











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introducción
El cáncer de mama es una de las principales causas de muerte por cáncer entre las mujeres a nivel mundial, tan solo en México, entre los años 2000 y 2010 se registraron 66,405 nuevos casos de cáncer de mama, con 47,832 fallecimientos por el mismo padecimiento (Rojas et al., 2020). Esta enfermedad se presenta en mujeres adultas, principalmente en aquellas que se encuentran en la etapa posterior a la menopausia, con padecimientos como el sobrepeso y la obesidad (López y Salamanca, 2020).
Además de los factores biológicos que pueden afectar la tasa de mortalidad, también se involucran factores socioeconómicos. Se ha demostrado que los países con mayor desarrollo económico registran un alto número de incidencias en comparación con países de bajo índice de desarrollo, por otro lado, la tasa de mortalidad es menor en los países con un mayor índice de desarrollo (Garau et al., 2024).
Ante este panorama desalentador, el diagnóstico temprano y oportuno de este tipo de cáncer se vuelve muy importante, por lo que se han implementado en los últimos años campañas de detección temprana que, aunque en muchos países ha funcionado, en algunos otros como México, muchos casos aún son detectados en una etapa avanzada (López y Salamanca,2020), para la detección se han utilizado exámenes como la mastografía, el ultrasonido mamario y la biopsia de mama (Rojas et al., 2020).
Las mastografías son estudios radiológicos especializados que implican la toma de imágenes detalladas de la mama utilizando equipos de rayos X especialmente diseñados para este propósito (Lara y Olmedo, 2011). Durán et al. (2019), aseguran que los sistemas de diagnóstico computarizado (CAD) pueden ayudar a evitar los malos diagnósticos que se puedan realizar, ya que, aunque la mastografía es uno de los métodos más efectivos disponibles actualmente, su interpretación puede verse limitada por aspectos como la calidad de la imagen, el descuido humano o la vista cansada del especialista.
Es por eso que en este trabajo se presenta la realización de un sistema de clasificación de mastografías mediante el uso de un modelo de aprendizaje profundo, el modelo presentado tiene como objetivo principal realizar una clasificación de estas imágenes en dos clases diferentes de diagnósticos, benigno y maligno. El documento se organiza de la siguiente manera: la Sección 2 presenta los antecedentes y trabajos relacionados, brindando contexto para el enfoque propuesto. La Sección 3 aborda los fundamentos del aprendizaje profundo, explicando la tecnología y conceptos clave, la sección 4 describe el conjunto de datos utilizado y las muestras que contiene, en la sección 5 se explica la metodología, detallando las técnicas y modelos utilizados. En la Sección 6, se discuten los resultados de los experimentos, seguidos de un análisis de los hallazgos. Finalmente, la Sección 7 concluye el artículo, resumiendo las principales contribuciones y sugiriendo posibles direcciones para futuras investigaciones.
2. Trabajos relacionados
Debido a que el diagnóstico temprano del cáncer de mama es fundamental para mejorar las tasas de supervivencia, múltiples autores han explorado nuevas tecnologías para abordar esta necesidad. Por un lado, algunos autores han desarrollado modelos con bases de datos de características de pacientes diagnosticados, por ejemplo, Castrillón et al. (2018) propusieron un método predictivo para detectar el cáncer de mama basado en variables como edad, peso, talla, índice de masa corporal, entre otras. Utilizando un sistema de clasificación bayesiano que registró un porcentaje de aciertos del 100% en la detección de la enfermedad. De la misma forma se han utilizado métodos de clasificación como redes neuronales, bosques aleatorios y máquinas de soporte de vectores para clasificar tumores benignos y malignos, evaluando la capacidad predictiva con matrices de confusión y curvas ROC, destacando que la máquina de soporte de vectores muestra una exactitud de pronóstico superior al 99% (del Castillo, 2020). Además, Quiroz y Rivas (2018) han propuesto un modelo de decisión bayesiano automático con el fin de cuantificar el riesgo de cáncer de mama y calcular las consecuencias de las alternativas de tratamiento usando una base de datos con información de 328 pacientes con 184 casos positivos, también se tiene un precedente del desarrollo de una herramienta de software que utiliza un clasificador de bosques aleatorios, el cual presentó una exactitud del 84% (Pérez et al., 2022). Por otra parte, una de las técnicas más populares con las que se realizan modelos de clasificación para esta patología son las CNN, se han utilizado para la clasificación de mastografías en las tres clases; benignos, malignos y sanos, realizando el desarrollo en dos fases, la primera el preprocesamiento de las imágenes