses estudos foram conduzidos e os resultados obtidos com suas aplicações. Para atingir esse objetivo claramente definido, foram formuladas seis questões de pesquisa (QP) que direcionam a investigação:
QP1: Quando e onde os estudos foram publicados?
QP2: Quais são os principais objetivos das pesquisas desenvolvidas?
QP3: Em quais subcampos do ML as abordagens se inserem?
QP4: Quais frameworks metodológicos foram utilizados nos estudos?
QP5: Quais algoritmos são predominantemente utilizados nas pesquisas?
QP6: Quais métricas são empregadas para avaliação de desempenho das técnicas de ML?
A próxima etapa deste estudo abordará detalhadamente a estratégia e os métodos empregados na busca por trabalhos que possam responder a essas questões de pesquisa de maneira abrangente e rigorosa.
2.2. Condução da Busca por Obras na Literatura
Para a compilação dos estudos primários que compõem esta RSL, foram conduzidas pesquisas nas seguintes bibliotecas digitais nessa sequência de busca: Scopus, IEEE Xplore Digital Library e ACM Digital Library; adicionalmente, uma busca manual em português foi realizada na biblioteca digital da Sociedade Brasileira de Computação (SOL-SBC).
Neste estudo, a definição das palavras-chave seguiu a metodologia do protocolo PICO (PAI et al., 2004), uma abordagem estruturada que divide a questão de pesquisa em quatro elementos fundamentais:
P (População): "debt collection";
I (Intervenção): "machine learning," "unsupervised learning," "supervised learning," "reinforcement learning";
C (Comparação): Não se aplica (foco exclusivo em ML);
(Saída): descrição dos resultados dos estudos.
Para ajustar a estratégia de busca, foram realizados vários testes em cada um dos mecanismos de busca mencionados, com o objetivo de desenvolver uma string de busca que fornecesse resultados mais adequados, em consonância com as questões de pesquisa estabelecidas. A cada teste executado, uma análise minuciosa dos primeiros 10 resultados foi realizada, a fim de verificar se os títulos, resumos e palavras-chave estavam alinhados com o escopo da pesquisa.
A Tabela 1 apresenta as strings de busca ou equações de busca, utilizadas em cada uma das bibliotecas eletrônicas. Essas strings foram aplicadas nos campos de título, resumo e palavras-chave dos estudos, garantindo uma abordagem abrangente na identificação de trabalhos pertinentes para a revisão sistemática.
Tabela 1 String de busca por Biblioteca
| Biblioteca | String de Busca |
|---|---|
| SCOPUS | TITLE-ABS-KEY ( ( debt collection ) AND ( machine learning OR unsupervised learning OR supervised learning OR reinforcement learning ) ) |
| IEEE Xplore e ACM | ( (debt collection) AND (machine learning OR unsupervised learning OR supervised learning OR reinforcement learning) ) |
| SOL | ( ("cobrança de dívidas") AND ("aprendizado de máquina" OR "aprendizado não supervisionado" OR "aprendizado supervisionado" OR "aprendizado por reforço") ) |
3. Desenvolvimento da RSL e Resultados
Na fase de seleção dos estudos primários, foram estabelecidos inicialmente, critérios de Inclusão (I) e Exclusão (E) de estudos na seleção, de forma a selecionar aqueles de interesse na pesquisa. A Tabela 2 apresenta os critérios estipulados:
Tabela 2 Critérios de Inclusão e Exclusão de Estudos na Seleção
| Critérios | Descrição |
|---|---|
| I-1 | Trabalho em Idioma inglês e português |
| I-2 | Artigo disponível para download |
| I- 3 | Trabalhos que abordarem técnicas de ML na cobrança de dívidas |
| I- 4 | Trabalhos científicos completos publicados em veículos submetidos a revisão por pares |
| E-1 | Estudo não disponível em inglês ou português |
| E-2 | Artigo não disponível para download (acesso não gratuito), por impedir a leitura completa |
| E-3 | Artigo duplicado em mais de um mecanismo de busca |
| E-4 | Estudos que não abordarem técnicas de ML na cobrança de dívidas |
Após a aplicação dos critérios de inclusão e exclusão, foi definida nova fase, com dois critérios para avaliar a Qualidade dos Estudos primários que haviam sido selecionados na fase anterior:
Critério de Qualidade 1: O estudo responde a alguma questão da pesquisa.
