











 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
1.Introdução
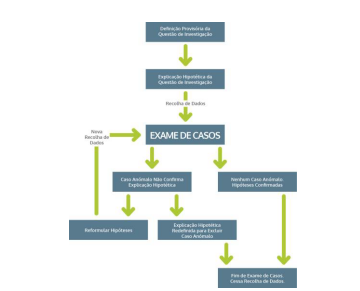
Um dos problemas dos novos investigadores, entre outros problemas e dilemas (Alarcão, 2014), é transpor as instruções e conselhos teóricos dos manuais de metodologia em ações concretas na investigação. Somando a este problema, temos a dificuldade da curva de aprendizagem sobre os softwares de investigação qualitativa e sua adequação aos caminhos técnicos e metodológicos escolhidos. Estas duas dimensões: i) adequação teoria à prática e ii) adequação ferramenta à prática, lançam um desafio aos chamados Qualitative Data Analysis Software (QDAS) do qual o webQDA® consegue dar resposta muito satisfatória. Neste trabalho, apresentaremos inicialmente conceitos básicos ligados à Teoria Fundamentada (Grounded Theory - GT) e suas discussões e processos mais relevantes. De seguida, passaremos para os sete passos da integração da GT com as ferramentas do webQDA®, na dimensão do processo de análise de dados. Não se espera que o leitor possa esgotar as possibilidades teóricas, nem técnicas com integração do webQDA®, mas que este artigo seja uma semente que possa despertar novos caminhos metodológicos. Esperamos que possam enriquecer na prática dos caminhos de análise para a sistematização, rigor, validade e coerência na investigação qualitativa. Analisar dados na investigação qualitativa sempre foi e sempre será um desafio próprio das ciências. Analisar dados requer um questionamento reflexivo, mas substanciados em dados em “concreto”. Requer sistematização e argumentação para tornar óbvio o que não é evidente na primeira leitura. Como na investigação qualitativa os dados são referentes aos sujeitos, estes são diversos, complexos e multifacetados. Isso torna a tarefa de rigor e sistematização científica tão ou mais desafiadora do que definir as funções do “proteoma” nas funções biológicas de um organismo vivo. No geral, quando analisamos dados na investigação qualitativa, organizamos, transcrevemos, lemos e relemos os dados, comparamos, codificamos em sistemas taxonómicos, ordenamos e reordenamos, reduzimos ou sintetizamos dados, interpretamos com base num substrato teórico ou questões de investigação abertas, descrevemos, explicamos e argumentamos, entre outros. Claro que tudo isso deve ser realizado de forma metodologicamente coerente e que mostre transparência e idoneidade aos nossos leitores e avaliadores. Todas estas ações são fontes de dificuldades e dilemas na análise qualitativa. Assim, poderíamos resumir as fontes desta problemática em duas grandes vertentes: i) a natureza do corpus de dados que são não-estruturado, difuso e complexo, ii) a natureza das regras e métodos de análise que não são claras ou largamente aceites. Por isso, concordamos com Bryman (2012) quando afirma que deveríamos sempre fazer em abordagem gerais que necessitam ser sempre contextualizadas para cada projeto de investigação. Um exemplo destas problemáticas pode ser ilustrado na Figura 1, em que apresentamos um esquema geral para a Indução Analítica elaborado por Bryman (2012). No centro deste esquema, temos o exame dos dados como um grande caixa preta. Para este autor, os investigadores nunca apreciaram a rigidez da Indução Analítica, porque basta um único caso anómalo para que nova hipótese ou nova recolha de dados seja necessário neste processo de analise iterativo. Neste processo de analise, a explicação final especifica há condições suficientes para que o fenómeno ocorra, mas raramente nas condições necessárias. Contudo, o mais limitador deste processo de analise é não fornecer instrução detalhada sobre como os casos serão investigados, ou seja, a caixa negra: “Exame de Casos”.
