











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
Introduction
Customers' opinions are paramount in today's business landscape, particularly in the hospitality industry. As companies deepen their understanding of consumer preferences and feedback's influence, this understanding becomes indispensable for ensuring business success (Sudirjo et al., 2023).
Before the 2000s, linguistics and natural language processing research rarely explored opinions and sentiments (Devika et al., 2016). However, the rise of digital platforms and the growth of online communication transformed this scenery. With the advent of the internet, especially social media and review forums (Hussein, 2018), customers have gained new ways to share their experiences, creating a vast volume of data that companies can analyze to obtain valuable insights. Applying artificial intelligence (AI) in this context through Natural Language Processing (NLP) techniques becomes crucial. NLP is a field of computer science that focuses on the interaction between computers and human language and seeks to improve the understanding and processing of human language, applying itself in areas such as language recognition, translation, and text summarization. These techniques offer meaningful insights from a vast data set, providing a deeper understanding of consumer preferences, opinions, and needs (Korkmaz et al., 2023).
Sentiment analysis, or opinion mining, is an area within NLP that automatically identifies a text's sentiment (Hoang et al., 2019) and categorizes it as positive, negative, or neutral. In its early stages, sentiment analysis was dominated by lexicon-based techniques, which involved calculating the number of positive and negative words in a text, with each word associated with a sentiment score (Oliveira et al.,2022; Carvalho et al., 2024; Kheiri & Karimi, 2023). Advances in Machine Learning (ML) algorithms have proved more effective than the techniques implemented until now. However, due to the complexity and nuances of human language, it has been necessary to refine these traditional techniques.
Sentiment analysis has been studied at various levels, including document, paragraph, sentence, and aspect (Chifu & Fournier, 2023; Wankhade et al., 2022). Initially, this analysis focused on the binary sentiment classification, usually positive or negative. However, this approach became insufficient as it was recognized that a single evaluation could express multiple feelings on different subjects, containing opinions with opposing polarities (Kontonatsios et al., 2023)
To overcome this limitation, Aspect-Based Sentiment Analysis (ABSA) emerged. This approach classifies sentiment and identifies the specific aspects to which the evaluation refers. Other methodologies, such as topic modeling, play a complementary role in extracting insights from textual data. Topic modeling, a widely used technique in natural language processing, identifies underlying themes or clusters in large datasets, providing a broader perspective on customer feedback. Studies like Aguilar-Moreno et al. (2024) have demonstrated the effectiveness of topic modeling in supporting business decision-making by categorizing unstructured data into actionable themes. While this study focuses on ABSA using ChatGPT to classify sentiments at a granular level, integrating topic modeling in future research could uncover overarching patterns, adding strategic value to sentiment analysis workflows. This study builds on ABSA by leveraging ChatGPT to address gaps in sentiment analysis, enhancing precision in handling subjectivity and nuanced language. Doing so represents an evolution in the field, enabling the extraction of more detailed information about each opinion compared to traditional approaches (Zhang et al., 2023).
ABSA addresses two main tasks: aspect detection and sentiment classification. In the aspect detection task, the aim is to identify the entities or characteristics of the text that are the subject of an opinion. This detection can be explicit, involving the analysis of linguistic patterns, or implicit, requiring a deeper comprehension. Once the aspects have been identified, the sentiment is given a classification. This approach improves the accuracy of sentiment analysis and offers more detailed insights into consumer perceptions of specific aspects (Truşcǎ, et al., 2023).
In the last decade, the field of NLP has experienced a paradigm shift due to exponential data growth and a revolution driven by remarkable advances in AI. With the rise of Large Language Models (LLMs), especially the powerful Generative Pretrained Transformer (GPT), sentiment analysis achieved substantial improvements, promoting significant advances in the automated understanding of emotions in texts (Liu et al., 2023). As LLMs gain prominence, their ability to understand and generate human language on a large scale emerges. These models are trained with large amounts of text data, allowing them to learn complex patterns and relationships in human language (Naveed et al., 2023). The remarkable development of LLMs is primarily attributed to OpenAI, which released the first GPT algorithm in 2018 (Tan et al., 2023). Since then, several versions of GPT have been released, with GPT-4o being the most recent model.
This research is driven by a continuous search for innovation and improvement in business strategy. It recognizes the need to simplify and optimize the analysis of customer reviews. This study aims to provide organizations with an efficient method for identifying overall customer sentiment and the specific aspects influencing those sentiments. To achieve this goal, the GPT-4o algorithm, through ChatGPT, will be used to automate specific tasks, such as identifying sentiments and aspects in customer reviews.
Although recent studies have shown success in classifying customer reviews using LLMs (Simmering & Huoviala, 2023), there needs to be more literature addressing the need for the use of more advanced models. To overcome this gap, this study proposes an approach using ChatGPT with a dataset of TripAdvisor hotel reviews (Rassal et al., 2023). By analyzing the performance of ChatGPT, the goal is to address gaps identified in existing literature and propose solutions for enhancing sentiment analysis and aspect identification in customer reviews. To guide this investigation, two research questions have been formulated to focus on the study's objectives:
RQ1: How can sentiment analysis leveraging Large Language Models (LLMs) enhance the capabilities of Aspect-Based Sentiment Analysis (ABSA)?
RQ2: How does the performance of an LLM-based approach to ABSA compare to a reference human analysis approach?
The methodology employed in this research combines quantitative methods with the evaluation of hotel online reviews using various approaches using the ChatGPT API (API Reference - OpenAI API, n.d.). A comprehensive literature review will be conducted to establish the theoretical foundations, focusing on aspect-based sentiment analysis. Subsequently, the ChatGPT API, using the GPT-4o model, is employed to identify aspects and categorize sentiment in reviews accurately. Following this, a detailed evaluation is conducted, employing the Similarity Coefficient within a benchmarking framework to compare three distinct approaches: a Fuzzy logic-based method (Rassal et al., 2023), the ChatGPT approach, and a Human approach.
The remainder of the paper is organized as follows. Section 2 reviews the literature, tracing the evolution of sentiment analysis from traditional methods to Aspect-Based Sentiment Analysis (ABSA), emphasizing the transformative role of Large Language Models (LLMs). Section 3 details the methodology, including dataset preparation, the design of benchmarking frameworks, and the comparative evaluation of ChatGPT’s performance against human analysis and traditional fuzzy logic-based approaches. Section 4 presents the results, offering a comprehensive analysis of findings across dimensions. Section 5 expands upon these findings with a detailed discussion, situating ChatGPT’s performance within the context of existing literature, identifying alignment and disparities with prior research, and highlighting its key contributions while discussing theoretical and practical implications. Finally, Section 6 concludes the paper by summarizing the study’s findings, acknowledging limitations, and presenting directions for future research.