Neste critério que trata das questoes de pesquisa, todo os tipos de estudo foram considerados: teóricos, aplicações e estudos de caso.
Critério de Qualidade 2: É artigo publicado em conferência ou periódicos?
Após a definição do protocolo de mapeamento, a estratégia de busca foi aplicada nas bibliotecas eletrônicas e bases de dados indexadas, SCOPUS, IEEE e ACM, em 20 de abril de 2023. Além disso, uma busca foi realizada na base nacional SBC-SOL. Um total de 41 artigos foi o retorno obtido.
A Tabela 3 apresenta uma síntese da busca por biblioteca digital, e a tabela 4, apresenta a relação dos artigos finais selecionados para revisão. Alguns resultados eram duplicados em mais de um mecanismo de busca por isso a coluna “Publicações Duplicadas”, na tabela 3. Uma vez identificados esses artigos, o processo da RSL teve sequência em duas etapas de seleção.
Tabela 3 Síntese da Busca de Estudos na Literatura
| Biblioteca | Publicações Localizadas | Publicações Duplicadas | Publicações Selecionadas |
|---|---|---|---|
| SCOPUS | 19 | 1 | 13 |
| IEEE | 8 | 6 | 0 |
| ACM | 14 | 0 | 4 |
| SOL | 0 | 0 | 0 |
| Total | 41 | 7 | 17 |
Tabela 4 Estudos Primários Selecionados
| ID | Ano | Título | Autores |
|---|---|---|---|
| A1 | 2022 | A machine-learning approach towards solving the invoice payment prediction problem | Schoonbee, L. and Moore, W.R. and van Vuuren, J.H. |
| A2 | 2022 | Deep learning for modeling the collection rate for third-party buyers | Nazemi, A. and Rezazadeh, H. and Fabozzi, F.J. and Höchstötter, M. |
| A3 | 2021 | Applying Machine Learning to Improve Collection and to Reduce Write-Offs in Utilities | Nascimento, B.S. and Maia, D. and Almada, L. |
| A4 | 2021 | Predicting Accounts Receivable with Machine Learning: A Case in Malaysia | Ramanei, T.A.-P. and Abdullah, N.L. and Khim, P.T. |
| A5 | 2020 | Detection of Taxpayers with High Probability of Non-payment: An Implementation of a Data Mining Framework | Placencia, J.O. and Hallo, M. and Lujan-Mora, S. |
| A6 | 2020 | Using Behavioral Analytics to Predict Customer Invoice Payment | Bahrami, M. and Bozkaya, B. and Balcisoy, S. |
| A7 | 2020 | Personalizing Debt Collections: Combining Reinforcement Learning and Field Experiment | Yang, Tracy; Lu, Tian; Li, Beibei; and Xianghua, Lu |
| A8 | 2015 | A study on deliberate presumptions of customer payments with reminder in the absence of face-to-face contact transactions | Takahashi, M. and Azuma, H. and Tsuda, K. |
| A9 | 2014 | A study on effect evaluation of payment method change in the mail-order industry | Takahashi, M. and Azuma, H. and Tsuda, K. |
| A10 | 2008 | Using Predictive Analysis to Improve Invoice-to-Cash Collection | Zeng, Sai and Melville, Prem and Lang, Christian A. and Boier-Martin, Ioana and Murphy, Conrad |
| A11 | 2010 | Optimizing Debt Collections Using Constrained Reinforcement Learning | Abe, Naoki and Melville, Prem and Pendus, Cezar and Reddy, Chandan K. and Jensen, David L. and Thomas, Vince P. and Bennett, James J. and Anderson, Gary F. and Cooley, Brent R. and Kowalczyk, Melissa and Domick, Mark and Gardinier, Timothy |
Na primeira etapa da RSL, os critérios de inclusão e exclusão foram aplicados por meio da leitura dos títulos, análise dos resumos e palavras-chave, e nessa etapa 24 artigos foram excluídos, sendo 7 por serem publicações duplicadas, 13 por não abordarem técnicas de ML na cobrança de dívidas e 4 por não estarem disponíveis para download, restando, assim, 17 artigos, e que, por sua vez, geraram 11 artigos finais (tabela 4), selecionados na fase seguinte, de avaliação da Qualidade dos Estudos. Note-se que os 17 artigos selecionados na primeira fase de Inclusão/Exclusão, já passaram por leitura completa.