2.Pressupostos Básicos da Teoria Fundamentada (Grounded Theory)
A Teoria Fundamentada (Grounded Theory GT) é ao mesmo tempo uma metodologia de recolha e uma técnica de análise de dados. Não obstante, será na sistematização das operações básicas de análise de dados que concentraremos nossa atenção. O marco inicial da GT é o livro “The Discovery of Grounded Theory: Strategies for Qualitative Research” de Glaser e Strauss (1967). Este livro apresenta a investigação qualitativa como uma estratégia para gerar uma nova teoria. Por isso, é possível traduzir a Grounded Theory como Teoria Fundamentada nos Dados, ou seja, a investigação parte da ideia “não tenho uma teoria”, e com base na análise de dados em ciclos, tal como apresentado na Figura 2, podemos alcançar este fim, propor uma teoria.
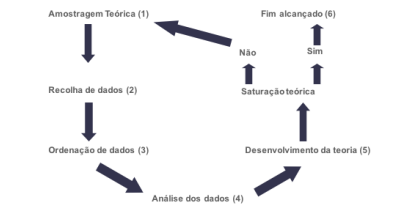
Uma das grandes novidades em relação ao que existia (Indução Analítica) é o maior detalhamento sobre o processo de análise de dados em três etapas: i) Codificação Aberta, ii) Codificação Axial, iii) Codificação Seletiva em cada ciclo de análise antes de chegar a saturação teórica que seria uma das bases para o desenvolvimento da teoria. Observando a Figura 2, o processo geral da GT parte da amostragem teórica, que é a escolha não-estatística do corpus de dados, ou seja, a escolha por critérios teóricos coerentes às questões de investigação específicas. Seguindo, ocorre a primeira recolha e ordenação dos dados para sua posterior análise, com base no protocolo iterativo nas três etapas. Portanto, neste processo, aponta-se para o desenvolvimento de uma teoria mediante a saturação teórica ou algo próximo disso. Este processo é cíclico e geralmente está carregado de várias recolhas e análises do corpus de dados. É evidente que a GT não é uma unanimidade, nem está isenta de críticas, mas a sistematização da análise é possivelmente uma das responsáveis pelo sucesso e sua adoção por muitos investigadores. Por exemplo, Glaser acusa Strauss em trabalho posterior (Strauss & Corbin, 1998) de ser muito prescritivo e dar enfâse no desenvolvimento de conceitos no lugar de teorias. Outros autores, como Charmaz (2006, 2008) compreendem o processo de codificação não exatamente com os mesmos passos originalmente concebidos, mas com processos semelhantes aos propostos. No entanto, existem outras controvérsias sobre o que é Grounded Theory e seus detalhes, que não iremos abordar aqui, mas convidamos o leitor a compreender alguns conceitos gerais e importantes para a GT:
Em suma, a análise dos dados é um procedimento central na teoria fundamentada (Grounded Theory). Ou seja, a GT pressupõe dar nomes (etiquetas) às partes componentes que parece ter potencial de significado teórico ou relevante ao contexto estudado, serve para etiquetar, separar, copilar e organizar os dados. A GT tem caráter tentativo, constante estado de revisão e fluidez, daí uma necessidade mais pungente de um software que acompanhe estas características. Para a GT os dados são tratados como potenciais indicadores de conceitos, e os indicadores são constantemente comparados.
2.1Tecnologias específicas para apoiar o processo de análise da Teoria Fundamentada
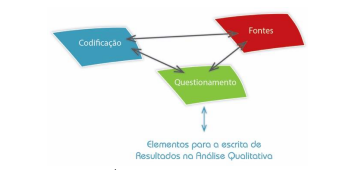
Compreendendo que os processos de análise da teoria fundamentada (GT) é iterativa, complexa e detalhista com comparações constantes, podemos questionar: como um software poderia ser processo e instrumento para apoiar estas ações de análise e reflexão na GT? Neste artigo, não prescinde completamente um conhecimento mínimo de software de análise qualitativa. Para exemplificarmos e estudarmos a relação entre os processos da GT e uma ferramenta tecnológica, iremos usar a estrutura básica e funcional do software de análise qualitativa webQDA®. Contudo, admitimos que muitos utilizadores poderão ter uma visão geral do sistema por meio de sete passos para a integração do webQDA® na teoria fundamentada. O webQDA (www.webqda.net) surgiu em 2010 com um dos primeiros softwares a tratar com texto, áudio, vídeo e imagem completamente online. Este sistema é registo de marca da Universidade de Aveiro em parceria com empresas de tecnologia portuguesas (Costa, Neri de Souza, Reis, Freitas, & Neri de Souza, 2016 ; Neri de Souza, Costa, & Neri de Souza, 2012; Neri de Souza, Neri de Souza, Costa, Moreira, & Freitas, 2017). Para além de está em ambiente distribuído e permitir o trabalho colaborativo online, uma das grandes novidades do webQDA é usar uma estrutura simples e compreensível (Ver Fig.3). A maioria das suas ferramentas estão reunidas em três grandes áreas: i) Fontes, ii) Codificação e iii) Questionamento. Sendo que cada uma delas está interligada de forma dinâmica e simples.