2. Literature review
2.1 Aspect-Based Sentıment Analysıs
Sentiment analysis has been extensively studied across various levels (Wankhade et al., 2022), starting with analyzing entire documents. Initially, researchers focus on determining the overall sentiment of a document, aiming to discern whether it expresses positivity or negativity, commonly employing conventional machine learning methods (Kumar & Sebastian, 2012; Khalaf et al., 2022). As the analysis progresses to a more granular level, namely the sentence level, the focus shifts towards identifying opinions within individual sentences, where the goal is to differentiate between positive, negative, and neutral sentiments.
With the exponential increase in sentiment analysis, the ABSA approach, proposed in 2010 as a new framework (Thet et al., 2010), brought a more refined perspective, allowing the assessment of specific sentiments about different aspects of an entity (Wang & Liu, 2022). Further illustrating the utility of sentiment analysis in practical contexts, Aguilar-Moreno et al. (2024) highlighted its increasing role in business decision-making, integrating multicriteria decision-making and predictive algorithms to process customer feedback efficiently. These approaches address the need for refined sentiment analysis techniques to explore specific aspects and their implications. They have become essential for uncovering nuances present in various evaluations, enabling a more detailed analysis of specific aspects (Serrano-Guerrero et al., 2015).
Exploring the review "The device is expensive, but the camera is amazing," it is possible to identify an explicit aspect, "camera" (sentiment term: "amazing", polarity: positive), and an implicit aspect, "price" (sentiment term: "expensive", polarity: negative). Notably, depending on the areas being considered, these aspects can be categorized into broader categories, such as "functionality" for "camera" and "cost" for "price.”
As articulated by Liu (2012), ABSA relies on four key elements: aspect category (c), aspect term (a), opinion term (o), and sentiment polarity (p): The aspect term (a) is the target of the opinion that appears explicitly in the text provided, such as "device" in the sentence "The device is expensive". When the target is not directly indicated in the sentence (for example, "It's over budget!"), it can be considered "null" or absent. The aspect category (c) refers to the broader field or domain to which an aspect belongs. They can be predefined or extracted from the text and play a crucial role in contextualizing sentiment analysis results. Taking the previous example, the category "design" or "price" can be associated with the aspect "device", while the category "performance" or "quality" can be attributed to the aspect "camera". Opinion terms (o) can be expressed explicitly or implicitly. In an explicit expression, such as presented, the positive attitude towards the camera is clearly indicated, while the attitude towards the price is implicit in the word "expensive". Sentiment polarity (p) describes the orientation of sentiment towards a spectrum category or term, usually categorized as positive, negative, or neutral. In this context, sentiment polarity could be negative due to the expression "expensive”.
2.2 Related Work
ABSA has evolved significantly from its earliest stages to recent developments, encompassing various techniques and approaches. Initially, manual methods based on linguistic rules, such as those introduced by Hu and Liu (2004) and Pang and Lee (2004), were pioneers in this area.
While Hu and Liu (2004) opted to categorize aspects and sentiments in a lexicon, Pang and Lee (2004) explored an innovative method based on graph theory to identify and summarise subjective portions of text. However, both methods faced challenges, such as dealing with implicit aspects and the varied interpretations of sentiment.
Over time, the emergence of academic competitions, such as SemEval, stimulated innovation in ABSA. Studies conducted by Pontik et al. (2014, 2015, 2016) were crucial in this process, introducing more sophisticated approaches that addressed issues such as subjectivity detection, aspect extraction, and polarity classification in a more precise and comprehensive way. However, even with these advances, persistent challenges, such as the representativeness of the data and the generalisability of the results to different domains, persisted.
Al-Smadi et al. (2019) marked the shift to automated approaches using machine learning and neural networks, showing their effectiveness in handling data complexity and improving sentiment analysis accuracy. However, despite the notable improvements achieved by neural network models, concerns persist about their interpretability and applicability in different contexts (Rathan et al., 2018; Pham & Le 2018).
Rathan et al. (2018) proposed a model for analyzing sentiment in smartphone reviews that employ methods such as supervised learning with decision trees and Support Vector Machines (SVM). Although this contributes to classification accuracy, limitations arise due to the presence of ambiguities in the evaluations, which can affect the model's effectiveness in real-world situations. On the other hand, the model proposed by Pham and Le (2018) emphasizes the ability to represent semantic relationships in several layers. However, its specificity to the hospitality sector may limit its generalisability to other domains. In addition, the model needs to fully address implicit aspects of evaluations, causing difficulties in interpreting ambiguous or sarcastic expressions.
Mojica et al. (2024) explored the application of sentiment analysis in happiness apps, focusing on user engagement and well-being. Their findings highlighted the role of gamification in enhancing user interaction but also emphasized the methodological limitations, such as reliance on user reviews and limited clinical validation. Perea-Khalifi et al. (2024) applied sentiment analysis to P2P payment systems, identifying six latent aspects influencing user experiences, such as ease of use and perceived value. They noted that independent apps evoke more positive emotions than those associated with financial institutions, underscoring the importance of context-specific sentiment analysis.
Recent advances, such as the Transformer architecture and LLMs, have further boosted ABSA's effectiveness. The emergence of transformer models, such as GPT-3, has been essential in meeting the challenges encountered until then, offering capabilities in natural language understanding. The works by Simmering and Huoviala (2023) and Macháliková (2023) highlight the potential of LLMs by demonstrating their superiority over traditional methods, especially in large datasets and more refined sentiment analysis. However, the need for more comprehensive evaluations with diverse datasets to prove the effectiveness of these algorithms remains a point of attention.
2.3 Large Language Models
LLMs are advanced language models based on AI, falling into the category of Generative AI (Dasgupta et al., 2023). The architecture underlying the current generation of LLMs is based on transformers, a type of neural network that enables the capture of complex contexts and semantic relationships (Azam et al., 2023).