obteniendo las regiones de interés, para posteriormente extraer las características pertinentes en una segunda fase. Cada autor ha implementado esta técnica con algunas variantes, con lo que han obtenido resultados diferentes. Durán et al. (2019) implementaron esta metodología con un conjunto de datos de 80,500 imágenes con lo que obtuvieron un modelo con una precisión del 80%, mientras que Saldaña (2022) usando información de un total de 114 pacientes de los cuales el modelo construido solo clasificó 3 de forma incorrecta, obtuvo una precisión del 96%. En cambio, un modelo desarrollado con la misma metodología, pero entrenado con dos conjuntos de datos distintos y evaluado con el método del área bajo la curva (AUC por sus siglas en inglés) presento un AUC de 0.9838 y 0.9773 respectivos a cada conjunto de datos (Celis et al., 2022). De manera similar, en un trabajo donde se aplicaron dos estructuras diferentes de redes neuronales convolucionales, se logró una precisión del 86.05% en una arquitectura de las tres categorías, mientras que en la configuración con dos redes neuronales en secuencia que clasificaban en dos categorías cada una, primero entre normal y anomalías para después clasificar las anomalías entre benigno y maligno, se obtuvo una precisión del 88.2% (López, J.D., 2020). De manera similar en un trabajo se utilizó un modelo de CNN entrenado con el dataset Digital Database for Screening Mammography (DDSM) para clasificar mastografías digitales en cinco clases distintas: sin anomalías, con masas tumorales benignas, con masas tumorales malignas, con microcalcificaciones benignas o con microcalcificaciones malignas obteniendo una precisión del 75% (González-Bueno et al., 2015). Asimismo, Chanampe et al. (2019) entrenaron una red neuronal convolucional profunda para clasificar siete clases, calcificación, masas bien definidas, masas espículadas, otras masas mal definidas, Distorsión Arquitectónica, Asimetría y Normal, usando un dataset de solo 322 imágenes con lo que obtuvieron una precisión del 62%. Además, en varios estudios (Cano y Cruz, 2018; Agudelo y Harold, 2021), se han utilizado modelos de CNN para realizar una clasificación de cáncer de mama mediante el análisis de imágenes de histopatología, que son imágenes obtenidas a partir de muestras de tejido utilizadas para detectar patologías.
Se han presentado los trabajos relacionados en los cuales se aborda el uso de técnicas computacionales para la clasificación del cáncer de mama, destacando que en algunos trabajos se utilizan conjuntos de datos de características de los pacientes, mientras que otras investigaciones se deciden por utilizar las mastografías para extraer información y clasificar el diagnostico como benigno o maligno utilizando las redes neuronales convolucionales.
3. Aprendizaje profundo.
El aprendizaje profundo, también conocido como "Deep learning" en inglés, es una subrama del aprendizaje automático (machine learning) que se enfoca en el entrenamiento de algoritmos llamados redes neuronales artificiales en conjuntos de datos grandes y complejos haciendo uso de las capas ocultas (Guerrero y Tendilla, 2022). Se ha utilizado en una variedad de aplicaciones, como la detección de objetos en imágenes, el reconocimiento de voz y la identificación de patrones en grandes conjuntos de datos por medio de técnicas como las redes neuronales recurrentes (RNN por sus siglas en inglés), el perceptrón multicapa y las redes neuronales convolucionales (Díaz, 2021). El perceptrón multicapa consta de al menos tres capas de neuronas, la capa de entrada en las que las neuronas representan las características de los datos que se ingresan, las neuronas de las capas ocultas que realizan las operaciones de funciones de activación y generalmente son una o dos capas, y la capa de salida que procesa el resultado de la clasificación (Toro y Lizarazo, 2012). Por otro lado, las RNN utilizan una estructura similar, pero tienen conexiones retroalimentadas, lo que significa que las salidas de las neuronas se pueden utilizar como entradas en pasos de tiempo posteriores por lo que resultan útiles en tareas como el procesamiento del lenguaje natural y la traducción automática (Arana, 2021). Por último, Jiménez et al. (2023) y Rangel et al. (2019) definen las CNN como un tipo de red neuronal especialmente diseñado para procesar imágenes, y que se caracteriza por el uso de: capas convolucionales, las cuales aplican filtros convolucionales que se deslizan sobre la entrada y realizan operaciones de convolución para extraer características importantes de los datos; Núñez (2016) agrega que las capas de agrupación (pooling), reducen la dimensionalidad de los mapas de características al resumir localmente regiones de la entrada; y capas completamente conectadas que combinan las características extraídas en las capas anteriores y produce la salida final de la red.