Na atual versão do webQDA®, não existe padrões de inteligência artificial e todos os processos de interligação são feitos de forma flexível pelo investigador que tem o controle de todo o sistema e ferramentas de codificação para a análise. No sistema de Fontes, é possível organizar todos documentos de um projeto em pastas de acordo com critérios do próprio investigador. Este processo de alimentação das Fontes de informação, por ser feito por etapas ou ciclos de análise quando se busca a “saturação teórica”, é próprio também da Teoria Fundamentada. Ainda no sistema de fontes, é possível atender as necessidades da GT através de anotações e comentários. Estas ferramentas permitem fazer anotações gerais ou comentários sobre partes especificas do documento. Este fato é libertador para o pesquisador que pode prescindir de tomar notas, nas comparações constantes, na forma de papéis desordenados e não facilmente colecionáveis. Existe grandes benefícios para os investigadores da GT em se utilizar especificamente de um software baseado na web, porque permite o trabalho colaborativo de forma facilitada. Neste sentido é de destacar esse potencial de inovação no webQDA®.No sistema de Codificação, existe mecanismo de criação, codificação e mobilização de códigos e referencias numa dinâmica de reinterpretação, seleção e apuramento como se faz necessário na Teoria Fundamentada. Finalmente a comparação contante da Teoria Fundamentada também pode ser beneficiada pelo sistema de Questionamento, que permite ao investigador formular perguntas que comparam partes específicas e/ou partes gerais do projeto codificado, por meio de ferramentas de busca e cruzamento das referências codificadas. Tanto o sistema de códigos como o sistema de questionamento são conjuntos de ferramentas que podem ser usadas para se verificar a saturação teórica. Para aprofundar nosso estudo da relação entre a Teoria Fundamentada e sua conjugação com o webQDA®, na próxima sessão vamos abordar alguns conceitos e processos da Teoria Fundamentada em sete etapas.
3.Relacionando a Teoria Fundamenta ao software de análise webQDA®
Como já foi apresentado, a GT tem três etapas principais de análise: i) codificação aberta, ii) codificação axial, iii) codificação seletiva. Mas não é possível executar as ações destas etapas sem uma preparação prévia e uma retroalimentação do após, como apresentado na Figura 2. Na Figura 4 apresentamos outras etapas que ajudam a explicitar o processo de analise de dados com apoio de tecnologias. Iremos exemplificar com o uso do webQDA®.
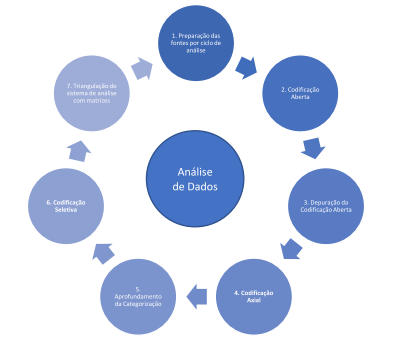
Para garantir uma melhor compreensão destas sete etapas, vamos considerar um projeto no webQDA® com base em entrevistas. Os dados foram recolhidos em ciclos de quatro entrevistas. Duas gravadas presencialmente e duas gravadas online. Assim, no final do primeiro ciclo, teríamos dois vídeos (entrevista online no zoom), e dois áudios (entrevista presencial). Concluído a primeira entrevista, já se pode abrir um projeto no webQDA® e iniciar a preparação desta fonte de dados. Antes de avançar com estas sete etapas para análise de dados com apoio do webQDA® no contexto da teoria fundamenta, é importante esclarecer que existem pelo menos três tipos diferentes de sistema de codificação (Andrews, Mariano, Santos, Koerber-Timmons, & Silva, 2017; Santos et al., 2018). Estas três versões da metodologia são: i) Teoria Fundamenta Clássica (Glaser & Strauss, 1967); ii) Teoria fundamenta Straussiana (Strauss & Corbin, 1998) e iii) Teoria fundamenta construtivista (Charmaz, 2006). No trabalho de Santos et al. (2018) estas três tem as seguintes etapas de codificação (Ver Quadro 1).