With an encoder-decoder mechanism and self-attention implementation (Vaswani et al., 2017), these models break down the text into more meaningful units, assigning dynamic weights to each term. This approach enables deep contextual understanding, and by applying this mechanism to tasks such as ABSA, LLMs can pick up on specific nuances about the aspects mentioned (Mishev et al., 2020). Considering the previously mentioned sentence, the device is expensive, but the camera is amazing, it is possible to observe how the architecture of the LLM operates. Using the self-attention mechanism, the encoder divides the sentence into meaningful units, assigning contextual weights to each term. This allows the model to identify two specific aspects: the device price and the camera performance, each with weighted relevance. During decoding, the model generates an output that classifies the sentiments associated with each aspect. Thus, even with the mention of the high cost, emphasizing the amazing camera may lead to a positive classification for this aspect. This dynamic interaction between encoder and decoder, mediated by the self-attention mechanism, allows LLMs to understand and evaluate sentiments in specific aspects.
2.4 Large Language Models In ABSA
LLMs stand out in ABSA due to their deep contextual understanding, acquired through extensive training on textual data (Liu et al., 2023). This capability enables accurate sentiment analysis of specific aspects in different contexts, from product reviews to social media posts (Azam et al., 2023). The multilingual ability of LLMs is also valuable for ABSA in global markets, where opinions can vary culturally. In addition, these models are adaptable to new domains, allowing for personalized sentiment analysis. They also stand out for their efficiency, avoiding the need for extensive readiness engineering. These models offer a robust and effective approach, enabling accurate aspect identification and efficient sentiment classification (Zhang et al., 2023).
LLMs have been extensively studied in ABSA, showcasing their versatility across various domains. In customer comment analysis on Twitter, a transfer-based ABSA model (Banjar et al., 2021) stands out in aspect polarity estimation. Additionally, transformer-based approaches like BERT and Transformer demonstrate notable advantages in government (Areed et al., 2020) and financial sectors (Mishev et al., 2020). Addition studies explore LLMs in sentiment analysis across social media (Hoang et al., 2019), restaurant reviews (Li et al., 2023), products (Ismet et al., 2022), and movies (Nkhata , 2022). Table 1 concisely summarizes the studies, including their main conclusions and limitations.
Table 1 Overview of Studies and Results
| Authors (year) | Title | Theme | Main Conclusions | Limitations |
|---|---|---|---|---|
| Hu & Liu (2004). | Mining and summarizing customer reviews | Sentiment extraction from customer reviews | Lexicon-based approach to classify customer opinions in relation to different product or service characteristics. | Difficulty in dealing with implicit aspects. Problems in dealing with feelings about subjective aspects. |
| Pang & Lee (2004) | A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts | Sentiment extraction from customer reviews | Approach based on minimum cut algorithms to identify and summarize subjective portions of text. | Uncertainty about the effectiveness of the graph-based approach in large databases and with different types of text. Obstacles due to the varied interpretation of feelings |
| Pontiki et al. (2014) | SemEval-2014 Task 4: Aspect-Based Sentiment Analysis | Sentiment extraction from customer reviews | Emphasis on subjectivity detection, aspect extraction, and polarity classification. | |
| Pontiki et al. (2015) | SemEval-2015 Task 12: Aspect-Based Sentiment Analysis | Sentiment extraction from customer reviews | Expansion of the scope to consider multiple opinions on the same aspect and cover various domains. | |
| Pontiki et al. (2016) | SemEval-2016 Task 5: Aspect-Based Sentiment Analysis | Sentiment extraction from customer reviews | Emphasis on considering cultural and linguistic contexts. | |
| Al-Smadi et al. (2019) | Using long short-term memory deep neural networks for aspect-based sentiment analysis of Arabic reviews | Aspect-based sentiment analysis of hotel reviews in Arabic | The use of bidirectional LSTMs and aspect-based LSTMs led to significant improvements compared to the baseline research. | Limited to hotel reviews in Arabic. |
| Rathan et al. (2018) | Consumer Insight Mining: Aspect Based Twitter Opinion Mining of Mobile Phone Reviews | Aspect-based sentiment analysis of smartphone reviews | The use of decision trees for aspect extraction and SVM for sentiment classification yielded promising results. Additionally, a domain-specific lexicon was employed to enhance classification accuracy. | The dataset size and ambiguous tweets may limit the model's accuracy. |
| Pham & Le (2018) | Learning multiple layers of knowledge representation for aspect based sentiment analysis. | Aspect-based sentiment analysis of hotel reviews | The use of an innovative neural network architecture with multiple layers of knowledge representation led to superior results compared to traditional methods. The interpretation of ambiguous or sarcastic expressions is not fully addressed. | The model is specific to the hotel industry and is not generalizable to other domains. |
| Simmering & Huoviala (2023) | Large language models for aspect- based sentiment analysis. | Aspect-based sentiment analysis | LLMs such as GPT3 have demonstrated superiority over traditional methods in identifying sentiments related to specific aspects. | The analysis was restricted to a single dataset. |
| Macháliková (2023) | Utilizing ChatGPT for Sentiment Analysis Title Utilizing ChatGPT for Sentiment Analysis. | Sentiment analysis based on online reviews | ChatGPT can be effective in sentiment analysis of online reviews, both for individual reviews and multiple reviews. | The study was limited to a small dataset and did not compare ChatGPT's performance with other LLMs. |
| Aguilar-Moreno et al. (2024) | Sentiment analysis to support business decision-making. A bibliometric study. | Sentiment analysis in business decisions | The study emphasizes the increasing integration of sentiment analysis methods in business decision- making, highlighting their application across various sectors and the importance of customer feedback from platforms like Twitter and Amazon | Focused on English- language studies and limited consideration of non-Western contexts and lesser- explored sectors. |
| Mojica et al. (2024) | Is there innovation management of emotions or just the commodification of happiness? A sentiment analysis of happiness apps. | Emotions in happiness apps through sentiment analysis. | •Apps improve well-being and gamification aids engagement. | Relies on user review and lacks clinical data validation. |
| Perea-Khalifi et al. (2024) | Exploring the determinants of the user experience in P2P payment systems in Spain: A text mining approach. | User experience in P2P payment apps | Identified six key aspects influencing user reviews. Independent apps evoke more positive emotions than bank-affiliated ones. | Bias toward positive reviews. |
Source: Own elaboration.
2.5 Generatıve Pre-Transformer
Following its introduction by OpenAI in 2018, one of the most widely adopted LLMs is the GPT (Raj et al., 2023). Derived from the GPT model, ChatGPT (Rudolph et al., 2023) has emerged as a versatile AI model in NLP (Amar, J. et al., 2023). It leverages the Transformer architecture to generate humanized responses in real-time conversations. Trained on vast sets of textual data, this model uses advanced deep-learning techniques to understand and generate coherent text. The model has been trained on millions of online conversations, obtaining relevant information on topic contexts.