4. Descripción del conjunto de datos.
Para este trabajo se seleccionó un dataset público que se encuentra disponible en el sitio Kaggle (Adithya, 2020), las imágenes están organizadas en dos clases: benigno y maligno como se muestra en la Figura 1. El dataset contiene 9016 imágenes en total con un tamaño promedio de 500 x 500 pixeles en un formato png, entre estas se encuentran múltiples imágenes de mastografías presentes en el dataset, la Tabla 1 muestra en conjunto de datos.
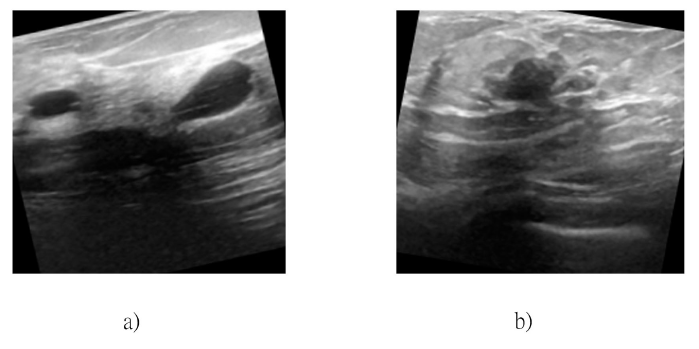
Tabla 1 Estructura original del dataset seleccionado.
| Clase | Elementos | Formato |
|---|---|---|
| Benigno | 4574 | PNG |
| Maligno | 4442 | PNG |
| Total: | 9016 |
Para preparar el conjunto de datos para el análisis, se realizó un tratamiento previo que consistió en normalizar las imágenes mastográficas. Primero, se seleccionaron las imágenes mastográficas eliminando leyendas y se convirtieron a escala de grises. Posteriormente, se ajustaron a un tamaño cuadrado de 500 píxeles por 500 píxeles. Este proceso de normalización asegura que todas las imágenes tuvieran las mismas dimensiones y características, lo que facilita su procesamiento y análisis en la red neuronal convolucional, con el fin de mejorar la eficiencia y precisión del modelo en la clasificación, la información del dataset resultante se muestra en la Tabla 2.
5. Metodología.
Para la clasificación de cáncer de mama en imágenes mastográficas, se propuso un modelo aprendizaje profundo compuesto por 28 capas, como se muestra en la Tabla 3. La capa de entrada recibe imágenes de 500 x 500 píxeles, que fueron previamente normalizadas y ajustadas. Después, se aplicaron capas de convolución, seguidas de capas de normalización por lotes y funciones de activación ReLU. Posteriormente, se incorporaron capas de maxpooling para reducir las dimensiones de las características extraídas. Después de estas capas, se agregó capas totalmente conectadas para procesar las características y finalmente, una capa de función de activación softmax para la clasificación multiclase. La última capa, la capa de salida, se utilizó para asignar la clase de cáncer de mama a cada imagen procesada.