Na segunda fase, correspondente à avaliação da qualidade dos estudos, os artigos deveriam cumprir aos critérios de qualidade definidos, e se um artigo atendesse aos critérios estipulados, era incluído na seleção final. Desta segunda fase, resultaram os 11 artigos finais da tabela 4.
Aqui é importante considerar que, conforme mostra a primeira coluna da tabela 3, 41 artigos representam todas as obras que foram encontradas sobre o tema em quatro das principais bibliotecas digitais existentes. E note-se que as strings de busca procuraram ser abrangentes para que tivessem o maior alcance possível. E dentro desse nível de abrangência, a busca trouxe 41 papers, que representam, segundo a busca, todas as pesquisas relatadas na literatura, publicadas nessas bibliotecas. Assim, pode-se considerar que os resultados são representativos do que vem sendo estudado e pesquisado nesse campo do conhecimento, que aparentemente, pelos números obtidos, não é um tema que tem chamado a atenção dos pesquisadores, constituindo-se desta forma, em uma lacuna de pesquisa a ser explorada.
4.Discussão e Análise dos Resultados
Esta seção fornece uma visão mais crítica dos resultados obtidos a partir da condução da RSL, e destaca a variedade de abordagens e técnicas utilizadas nos estudos selecionados. Essa análise contribui para a compreensão do estado da arte no uso de ML nas operações de cobrança de dívidas e demonstra a diversidade de estratégias adotadas para abordar os desafios nesse campo de pesquisa. A discussão e análise dos resultados estão organizadas de acordo com as questões de pesquisa pré-definidas.
Inicialmente, é dada uma visão geral dos artigos selecionados na fase final (tabela 6) e na sequência são apresentadas as respostas às questões de pesquisa.
4.1. Visão Geral dos Estudos Primários Selecionados
Dentre os 11 artigos analisados, seis deles abordam o problema de previsão de pagamento de faturas, que é um desafio comum na fase inicial da cobrança. Os artigos A1 (Schoonbee et al., 2022), A3 (Nascimento et al., 2021), A4 (Ramanei et al., 2021), A5 (Placencia et al., 2020), A6 (Bahrami et al., 2020) e A10 (Zeng et al., 2008), abordam esse problema e propõem soluções baseadas em ML. Estes artigos fazem uso de algoritmos como DT - Decision Tree, RF - Random Forest, LR - Logistic Regression, dentre outros.
No artigo A1 (Schoonbee et al., 2022), os autores propuseram um sistema de suporte à decisão (Decision Support System - DSS) para prever o comportamento de pagamento do cliente em relação às faturas emitidas em uma empresa na África do Sul.
Foram testados 6 diferentes tipos de algoritmos e para avaliação de desempenho os autores optaram por utilizar a curva ROC (Receiver Operating Characteristic) que demonstra a eficiência de um modelo em distinguir entre duas classes possíveis. Neste caso, a métrica utilizada foi a área abaixo da curva ROC (AUC - Area under the Curve), que varia entre 0 e 1, e quanto mais próximo de 1 melhor o desempenho do modelo. Dentre os modelos testados, o RF apresentou o melhor resultado, com AUC acima de 79%.