Regarding sentiment analysis, ChatGPT has made a name for itself (Baker & Utku, 2023), offering significant advantages for businesses and organizations, enabling effective automation in understanding customer perceptions and feedback. Its ability to conduct contextual analysis contributes to a better understanding of text nuances, enabling more accurate decisions and proactive identification of trends, problems, or opportunities. By automating the analysis of large data sets, ChatGPT can provide insights into community needs and concerns, aiding informed decision-making, identifying priority intervention areas, and adapting strategies to meet community demands better (Sudirjo et al., 2023). Alongside sentiment analysis, customer service is a critical aspect for organizations such as Destination Management Organizations and hotels. ChatGPT can play a pivotal role in this field. By offering virtual support, it delivers exceptional customer service experiences by promptly addressing frequently asked questions, providing detailed information about products and services, and solving everyday problems, which reduces the need for human intervention (George et al., 2023; Yñiguez-Ovando et al. 2024).
3. Methodology
This study utilizes the dataset and builds upon the findings of Rassal et al. (2023) to benchmark the performance of Large Language Models (LLMs) in enhancing Aspect-Based Sentiment Analysis (ABSA). Specifically, it employs GPT-4o, the latest iteration of OpenAI's Generative Pre-trained Transformer, accessed via the OpenAI API. Figure 1 represents this study design.
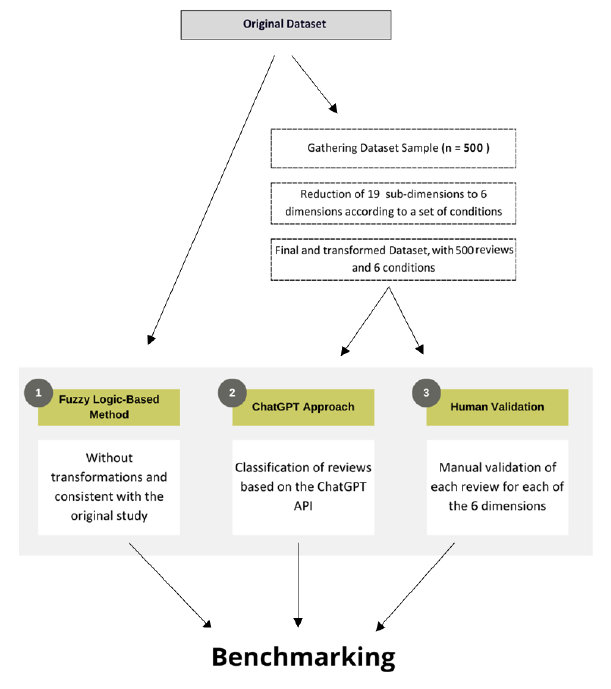
The dataset used in this study originates from the work of Rassal et al. (2023), which comprises 6,742 validated reviews from four- and five-star all-inclusive hotels from Tripadvisor, a primary platform for customer reviews of accommodation services. These reviews were gathered between August 2003 and April 2019 and encompass 19 sub-dimensions.
Given the costs associated with using ChatGPT and the processing time required (approximately 2 to 4 seconds per review), we opted to analyze a random sample of 500 reviews (n=500) to ensure a more comprehensive representation of the dataset while maintaining feasibility. Rassal et al. (2023) applied a fuzzy sets approach, allowing the assignment of degrees of pertinence to customer descriptions.
The dataset was prepared to ensure compliance with ethical data usage standards and to optimize it for analysis. Large Language Models (LLMs), such as GPT-4o, are inherently trained on vast amounts of real-world text, which enables them to interpret and detect nuanced meanings, even from raw or unprocessed data. This capability allows for a context-aware analysis that can uncover subtle patterns in sentiment. Nevertheless, to enhance the accuracy of the analysis and refine the dataset for research purposes, several preprocessing steps were undertaken. First, all personal identifiers were removed to ensure anonymity and align with ethical guidelines. Each review was assigned a unique code to maintain traceability while safeguarding user privacy. Next, the text underwent noise removal, where non-alphanumeric characters, control characters, URLs, and extraneous symbols were stripped from the data to produce a cleaner input for analysis. Additionally, all text was standardized by converting it to lowercase to ensure uniformity across the dataset.
Given the dataset's initial complexity of 19 sub-dimensions, it was necessary to consolidate it into six dimensions, as the study by Rassal et al. (2023), to ensure an equal representation of various aspects of the reviews. These aspects are Staff, Price, Place, Ambience, Experiences, and Services (see Table 2 for a summary of the dimensions and their corresponding sub-dimensions).
Table 2 Summarization of Sub-Dimensions into Dimensions
| Dimension | Sub-dimensions |
| Staff | Staff, Language, Empathy, Assurance, Responsiveness and Reliability |
| Price | Rates, Promotions and Price |
| Place | Location and Room |
| Ambience | Hotel and Design |
| Experiences | Organization and Experience |
| Services | Facilities, Services, Food and Beverage |
Source: Own elaboration.
The Staff dimension encompasses various aspects related to interactions with hotel staff, including their behavior, professionalism (Staff), language proficiency, and communication skills (Language). It also covers the ability of staff to understand and address customers' needs (Empathy), their confidence and knowledgeability (Assurance), responsiveness to requests (Responsiveness), and the consistency of service delivery (Reliability).
The Price evaluates the cost associated with the hotel services, including the standard rates charged for accommodations and amenities (Rates), any promotional offers or discounts available (Promotions), and the overall perceived value paid by customers (Price).
The Place dimension encompasses the hotel's location and room characteristics. Location includes aspects such as proximity to attractions, accessibility, and surroundings (Location). Room evaluates the quality of the accommodations, including cleanliness, comfort, view, and size (Room).
Ambience considers the overall atmosphere and design of the hotel. It encompasses factors such as the general ambiance, mood, and vibe, including the friendliness and warmth of the environment (Hotel). Design evaluates the aesthetics, layout, decoration, and style of the hotel's public and private areas, including rooms, the lobby, and common spaces (Design).
Experiences focus on customers' satisfaction with the hotel's atmosphere and the general quality of the setting. This includes the subjective experience (Experience) during their stay, such as comfort and the pleasantness of the environment, as well as the layout and quality of visual, auditory, and functional elements (Organization). Additionally, it assesses the efficiency and structure of the hotel's service system, aiming to reduce inefficiencies and enhance overall satisfaction by considering waiting time, service efficiency, and satisfaction with the hotel's operations.