Tabla 3 Estructura del modelo propuesto.
| Número | Capa | Tipo | Activación |
|---|---|---|---|
| 1 | imageinput | Image Input | 500 x 500 x 1 |
| 2 | conv_1 | Convolution | 500 x 500 x 8 |
| 3 | batchnorm_1 | Batch Normalization | 500 x 500 x 8 |
| 4 | relu_1 | ReLU | 500 x 500 x 8 |
| 5 | maxpool_1 | Max Pooling | 250 x 250 x 8 |
| 6 | conv_2 | Convolution | 250 x 250 x 16 |
| 7 | batchnorm_2 | Batch Normalization | 250 x 250 x 16 |
| 8 | relu_2 | ReLU | 250 x 250 x 16 |
| 9 | maxpool_2 | Max Pooling | 125 x 125 x 16 |
| 10 | conv_3 | Convolution | 125 x 125 x 32 |
| 11 | batchnorm_3 | Batch Normalization | 125 x 125 x 32 |
| 12 | relu_3 | ReLU | 125 x 125 x 32 |
| 13 | maxpool_3 | Max Pooling | 62 x 62 x 32 |
| 14 | conv_4 | Convolution | 61 x 61 x 64 |
| 15 | batchnorm_4 | Batch Normalization | 61 x 61 x 64 |
| 16 | relu_4 | ReLU | 61 x 61 x 64 |
| 17 | maxpool_4 | Max Pooling | 30 x 30 x 64 |
| 18 | conv_5 | Convolution | 27 x 27 x 128 |
| 19 | batchnorm_5 | Batch Normalization | 27 x 27 x 128 |
| 20 | relu_5 | ReLU | 27 x 27 x 128 |
| 21 | maxpool_5 | Max Pooling | 13 x 13 x 128 |
| 22 | conv_6 | Convolution | 10 x 10 x 256 |
| 23 | batchnorm_6 | Batch Normalization | 10 x 10 x 256 |
| 24 | relu_6 | ReLU | 10 x 10 x 256 |
| 25 | fc_1 | Fully Connected | 1 x 1 x 2 |
| 26 | fc_2 | Fully Connected | 1 x 1 x 2 |
| 27 | softmax | Softmax | 1 x 1 x 2 |
| 28 | classoutput | Classfication Output | 1 x 1 x 2 |
La extracción de características en los componentes convolucionales del modelo de aprendizaje profundo es explicada por Bonilla (2020), Primero, se aplican filtros a las imágenes de entrada para extraer características relevantes, como bordes, texturas o formas. Cada filtro produce un mapa de bio-marcadores que resalta características en la imagen. Posteriormente, las capas de normalización por lotes ajustan y normalizan las activaciones de las capas de convolución, lo que ayuda a acelerar el entrenamiento y a mejorar la generalización del modelo. Las capas ReLU introducen no linealidades al transformar las activaciones negativas en cero, permitiendo al modelo aprender relaciones más complejas y aumentando su capacidad de representación. Las capas de maxpooling reducen la dimensionalidad de los mapas de características al seleccionar el valor máximo en una región de la imagen, lo que ayuda a reducir el costo computacional y a evitar el sobreajuste al conservar las características más relevantes.
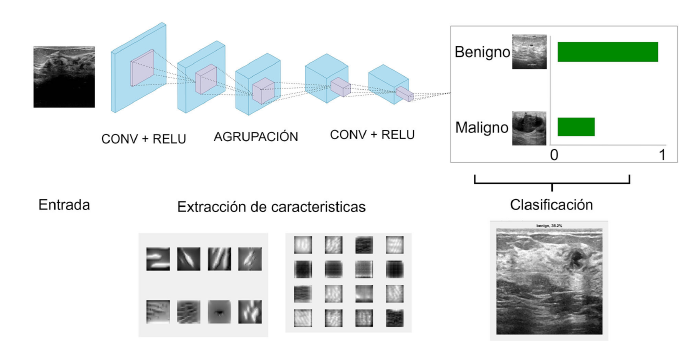
Después de las capas convolucionales y de maxpooling, las características se pasan a través de una capa totalmente conectada, que procesa las características extraídas para generar una representación final antes de la clasificación. Finalmente, la capa softmax se utiliza para la clasificación de múltiples clases, asignando probabilidades a cada clase basadas en la representación final de la imagen. La clase con la probabilidad más alta se considera la predicción del modelo para esa imagen. En resumen, el modelo propuesto, como se muestra en la Figura 2, implica la aplicación sucesiva de capas de convolución, normalización, funciones de activación ReLU, maxpooling, capas totalmente conectadas y capas softmax para producir predicciones precisas sobre la clase de la imagen de entrada.