Já no artigo A3, Nascimento et al. (2021) discutem a cobrança de dívidas no setor público no Brasil, propondo a implementação de um framework. O objetivo era criar modelos de pontuação de predição de inadimplência, pagamentos espontâneos, e pagamento por resposta a ações de cobrança. Dentre os algoritmos testados, os autores utilizaram uma abordagem de comitê de algoritmo, que visa melhorar o desempenho de classificação.
O estudo apresentou resultados satisfatório de acordo com os autores, com uma AUC de 92% e Precisão de 86,96% para propensão de pagamento nos próximos 30 dias (semelhante resultados para os próximos 60 e 90 dias).
No artigo A4, Ramanei et al. (2021), também discutem o problema de previsão de pagamento de faturas em uma empresa na Malásia. A metodologia utilizada fez uso do framework metodológico, CRISP-DM DM (Cross-Industry Standard Process for Data Mining), desenvolvido por Shearer (2000). e testou os algoritmos DT e RF. Utilizou o nível de acurácia dos resultados para avaliar a capacidade de acerto dos modelos. Os resultados de desempenho entre os modelos foram muito parecidos, e o autores optaram por selecionar o algoritmo DT, pois as regras da árvore de decisão (decision tree) são facilmente interpretadas em comparação com o RF.
Já no artigo A5, Placencia et al. (2020) propõem um framework também baseado no CRISP-DM com o objetivo de prever dívidas de contribuintes de uma empresa no Equador com alta probabilidade de inadimplência utilizando técnicas de deep learning (DL). A métrica utilizada para medir o desempenho do modelo, foi o índice de concordância. O modelo final apresentou desempenho de 90%.
Bahrami et al. (2020), artigo A6, tinham como objetivo entender o comportamento do cliente em relação aos pagamentos de faturas e propor uma abordagem analítica para aprender e prever o comportamento de pagamento utilizando técnicas não supervisionadas e supervisionadas de ML. No framework desenvolvido, os autores propuseram diferentes abordagens para prever inadimplência. Uma das abordagens por exemplo, utilizava de algoritmos não supervisionados (K-Means e DBSCAN - Density-based Spatial Clustering of Applications with Noise) para agrupamento de dados (clustering), criando grupos de clientes, para só depois ser feita a criação dos modelos de classificação de dados, para cada grupo utilizando três abordagens de ML supervisionado: LR, Support Vector Machine (SVM) e One Rule (OneR). Foram utilizadas as métricas de AUC e Precisão para avaliar a capacidade preditiva dos modelos. Os resultados da regressão logística forneceram até 97% de precisão com ou sem pré-agrupamento de clientes.
No artigo A10, Zeng et al. (2008) demonstraram como o aprendizado supervisionado pode ser usado para construir modelos para prever os resultados de pagamento de faturas recém-criadas em quatro empresas nos Estados-Unidos. O algoritmo DT, do tipo C4.5 apresentou o melhor desempenho de acordo com a métrica acurácia.
Os autores puderam demonstrar por meio de simulação, que criação de um modelo preditivo para estimar a probabilidade de atraso no pagamento da fatura baseada no modelo de ML contribui para reduzir a inadimplência.
Em relação aos estudos analisados com foco na personalização da cobrança utilizando técnicas de ML foram identificados três artigos: A7 (Yang et al. 2020), A8 (Takahashi et al. 2015) e A9 (Takahashi et al. 2014), tem-se que em Takahashi et al. (2015), artigo A8, os autores investigaram as características dos clientes que geravam efeitos de lembrete na indústria de pedidos por correio, com ênfase nos clientes devedores. Até então, as investigações se concentravam em dados como endereço de entrega, nome do destinatário e método de pagamento, e a previsão desse conhecimento dependia das experiências dos funcionários. Para preencher essa lacuna, os autores analisaram dados de transações em conjunto com informações de clientes inadimplentes de uma empresa de pedidos por correio no Japão, utilizando a técnica Self Organizing Maps (SOM), um tipo especial de RNA de aprendizado não supervisionado. Os resultados da análise permitiram a identificação de potenciais transações fraudulentas e a classificação de clientes intencionais e descuidados por meio de ML.