The Services dimension assesses the hotel's availability and quality of services. (Facilities) evaluate the amenities, infrastructure, and physical features the hotel provides, including recreational areas, business facilities, and parking. Services examine the efficiency, responsiveness, and quality of customer service provided by staff, including housekeeping, concierge, and front desk assistance (Services). (Food and Beverage) assesses the variety, quality, and presentation of food and beverage options available at the hotel.
Sub-dimensions are evaluated on a scale ranging from -1, 0, 1, and blank, representing different meanings of customers' experiences. The value -1 indicates a negative evaluation, reflecting an unfavorable experience. A rating of 0 indicates a neutral evaluation, where the user does not express a strong opinion, positive or negative. On the other hand, a value of 1 represents a positive evaluation, demonstrating user satisfaction. When the review does not refer to the analyzed sub-dimension, it is classified as blank with no associated sentiment.
Once these values are established for the sub-dimensions, a set of rules must be established to condense them into six dimensions. This step is crucial as it will enable a comparative analysis in the future. These rules are applied separately to each dimension by evaluating the various combinations of values assigned to the sub-dimensions. This process determines the overall sentiment for each dimension, ensuring that the aggregate sentiment reflects the nuances captured within the sub-dimensions. Table 3 describes all the conditions considered.
Table 3 Conditions employed for aggregating Sub-dimensions
| Condition | Overall Sentiment |
|---|---|
| The majority of sub dimensions rated as 1 | 1 |
| The majority of sub dimensions rated as -1 | -1 |
| The majority of sub dimensions rated as 0 | 0 |
| All of sub dimensions rated as blank | Blank |
| Half of sub dimensions rated as 1 and half as -1 | 0 |
| Half of sub dimensions rated as 1 and half as blank | 1 |
| Half of sub dimensions rated as -1 and half as blank | -1 |
Source: Own elaboration.
After obtaining the dataset structured into six dimensions and incorporating the results from the previous study, which will serve as the first benchmark to assess the efficacy of the approach with ChatGPT, the next step is to use a ChatGPT approach to extract aspects and analyze sentiments expressed in the reviews.
To enable ChatGPT's analysis, it is necessary to use its Application Programming Interface (API). Specifically, the OpenAI API allows users to send requests to the ChatGPT model hosted on servers maintained by OpenAI. These requests typically consist of textual inputs, such as prompts or questions, which the model processes and responds to accordingly. The API handles the communication between the user's application and the ChatGPT model, providing a scalable and user-friendly infrastructure for deploying AI solutions. Detailed information is available in the OpenAI documentation (OpenAI API, n.d.).
The study utilized the GPT-4o model, chosen for its advanced natural language processing capacity and its ability to generate human-like text. Python programming language and the openai-python library were used to interact with the model. Parameters were carefully chosen to optimize performance: a temperature of 0 was set to ensure deterministic outputs, maximizing consistency in the responses; the maximum token limit was set to 4090 to accommodate longer input sequences; and the top_p parameter was also set to 1, allowing the model to consider all possible tokens when generating responses.
For ChatGPT to classify the reviews accurately, a prompt, which is the message parameter, is necessary for each of the six dimensions. This prompt provides information about each one and examples, ensuring the model clearly understands what to look for and how to assess the sentiment expressed in the reviews. Following this, the objective is for ChatGPT to analyze the sample of reviews and classify them into -1, 1, 0, or blank per dimension. Figure 2 exemplifies the prompt used for the Place dimension.

To replicate Rassal et al.'s (2023) study and use their results as a benchmark, the dictionary created by those authors was employed to identify the specific aspects addressed in each dimension. Table 4 illustrates an example of the output generated by the prompt used for the Place dimension.
Table 4 Example of output for the Place dimension
| ID | Text | Place Aspects |
|---|---|---|
| 12184 | The hotel is situated in a very nice location near the beach with fabulous views and shaded gardens. The staff are willing and helpful. The pool is quite small and very deep. The lifts are not totally reliable. The food was not of a good standard in either quality or variety. The soft drinks that were served to Saga guests in the bar were of poor quality. These were served from a plastic bottle and if the bottle had previously been opened, the drink was flat and tasteless. We have had much better value in Spanish hotels. | [General sentiment: 1, ', Justification: The review positively mentions the hotel's location near the beach, fabulous views, and shaded gardens, which are all aspects related to the PLACE dimension. Although there are negative comments about other aspects of the hotel, such as the pool, lifts, and food quality, these do not pertain to the PLACE dimension as defined for this task. Therefore, the sentiment regarding the PLACE dimension is positive.] |
Source: Own elaboration.
However, since the original dataset did not include manual human labeling, a crucial step was added to this research to ensure an evaluation of model performance. A manual human labeling process was conducted on a random sample of 500 reviews, creating a reference dataset to evaluate which model extracted the most accurate aspects and sentiments. Human validation became essential to ensure the highest accuracy of the benchmarking methodology. This approach is crucial to ensuring the integrity of the findings and demonstrates a commitment to the accuracy of the analysis. Combining human analysis with the evaluation of ChatGPT's performance makes it possible to ensure the quality of the data and the conclusions drawn.
A similarity measure, an extension of the traditional Jaccard and Dice measures (Han et al., 2011), was adopted to analyze the similarity between the three approaches. While these measures are valuable for comparing binary data, they are less effective when dealing with variables encompassing a more comprehensive range of values or non-binary representations. For that reason, we present a new measure which we call Similarity Coefficient (SC). This measure considers all dimensions as elements instead of traditional approaches that focus on individual elements.
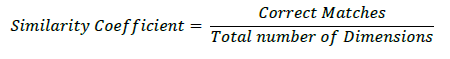
While Jaccard and Dice assess the presence or absence of specific elements in each data set, SC is intended for situations where the aim is to make objective comparisons of the number of elements shared between data sets. In this context, SC establishes a similarity scale between 0 and 1, where the minimum value (0) indicates the total absence of elements in common between the sets, while the maximum value (1) represents the presence of all elements in common. In this way, SC provides a clear and objective metric for assessing the similarity between sets, enabling a precise and quantitative analysis of the overlap between their dimensions. Its interpretation as a percentage adds a layer of flexibility, adapting to the specific objectives of each analysis.