5.1. Extracción de características.
En este modelo propuesto, las capas de convolución, max pooling y ReLU se encargan de realizar la extracción de características. El modelo tiene 6 capas de convolución, (2, 6, 10, 14, 18, 22); la capa 2 (convolución 1) recibe la imagen como entrada y genera 8 kernels de 3x3 para extraer la información. En la capa 6 (convolución 2) se obtienen 16 kernels, y 32 en la capa 10 (convolución 3), en ambos de 3x3. En la capa 14 (convolución 4) se obtienen 64 kernels de 4x4, y en las capas 18 (convolución 5) y 22 (convolución 6) el tamaño de los kernels es de 6x6, generando cada capa 128 y 256 kernels respectivamente, la Figura 3 muestra 8 kernels de cada convolución.

Figura 3 Extracción de características en las capas: a) convolución 1, b) convolución 2, c) convolución 3, d) convolución 4, e) convolución 5 y f) convolución 6.
La función ReLU transforma todos los valores negativos a cero y mantiene los valores positivos sin cambios, facilitando así el entrenamiento. El modelo cuenta con 6 capas ReLU, (4, 8, 12, 16, 20 y 24). La Figura 4 muestra algunos kernels de cada capa ReLU. La operación de max pooling se realiza dividiendo la entrada en regiones (por ejemplo, 2x2) y tomando el valor máximo de cada región, con lo que se puede conservar las características más importantes de la región, mientras se descarta información menos relevante. La Figura 5 muestra 8 kernels de cada una de las 5 capas de max pooling presentes en el modelo, (5, 9, 13, 17 y 21).

Figura 4 Extracción de características en las capas: a) ReLU 1, b) ReLU 2, c) ReLU 3, d) ReLU 4, e) ReLU 5 y f) ReLU 6.

6. Resultados.
Para el entrenamiento del modelo se utilizaron dos etiquetas “benigno” y “maligno”, estas fueron las clases en las que se organizó el dataset, que posteriormente fue dividido en dos conjuntos separados aleatoriamente, uno con el 80% de los datos para el entrenamiento y otro con el 20% de los datos para la validación, el número de muestras resultantes en cada conjunto se muestra en la Tabla 4.
Tabla 4 Conjuntos de entrenamiento y validación.
| Conjunto | Porcentaje (%) | benignos | malignos |
|---|---|---|---|
| Entrenamiento | 80 | 3259 | 3234 |
| Validación | 20 | 815 | 808 |
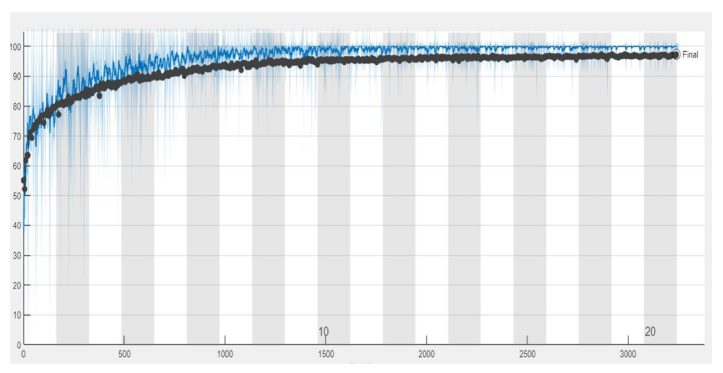
En el entrenamiento del modelo se empleó el gradiente descendente estocástico y los parámetros utilizados fueron; un tamaño de lote de 40 muestras, un máximo de 20 épocas, una tasa de aprendizaje inicial de 0.0001 y una frecuencia de validación de 6 iteraciones. Utilizando el conjunto de entrenamiento que contiene un total de 6493 imágenes, el proceso tardó 506 minutos 22 segundos, obteniendo un porcentaje de precisión de 97.35% con 3240 iteraciones realizadas en 20 épocas como se muestra en la Figura 6, estas pruebas fueron realizadas en un equipo con un GPU Intel i5 NVIDIA GeForce RTX 3050, memoria 32GB.
Para validar el desempeño del modelo se empleó una matriz de confusión para cada conjunto de datos, los resultados del conjunto de entrenamiento se muestran en la Figura 7, y los del conjunto de validación en la Figura 8, utilizando las siguientes métricas: VP (verdaderos positivos) casos benignos clasificados correctamente; VN (verdaderos negativos), casos benignos clasificados como malignos; FP (falsos positivos), casos malignos clasificados correctamente; y FN (falsos negativos), casos malignos clasificados como benignos.