Em outro estudo desses autores Takahashi et al. (2014), artigo A9, realizaram a classificação de clientes inadimplentes com base nos registros de transações de uma empresa de venda de cosméticos por correios. O foco estava na mudança do método de pagamento. A análise revelou que a frequência de inadimplência aumentava à medida que o intervalo entre os pedidos era reduzido, e dependendo do montante financeiro dos pedidos. Foi conduzida uma pesquisa intensiva para identificar os clientes inadimplentes usando novamente a técnica SOM. Os resultados demonstraram que os clientes inadimplentes podiam ser detectados por meio da identificação de parâmetros específicos.
Yang et al. 2020, no artigo A7, desenvolveram um estudo no contexto de cobrança de dívidas de empréstimos, onde os cobradores geralmente fazem uso de ações baseadas em informações privadas e seguem uma estratégia de cobrança sequencial estrita. O estudo aplicou o aprendizado por reforço para otimizar a estratégia de cobrança. Um experimento de campo ajudou a validar e quantificar o valor econômico do algoritmo de otimização em um contexto do mundo real.
4.2. Respostas às Questões de Pesquisa
As QPs são respondidas nesta subseção na mesma sequência em que foram propostas.
QP1: Quando e onde os estudos foram publicados?
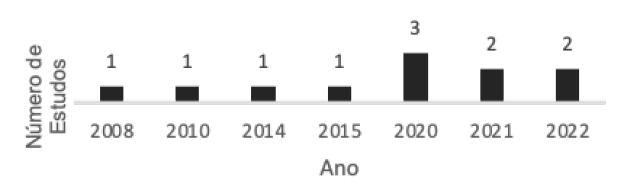
A partir da análise dos 11 estudos primários, observa-se que o primeiro estudo foi publicado em 2008. No entanto, o ano de 2020 se destaca, com três publicações realizadas. A Figura 2 apresenta a distribuição dos estudos ao longo dos anos.
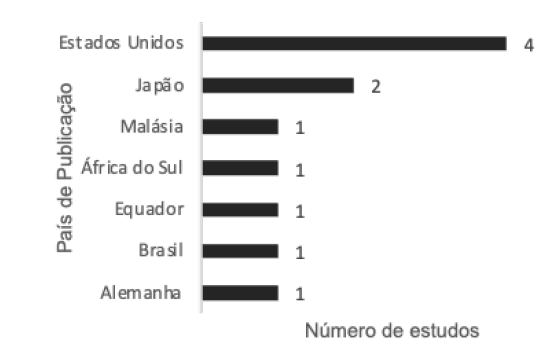
Na Figura 1, é possível verificar a distribuição dos estudos por país de origem dos autores. Os Estados Unidos se destacam, com quatro estudos publicados, seguidos pelo Japão, com dois estudos. Os demais países apresentam apenas um estudo publicado. Notavelmente, o Brasil contribui com apenas um estudo, indicando que a pesquisa sobre o uso de ML na cobrança de dívidas ainda é incipiente no cenário brasileiro, especialmente considerando bases de dados em língua portuguesa.
QP2: Quais são os objetivos primordiais das pesquisas desenvolvidas?
Conforme salientado na seção anterior, seis artigos abordaram o problema de previsão de pagamento de faturas, propondo soluções baseadas em ML. São os artigos: A1 (Schoonbee et al., 2022), A3 (Nascimento et al., 2021), A4 (Ramanei et al., 2021), A5 (Placencia et al., 2020), A6 (Bahrami et al., 2020) e A10 (Zeng et al., 2008). E sobre a personalização da cobrança utilizando técnicas de ML foram identificados três artigos: A7 (Yang et al. 2020), A8 (Takahashi et al. 2015) e A9 (Takahashi et al. 2014).