Table 5 shows an example to illustrate the Similarity Coefficient (SC) calculation
Table 5 Comparison values between ChatGPT and Human approaches (for a random review)
| Dimension | ChatGPT | Human |
|---|---|---|
| Staff | -1 | -1 |
| Price | Blank | Blank |
| Place | -1 | -1 |
| Ambience | -1 | -1 |
| Experiences | -1 | -1 |
| Services | 0 | 1 |
Source: Own elaboration.
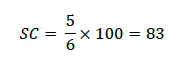
For the dimensions of Staff, Place, Ambience, and Experiences, both approaches rate them as -1, and for Price, both leave it blank. The only difference between the approaches is in the Services dimension, where ChatGPT rates it as 0, and the Human approach rates it as 1. It is important to note that blanks are considered valid values and are included in the calculation. With five matching dimensions out of six, the SC value of 83% indicates a high level of similarity between the two approaches across the evaluated dimensions.
4. Results
The results of comparing three distinct approaches - analysis conducted in the Rassal et al. (2023) study (Previous), human analysis (Human), and automated analysis by the ChatGPT model (ChatGPT) - unveil significant insights into the efficacy and reliability of each method. Table 6 presents the comparison values between approaches per dimension.
Table 6 Comparison values between approaches per dimension
| Dimension | ChatGPT vs Human | Human vs Previous | ChatGPT vs Previous |
|---|---|---|---|
| Staff | 95% | 72% | 75% |
| Price | 74% | 44% | 42% |
| Place | 86% | 81% | 79% |
| Ambience | 87% | 71% | 81% |
| Experiences | 93% | 23% | 23% |
| Services | 91% | 55% | 57% |
Source: Own elaboration.
To contextualize these findings, the results address the study’s two guiding research questions:
RQ1: How can sentiment analysis leveraging Large Language Models (LLMs) enhance the capabilities of Aspect-Based Sentiment Analysis (ABSA)?
RQ2: How does the performance of an LLM-based approach to ABSA compare to a manual analysis approach?
The results demonstrate how the LLM-based approach enhances ABSA (RQ1) and compares with the previous approach in terms of accuracy, particularly in capturing the linguistic nuances of customer reviews. In addressing RQ2, the results demonstrate that ChatGPT achieves high similarity with the Human approach, with similarity scores consistently above 70% across all dimensions and exceeding 90% in dimensions like Staff, Experiences, and Services. These findings highlight ChatGPT's ability to approximate human sentiment classification accuracy while offering the advantages of automation and scalability. However, when comparing the Previous study with Human or ChatGPT approaches, it becomes evident that their values are remarkably similar. Across various dimensions, such as Ambience, the differences are minimal, varying by a maximum of only ten percentual points, underscoring the robustness of ChatGPT.
Despite the high level of agreement between Human and ChatGPT classifications, discrepancies emerge when compared with the Previous study. The low levels of concordance in this comparison suggest that the Previous approach could have been more effective, especially in dimensions related to Price and Experiences.
A detailed analysis was conducted using the previously selected sample of 500 reviews to provide a more prominent understanding. Table 7 presents the descriptive statistics for the Similarity Coefficient (SC) values between approaches per review.
Table 7 Descriptive Statistics for SC Values Across Comparison Approaches
| Metric | ChatGPT vs Human | Human vs Previous | ChatGPT vs Previous |
| Maximum | 100.0% | 100.0% | 100.0% |
| Minimum | 64.5% | 13.9% | 15.2% |
| Mean | 95.1% | 56.8% | 58.7% |
| Standard Deviation | ≈ 0.081 | ≈ 0.152 | ≈ 0.143 |
Source: Own elaboration.
For the ChatGPT vs. Human comparison, maximum similarity reached 100%, indicating perfect agreement, while the minimum score was 64.5%, suggesting some divergence between the Human and ChatGPT approaches. Similarly, in the comparison between the Human vs. Previous studies, the maximum similarity was 100%, with a minimum score of 13.9%. In comparing the previous study and ChatGPT classifications, maximum similarity was also 100%, with a minimum score of 15.2%. The standard deviation (SD) values in Table 7 highlight the consistency of similarity scores. ChatGPT vs. Human shows the lowest SD (≈ 0.081), indicating highly consistent performance around the mean (95.1%). In contrast, higher SDs for Human vs. Previous (≈ 0.152) and ChatGPT vs. Previous (≈ 0.143) reflect greater variability, particularly in dimensions like Price and Experiences.
5. Discussion
The analysis of sentiment classification across the three approaches-Previous (Rassal et al., 2023), Human, and ChatGPT-reveals several critical insights into the performance and interpretative capabilities of each method. Discrepancies were noted predominantly in reviews where subjective nuances or conflicting polarities were present, challenging the effectiveness of traditional methods. To elaborate on these findings, a subset of the processed reviews from the sample is presented below and analyzed in detail.
Upon examining the lowest similarity values between classifications from the Previous study and the Human or ChatGPT approach, it was observed that these discrepancies occurred within the same review. See Figure 3 for example. Table 8 shows the sentiment classification for the review by dimension for the three approaches of this example.

Table 8 Review sentiment classification
| Dimension | Previous | ChatGPT | Human |
|---|---|---|---|
| Staff | 1 | -1 | -1 |
| Price | 0 | -1 | -1 |
| Place | 0 | Blank | 0 |
| Ambience | 0 | 0 | 1 |
| Experiences | 0 | -1 | -1 |
| Services | 0 | -1 | -1 |
Source: Own elaboration.
Analyzing the review on the Staff dimension reveals critical issues with check-in and the pool shack's inconsistent opening times, suggesting a lack of reliability and responsiveness from the staff. The ChatGPT approach correctly identified the negative aspects associated with the staff, classifying the dimension as negative. On the other hand, the Previous approach, using the fuzzy approach, attributed a positive feeling, possibly due to the word staff in the review. However, this classification needs to be revised since the comments clearly show a negative experience with the staff.
When considering the Price dimension, dissatisfaction with the hotel's prices is evident (hotel charged €6 for a coke and an orange fanta at pool shack!). The previous approach assigned a neutral value to this dimension since it is not explicitly mentioned. In contrast, ChatGPT correctly identified the dissatisfaction expressed in relation to prices, assigning a negative sentiment to the price dimension since it was based on the context provided in the review. The last sentence reinforces dissatisfaction with the hotel's prices.
In the case of the Place dimension, it was considered neutral by the Human and Previous approach, while ChatGPT classified it as Blank, indicating the absence of aspects for this dimension. The difference in rating can be justified by the lack of specific mentions of aspects related to the Place dimension, as justified by ChatGPT. However, this assessment can be contested since the expression Room 614 can not fault it indirectly indicates satisfaction with the quality of the room.