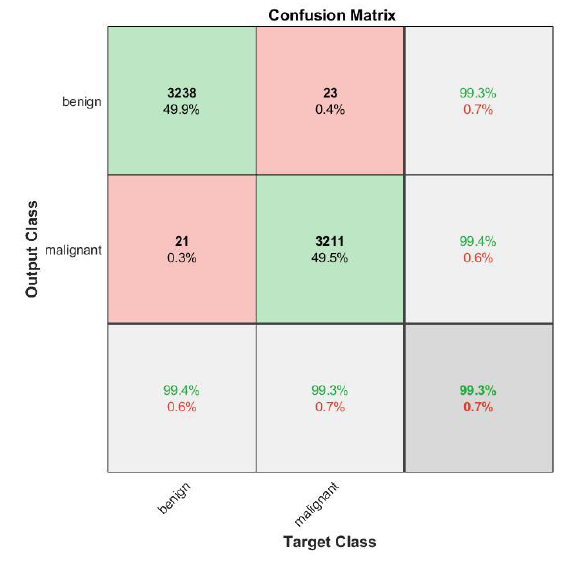
Figura 7 Matriz de confusión del reconocimiento de casos malignos de cáncer de mama con el conjunto de datos de entrenamiento, 3238 casos VP, 23 VN, 21 FN y 3211 FP, obteniendo un 99.3% de exactitud.
En el caso del conjunto de entrenamiento, cuando se obtuvo la matriz de confusión se encontraron 3238 imágenes de mastografías de la clase benigno clasificadas dentro de esta clase, por lo que fueron los casos verdaderos positivos, de igual manera se obtuvieron 3211 casos de mastografías de la clase maligno clasificadas como tal, lo que representa los casos falsos positivos, mientras que, por otra parte, 23 imágenes de la clase benigno fueron clasificadas en la clase maligno y 21 imágenes de la clase maligno fueron clasificadas en la clase benigno, estas clasificaciones representan los verdaderos negativos y los falsos negativos del conjunto de datos de entrenamiento, estas clasificaciones llevaron a un porcentaje de exactitud del 99.3%.
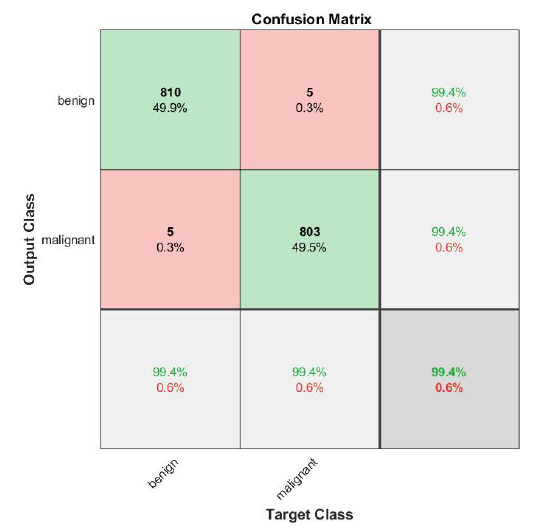
Figura 8 Matriz de confusión del reconocimiento de casos malignos de cáncer de mama con el conjunto de datos de validación, 810 casos VP, 5 VN, 5 FN y 803 FP, obteniendo un 99.4% de exactitud.
Por otra parte, en el conjunto de validación se clasificaron un total de 810 imágenes de mastografías de la clase benigno dentro de esta misma clase, representando a los casos verdaderos positivos, mientras que, para los falsos positivos que son las imágenes de la clase maligno clasificadas como tal, hubieron 803 casos, por otra parte, tanto para los verdaderos negativos y falsos negativos se obtuvieron 5 imágenes clasificadas incorrectamente para cada uno de los casos, en este conjunto de datos de validación se obtuvo un porcentaje de exactitud del 99.4%.
En la Tabla 5 se ilustran los valores obtenidos con la matriz de confusión de cada conjunto.