Na prática, os investigadores, orientandos e orientadores acabam por criar caminhos complementares que misturam todos estes sistemas de análise. Nossa intenção neste artigo é criar um processo de codificação com integração das tecnologias que seja transversal a todos estes processos defendidos na teoria fundamentada, mas criando inovação de aprofundamento e flexibilidade nas técnicas de codificação.
3.1 Preparação das fontes por ciclo de análise
A preparação dos dados para análise consiste na sua organização, transcrição e validação inicial. No nosso exemplo, teríamos um arquivo de vídeo ou de áudio. Hoje já dispomos de meios para a realização de uma primeira versão da transcrição de forma automática. Mas, mesmo em transcrições realizadas por humanos (terceiros) é sempre necessário a validação da transcrição pelo investigador que realizou a entrevista e que vai analisar os dados. As transcrições automáticas e humanas podem ter erros de pontuação que afetam o sentido da interpretação. Por isso, o investigador necessita ouvir e corrigir a entrevista no seu formato transcrito. Na Figura 5 apresentamos uma entrevista em vídeo importada para o webQDA® com os primeiros parágrafos transcritos. Embora o webQDA® atualmente não faça transcrições, é possível indexar os trechos das transcrições, copiada e colada ou digitada diretamente, com cada parte do vídeo ou áudio selecionado.
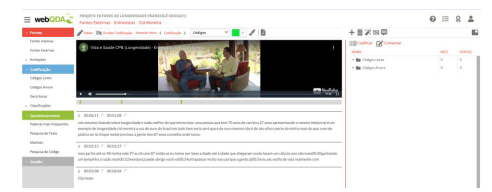
Com a possibilidade de sempre ter acesso ao áudio e vídeo original, é possível por meio do webQDA® fazer vários tipos de transcrições:
A fase de preparação é subestimada por muitos investigadores. Mas é importante salientar que nesta fase o investigador tem a oportunidade de manusear com mais atenção os dados, familiarizando-se com eles. Por isso, é importante no processo de transcrição e validação das entrevistas serem transcritas pelos próprios entrevistados. Assim, o investigador deve enviar a transcrição para o entrevistado fazer correções, confirmações ou mesmo complementos de texto não expresso oralmente. Dessa forma o entrevistado pode acrescentar ou subtrair textos nesta fase. Mas, e se o entrevistado for analfabeto ou não alfabetizado (crianças)? A transcrição deve ser partilhada e validada por outros investigadores que possam acompanhar a gravação e a correspondência na transcrição. Este processo é dinâmico e deve ser feito logo a partir da primeira entrevista disponível, enquanto outros processos de recolha e análise de dados podem ocorrer em paralelo.
3.2 Codificação Aberta
Embora já tenhamos iniciado na preparação dos dados elementos de análise de dados (organização, upload de arquivos em bruto no webQDA, transcrições e validações), é na codificação aberta que iniciamos mais formalmente a análise de dados. O processo de codificação faz parte do processo de análise que consiste em conceitualizar os dados, organizar os dados e estabelecer padrões. Em todas estas ações o investigador necessita ser rigoroso metodologicamente para estabelecer confiança no processo de análise e na fundamentação final da teoria ou conceitos novos gerados. Na codificação aberta, o investigador procura conceitos de forma aberta. Isso, porque os conceitos são componentes fundamentais de uma teoria que se deseja construir. Estes conceitos são representações do mundo real, abstrações simbólicas, imagens idealizadas contidas nos discursos dos entrevistados. Desta forma o investigador deve ler e examinar os textos linha por linha, identificar estes conceitos que emergem desta leitura inicial e tomar notas dos significados que cada uma destas palavras e expressões despertam no seu entendimento. Para exemplificar esta tempestade de anotações com base em palavras-chave e conceitos que emergem da leitura inicial, vamos considerar a entrevista com Alexandre Kalache, presidente do Centro Internacional de Longevidade, realizada por Cauê Rebouças e Juliana de Moraes e disponível online (Ver Figura 6). Esta metodologia de recolha e análise de dados na internet, tem por base a ideia de corpus de dados com potencial latente na internet sugerida por Neri de Souza (2010).