As for the Ambience dimension, the divergent classification between approaches suggests that the interpretation of feelings may vary depending on the emphasis given to different aspects of the review. While the Human approach assigned a positive sentiment, ChatGPT considered the review neutral due to the mixed comments about the overall experience at the hotel. These discrepancies highlight the importance of considering subjectivity and context.
For the Services dimension, the review indicates dissatisfaction with the all-inclusive service due to the lack of cold drinks and poor quality and variety of food. In this situation, where the review is not objective, the Previous approach failed to classify adequately, assigning a neutral sentiment, unlike ChatGPT, which agrees with the Human approach, with both negative evaluations.
The same occurs in the Experiences dimension. The review reflects the customer's negative experience and lack of desire to return, but the previous study incorrectly gave a neutral sentiment. The fact is that the Experience dimension in the Previous approach is only 23% in line with Human and ChatGPT approaches. This discrepancy is related to the methodology employed by the previous approach, which assigned an average degree of pertinence when considering both positive and negative points. However, the review's predominance of negative aspects results in an overall negative experience, where unfavorable aspects outweigh positive ones. ChatGPT correctly identified this trend, emphasizing the importance of considering the whole context.
The difficulty in correctly categorizing the Experience dimension also arises when a positive experience is in question. Considering the review in Figure 4, the result for approach was: Blank, 1, and 1, respectively for Previous, ChatGPT, and Human.
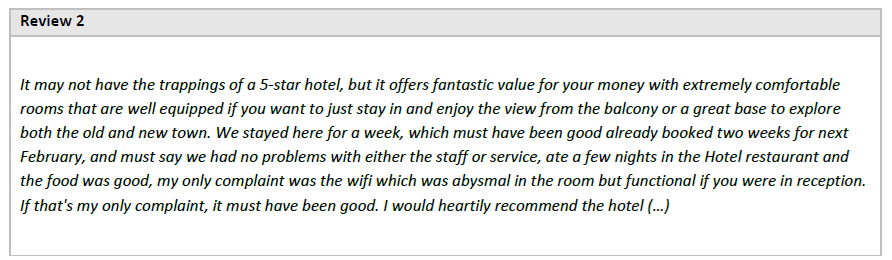
The review highlights several positive aspects of the hotel experience, such as comfortable rooms and a favorable location for exploring the city, and praising the service's quality. Although he mentioned a minor complaint about the Wi-Fi, the general feeling remained positive. In the ChatGPT analysis, the review was interpreted as positive regarding the Experiences dimension, similar to the Human approach. Although the problem with the Wi-Fi was mentioned, it did not affect the overall positive feeling expressed in the review. It is interesting to note that the above approach indicates the absence of mention of the Experiences dimension. This difficulty in identifying and assigning a score to the Experiences dimension emphasizes the advantage of using LLMs, which can process a large amount of contextual information and linguistic nuances, as well as understand the whole context.
When analyzing other reviews, the previous study's difficulty in adequately interpreting the context of sentences becomes clear. See Figure 5 for example. The result for approach was -1, 1 and 1, respectively for Previous, ChatGPT, and Human.

In the previous review, where it is mentioned that the staff is great, the Previous study made a mistake by wrongly attributing a negative feeling to the staff dimension. This discrepancy highlights a need to understand the comment's true meaning, omitting the sentence's full context. By failing to recognize the expression of a positive sentiment towards the staff, the previous analysis reinforced its limitation in accurately interpreting the sentiments expressed by customers, failing to deal with the absence of punctuation in the sentence. This failure to recognize the duality of the feelings expressed in the review emphasizes the need for more sophisticated methods of textual analysis capable of adequately understanding and interpreting the complexity of human expressions, such as LLMs, underscoring the significance of the present study.
Figure 6 provides an additional example highlighting ChatGPT's distinct ability to interpret a sentence's context. The sentiment analysis of the review by the Price dimension was -1, Blank and Blank, respectively for Previous, ChatGPT and Human approach.

In this review, the customer discusses an activity outside the hotel - a boat trip - and expresses satisfaction with the perceived value of this activity. In the context of the Price dimension, which focuses on aspects related to costs within the hotel, both ChatGPT and the Human approach correctly identify that this mention is not directly associated with the hotel establishment in question. Consequently, a blank rating is given to the price dimension. On the other hand, the previous study failed to make this distinction, leading to a negative sentiment rating. Due to their high capacity to deal with subjectivity and ambiguity more effectively, learning- based language models such as LLMs often outperform humans in interpreting complex texts.
Considering the review in Figure 7, the result for the approach was: 1, 1, and Blank, respectively, for Previous, ChatGPT, and Human.

While the Human approach classified the Staff dimension as blank, indicating the absence of sentiment, ChatGPT interpreted the mention of service as positive, highlighting the friendliness of the service. In the justification provided by ChatGPT, the mention of friendly service is interpreted as an indicator of positive sentiment towards the hotel staff, highlighting a subtlety in the language that may have been overlooked in the Human analysis.
This discrepancy between the interpretations accents one of the nuances of sentiment analysis, where subjectivity and context play a key role. While the Human approach may be more rigid in its classification, ChatGPT demonstrates a greater sensitivity to detail and the interrelationship between the different aspects, holding a significant promise for enhancing ABSA.
Unlike previous studies, such as those by Rathan et al. (2018) and Pham and Le (2018), ChatGPT considers both the words used and the broader context and implicit connections between different elements. This capability accentuates the importance of a flexible and sensitive approach, in which tools such as ChatGPT can offer valuable insights that could easily be overlooked in more rigid Human analysis.
Figure 8 is another example that highlights this capability. The results for the Ambience dimension were 1, 0, and 1, respectively, for the Previous, ChatGPT, and Human approaches.

ChatGPT justified its rating in this review by considering both positive and negative aspects. On the one hand, the flat is described as adequate for our needs, basic but clean with a balcony, indicating a positive experience with the accommodation. However, the crowdedness of the pool area (The sun loungers get snapped up quickly) is mentioned as a negative aspect, which may influence guests' overall experience of the environment. While the Human approach may have been influenced predominantly by the positive aspects, ChatGPT recognized the presence of negative aspects that affect the guest's overall perception of the environment. This situation illustrates how ChatGPT can be more sensitive to specific nuances and provide a more complete analysis in certain contexts.