A tabela 5 revela esse quadro, em que que a previsão de inadimplência é o objetivo central na aplicação de ML na cobrança de dívidas, abordado em 6 dos 11 artigos selecionados. Em seguida, soluções para personalização da cobrança são abordadas em 3 dos 11 artigos. Aplicações para previsão de recuperação de dívidas e otimização das ações de cobrança são temas de 1 estudo cada.
Tabela 5 Objetivos das Aplicações de ML em Cobrança
| Aplicações | Número de Artigos |
|---|---|
| Previsão de inadimplência | 6 |
| Personalização das ações de cobrança | 3 |
| Previsão de recuperação de dívidas | 1 |
| Otimização de ações cobrança | 1 |
| Total | 11 |
QP3: Em que subcampos do ML as abordagens se inserem?
Os trabalhos analisados abrangem uma variedade de subcampos do ML, no entanto, o aprendizado supervisionado é o subcampo mais comumente aplicado, sendo utilizado em 7 dos 11 artigos selecionados (tabela 6).
Tabela 6 Campos de ML dos estudos
| Campos do ML | Número de Artigos |
|---|---|
| Aprendizado Supervisionado | 7 |
| Aprendizado Não Supervisionado | 2 |
| Aprendizado por Reforço | 2 |
| Total | 11 |
QP4: Quais frameworks metodológicos foram utilizados nos estudos?
Nos estudos selecionados, a metodologia CRISP-DM (Cross-Industry Standard Process for Data Mining) foi utilizada em 3 dos 11 artigos utilizados (A1, A4 e A5). O CRISP-DM é um modelo de processo para análise e modelagem de dados, desenvolvido por Shearer (2000). Essa metodologia possui seis etapas: compreensão do negócio, entendimento e preparação dos dados, modelagem, avaliação e implantação.
A abordagem da CRISP-DM é iterativa e cíclica, o que significa que as etapas não são estritamente lineares. Essa flexibilidade é uma das razões pelas quais a metodologia CRISP-DM é tão popular: ela se adapta bem a projetos de ciência de dados que frequentemente envolvem descobertas e mudanças ao longo do processo. Foram identificados 4 estudos (A3, A6, A9 e A10) onde os autores criaram frameworks, propondo etapas de pré-processamento, criação e seleção de atributos, e avaliação dos modelos. Os demais artigos não abordaram de frameworks metodológicos.
QP5: Quais algoritmos são predominantemente utilizados nas pesquisas?
Os algoritmos explorados em cada artigo são apresentados na tabela 7.
Tabela 7 Algoritmos Explorados nos Estudos Primários Selecionados
| ID | Ano | Algoritmos Utilizados |
|---|---|---|
| A1 | 2022 | RF, DT, KNN - K-Nearest Neighbor, LR, NB, ANN |
| A2 | 2022 | SVR - Support Vector Regression, DNN - Deep Neural Network ou DL - Deep Learning; Boosting com GBT - Gradient Boosted Trees, LR - Linear Regression, RT - Regression Tree |
| A3 | 2021 | RF, XGBoost - Xtreme Gradient Boosting, LightGBM - Light Gradient Boosting Machine, CatBoost - Category Boosting, ET - Extremely Randomized Trees ou Extra Trees; LR; NB; ANN-MLP - Multilayer Perceptron, DL ou Deep MLP |
| A4 | 2021 | DT e RF |
| A5 | 2020 | DL |
| A6 | 2020 | LR, SVM, OneR, K-means e DBSCAN |
| A7 | 2020 | CMDP - Constrained Markov Decision Process com Reinforcement Learning (RL) |
| A8 | 2015 | ANN (arquitetura SOM) |
| A9 | 2014 | ANN (arquitetura SOM) |
| A10 | 2008 | DT, GBT, LR e NB |
| A11 | 2010 | CMDP com Reinforcement Learning (RL) |
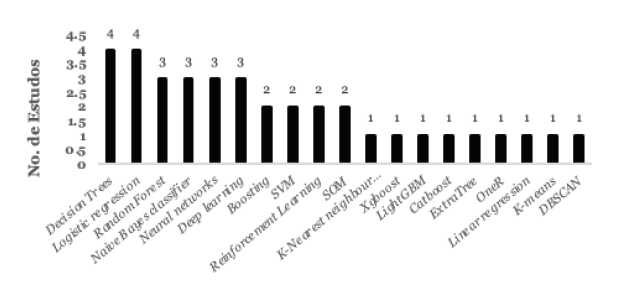
E na Figura 3 tem-se os 19 algoritmos utilizados nas aplicações de ML. Destacam-se Decision Tree (DT) e Logistic Regression (LR), utilizados em 4 estudos cada. Em seguida, Random Forest (RF), Naive Bayes (NB), Artificial Neural Network (ANN) e Deep Learning (DL) empregados em 3 artigos, respectivamente.