Además, también se calcularon la exactitud, sensibilidad y especificidad del modelo. La exactitud representa la proporción de predicciones correctas (VN + VP) sobre el total de predicciones realizadas (VN + VP + FN + FP). La sensibilidad indica la capacidad del modelo para identificar correctamente las instancias positivas, calculada como VP / (VP + FN). Por último, la especificidad muestra la habilidad del modelo para identificar correctamente las instancias negativas, calculada como VN / (VN + FP). Estos resultados se encuentran en la Tabla 6.
Tabla 6 Exactitud, Sensibilidad y Especificidad.
| Conjunto | Exactitud | Sensibilidad | Especificidad |
|---|---|---|---|
| Entrenamiento | 99.32% | 99.29% | 99.35% |
| Validación | 99.38% | 99.39% | 99.38% |
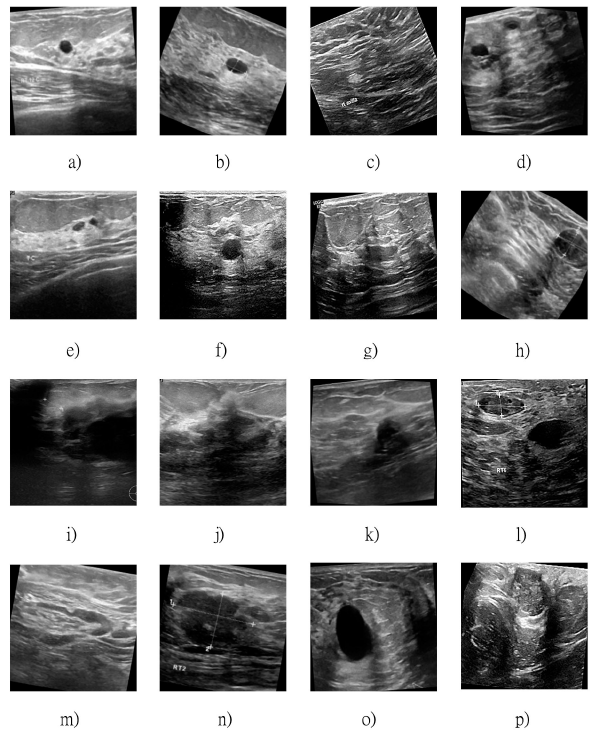
En la Figura 9, se muestra el funcionamiento del modelo entrenado, se observan 8 clasificaciones realizadas por el modelo usando el conjunto de entrenamiento.
7. Conclusiones
El diagnóstico temprano y preciso del cáncer de mama es fundamental para mejorar las tasas de supervivencia de las pacientes. En este estudio, se propuso un modelo de aprendizaje profundo para la clasificación de imágenes de mastografías en dos clases: benigno y maligno. El modelo fue entrenado y validado con un conjunto de datos público que contiene un total de 8116 imágenes normalizadas y ajustadas a un tamaño de 500 x 500 píxeles. Los resultados obtenidos muestran una alta precisión del modelo, con una exactitud del 99.3% en el conjunto de entrenamiento y del 99.4% en el conjunto de validación. Además, se calcularon otras métricas como sensibilidad y especificidad, mostrando valores altos y consistentes con la exactitud. Estos resultados indican que el modelo propuesto tiene un buen desempeño en la clasificación de imágenes de mastografías, con porcentajes de exactitud mayores que los trabajos similares mencionados en este documento (Durán et al., 2019; Saldaña, 2022; Celis et al., 2022; López, 2020). Una limitación importante de este estudio es que el modelo propuesto clasifica únicamente en dos clases: benigno y maligno. En contraste, algunos trabajos relacionados abordan la clasificación en más de dos clases, incluyendo la clase de normal (Durán et al., 2019; Saldaña, 2022; Celis et al., 2022; López, 2020), es decir, sin patología, así como la clasificación entre clases específicas como microcalcificaciones y masas espículadas (González-Bueno et al., 2015; Chanampe et al., 2019). Esta limitación puede reducir la capacidad del modelo para distinguir entre diferentes tipos de anomalías mamarias, lo que podría afectar su utilidad clínica en situaciones donde la diferenciación precisa entre diversas condiciones es crucial para el tratamiento y la gestión de la enfermedad. En futuras investigaciones, sería beneficioso explorar la posibilidad de ampliar el modelo para incluir la clasificación en múltiples clases, lo que podría mejorar su capacidad de diagnóstico y su relevancia clínica.