Conversely, as shown in Figure 9, there are situations that require objectivity. The results for the three approaches were -1 for the Previous approach, 0 for ChatGPT, and 1 for the Human approach.
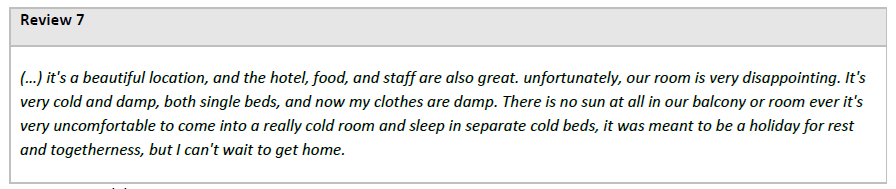
For example, in Review 7, it is possible to see a situation in which the complexity and subtlety of human language can influence ChatGPT's interpretation. While the Human approach attributed a positive sentiment to the services dimension due to the praise for the food, ChatGPT, when considering the broader context of the review, attributed a neutral sentiment, considering the room conditions for the classification of the Services dimension. However, it is important to note that aspects related to the room have already been discussed in the Place dimension, which specifically addresses the physical characteristics and location of the hotel.
In conclusion, although LLMs positively addressed the two research questions (RQ1 and RQ2), the nuanced discrepancies observed between the Human and ChatGPT approaches highlight the importance of meticulous and complementary analysis, particularly in contexts where the subtleties of human language and contextual understanding play a crucial role in interpretation.
5.1 Theoretical Implications
This study underscores the advantages of Large Language Models (LLMs) like ChatGPT in capturing nuanced sentiments and resolving ambiguities, which traditional methods such as fuzzy logic often struggle to address. For instance, discrepancies in classifications related to the Staff and Price dimensions highlight the importance of holistic sentiment understanding. ChatGPT’s ability to interpret implicit relationships and contextual subtleties could mark a significant step forward in Aspect-Based Sentiment Analysis (ABSA). By addressing the limitations of earlier methods, ChatGPT facilitates a more detailed understanding of customer feedback, enabling researchers to examine multiple sentiments expressed within a single review. This capability is particularly important in contexts where subjectivity and ambiguity prevail, as it bridges the gap between computational efficiency and human- like interpretative depth. These findings reinforce prior research by Simmering & Huoviala (2023) and Macháliková (2023), which emphasized the effectiveness of LLMs in nuanced sentiment classification and provide a base for future explorations, encouraging the adoption of LLM-based solutions across diverse research domains.
5.2 Practical Implications
From an application perspective, ChatGPT proves to be a scalable and efficient tool for sentiment analysis, offering performance comparable to manual human evaluations while reducing resource intensity. Industries such as hospitality and tourism, which depend heavily on customer feedback for service improvements, can leverage LLMs to analyze sentiments more effectively and efficiently. This capability facilitates the extraction of detailed insights and the automation of feedback analysis, enabling quicker and more informed decision-making. By incorporating ChatGPT into sentiment analysis workflows, organizations can achieve better responsiveness and alignment with customer needs. The findings also suggest that ChatGPT's integration into customer service platforms could significantly enhance sentiment classification accuracy, leading to improved customer satisfaction and loyalty.
Furthermore, ChatGPT’s ability to identify nuanced feedback opens opportunities for personalized recommendations and targeted marketing strategies. As highlighted in the literature (e.g., Liu et al., 2023), these insights align with the growing evidence supporting the integration of LLM-based solutions into practical applications. The scalability and adaptability of such models could provide a cost-effective and high-performance alternative to traditional sentiment analysis methods, making them particularly valuable for large-scale datasets.
6. Conclusions
In today's business environment, understanding customer feedback in a detailed way is essential. The process becomes more challenging when a single sentence addresses multiple aspects and includes opinions with opposing polarities. This is where ABSA comes in. However, due to the complexity of human language and the time required, traditional sentiment analysis methods became unreliable. They often failed to capture customer sentiment accurately, especially when dealing with subjective and ambiguous language. This study uses GPT-4o, an LLM, to improve ABSA by taking advantage of ChatGPT's capabilities. Two approaches were employed to benchmark the novel ChatGPT approach-a Previous approach (based on a dictionary approach) and a Human approach-to determine how LLMs can be used to enhance ABSA.
Comparing the GPT-4o approach with the two other approaches revealed a high similarity between the Human and ChatGPT approaches, consistently above 70% across all dimensions, particularly in the Staff, Experiences, and Service dimensions, exceeding 90%. These findings highlight ChatGPT’s capacity to understand context and implicit relationships in customer reviews. The model can process large volumes of data, providing a more refined sentiment classification than traditional methods.
This study offers a more flexible and sensitive approach to sentiment analysis, marking significant achievements by overcoming the limitations of previous techniques, and represents an advancement in the field through its novel application of LLMs for ABSA in customer reviews. Building on these foundations, the study validates the claims of Simmering and Huoviala (2023), who highlighted the superiority of LLMs over traditional methods, and corroborates Macháliková's (2023) conclusions about the effectiveness of ChatGPT, contributing to the growing evidence supporting LLMs in ABSA. Additionally, this study establishes a methodology for how other researchers can use LLMs for ABSA studies.
These findings contribute to academic research and hold implications for organizations, especially tourism-related organizations, that seek efficient and scalable solutions for customer feedback analysis and market research. With this solution, organizations can conduct a more precise and rapid sentiment analysis using ChatGPT to extract insights from vast amounts of data, allowing them to understand areas of improvement. Moreover, the automated review analysis and tailored recommendation generation lead to enhanced customer loyalty.
Despite the advancements, it is crucial to acknowledge some limitations. While ChatGPT demonstrates impressive capabilities in simulating human-like sentiment analysis, its interpretations may be influenced by the quality and specificity of the prompt provided. Furthermore, the study found instances where executing the code produced different results with the same command. This variability highlights the complexity of LLM models, which rely on probabilistic processes and may yield divergent results under certain conditions. Using a sample of 500 reviews and the only use of ChatGPT through GPT-4o also could limit the representativeness of the training data, affecting the model’s quality.
Following these limitations, future efforts may focus on increasing the sample size and extending it to other contexts, as well as using other versions of GPT or other LLMs such as Gemini, Claude 3.5, or even open-source options such as Mistral and LLama 3, with the advantage of being open source and cost-free. Additionally, providing more training examples and simplified prompts could be crucial for enhancing the quality of the results. Finally, establishing benchmarks with other LLMs can guide researchers in selecting the most suitable model for specific tasks.