QP6: Quais métricas são empregadas na avaliação de desempenho das técnicas de AM?
Foram identificadas 9 métricas diferentes, com destaque para a Área sob a Curva ROC (Area Under the Curve - AUC) e a Acurácia (Accuracy), que são amplamente utilizadas em tarefas de classificação em métodos supervisionados. A AUC mede a capacidade de discriminação do modelo, sendo uma métrica que avalia a capacidade do modelo de distinguir entre classes. Quanto maior a AUC, melhor a capacidade de classificação do modelo. A Acurácia, por sua vez, mede a fração de instâncias corretamente classificadas dentre o total de instâncias recuperadas, sendo uma métrica fundamental para medir o desempenho do modelo.
A Figura 4 apresenta as métricas de avaliação de desempenho dos modelos utilizados nos estudos.

5. Considerações Finais e Recomendações
Este estudo contribuiu para uma maior compreensão do estado atual das aplicações de ML voltadas para as operações de cobranças de dívidas. Tendo-se identificado inicialmente 41 artigos associados ao tema, o número se consolidou em 11 artigos, após os filtros aplicados na RSL. Dentre as características identificadas, a predição de inadimplência foi preponderante, tendo estado presente em seis dos onze artigos analisados (54,5%). A personalização das ações de cobrança foi o segundo objetivo mais buscado (27,2%). E foram encontrados ainda, artigos que buscavam a otimização dos recursos das operações de cobranças de dívidas. Verifica-se assim, que a ênfase maior dos artigos se volta para a tentativa de modelagem do comportamento da inadimplência, o que certamente, pode ser um fator importante de apoio a decisões financeiras das empresas. Adicionalmente, foi possível identificar os algoritmos mais prevalentes nos estudos selecionados, notadamente, DT e LR.
Neste estudo, também foi possível identificar as métricas de avaliação de performance mais comuns, como: a área abaixo da curva ROC (AUC) e a Acurácia destacando-se nas tarefas de classificação de ML, enquanto a métrica Erro Quadrático Médio (MSE) figurou em dois artigos que lidavam com tarefas de regressão.
Em resumo, pelos resultados deste estudo é possível se verificar que as técnicas de ML têm o potencial de redefinir o cenário de operações de cobranças de dívidas podendo ser aplicado em todo o processo de cobrança de dívidas. Apesar dos desafios inerentes à implementação e interpretação desses modelos, os métodos de ML têm potencial de gerar resultados tão bons ou melhores que os métodos estatísticos tradicionais em determinadas aplicações, como na previsão do comportamento de clientes inadimplentes.
Além disso, tanto na condução da RSL quanto na análise dos estudos selecionados, verificou-se que existem questões de pesquisa ainda por responder, abrindo espaço para oportunidades de pesquisa futura, gerando aplicações práticas concretas. Dentre essas possibilidades de aplicações práticas, observa-se a subutilização de técnicas avançadas de Machine Learning (ML) na personalização da comunicação com devedores, aprimoramento de ofertas de desconto e identificação de horários ótimos de contato, particularmente no contexto brasileiro visando aumentar a eficiência dos processos de recuperação de dívidas.