Fonte: http://www.sincodiv.org.br/site/noticia-sincodiv-sp-bate-papo-com-alexandre-kalache-presidente-do-centro-internacional-de-longevidade-3796
Projeto Fatores de Longevidade com base em entrevistas corpus latente na internet
Na Figura 6 apresentamos um exercício de uma leitura inicial e codificação aberta de palavras, termos e frases que podem virar conceitos em fases mais avançadas da análise. Na coluna da esquerda, o texto original com as palavras destacadas e na coluna da direita, existem anotações e questionamentos do investigador que está fazendo a análise. Este pequeno trecho da análise é suficiente para projetar a quantidade gigantesca de códigos e anotações que podem surgir durante esta leitura inicial. A organização e flexibilidade de manuseamento de todas estas informações podem ser otimizadas com a integração de ferramentas tecnológicas especificas como o webQDA® (Ver Fig.7).

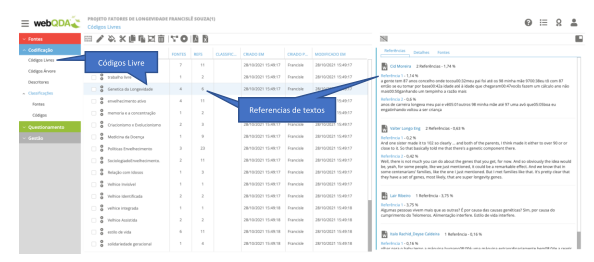
Na Figura 7 destacamos cinco ferramentas que facilitam o processo de codificação aberta com apoio do webQDA: 1) Ferramenta “Código Aberto” - que após ser acionado cria automaticamente um código com a mesma palavra(s) selecionadas durante a leitura do texto; 2) Códigos Livre - são uma sequência de códigos criados no processo de codificação aberta; 3) é possível adicionar comentários, com anotações e questionamentos diretamente para cada código criados nas etapas anteriores; 4) todos os códigos livres criados e com comentários associados ficam marcados duplamente marcados no texto; 5) todos os comentários e questionamentos (memorandos) realizados pelo investigador durante a análise são agrupados e organizados neste setor de anotações. Estamos exemplificando na Figura 6 (Sem software específico) e Figura 7 (Com software especializado - webQDA®) códigos extraídos da linguagem do próprio texto, ou seja, que emergem da leitura das palavras do corpus de dados. Mas existe uma outra forma de criar estes códigos, que são aqueles em que o investigador constrói como síntese das palavras existentes nos textos. Por exemplo, na Figura 6 e 7 destacamos dois termos: “feliz no trabalho” e “satisfação no trabalho”, que existem no texto e foram codificadas que no decorrer da leitura. No entanto, o investigador poderia substituir estes termos por um outro termo que sintetize estas e outras menções ao longo da leitura: “relação positiva com o trabalho” ou “relação saudável com o trabalho” dependendo da ênfase e da definição do conceito que se esteja construindo.
3.3 Depuração da Codificação Aberta através da “Pesquisa das Palavras frequentes” e “Pesquisa de Texto”
Se estamos focados nesta fase de codificação aberta, as palavras que podem se tornar conceitos, é possível que na nossa leitura não consigamos visualizar a densidade e frequência das palavras e expressões mais relevantes. Na codificação aberta, temos que continuar a formular perguntas, tais como: Quais as palavras mais frequentes nesta entrevista? Ela foi contemplada na leitura linha por linha? Existe outras palavras ou expressões que deveriam levar em consideração por sua densidade de significado e não propriamente da sua recorrência? Será que existe neste conjunto de entrevistas palavras específicas que interessam para este estudo? Para responder todas estas perguntas de forma eficiente e eficaz, você necessitará de uma ferramenta como o webQDA® (Ver Figura 8).
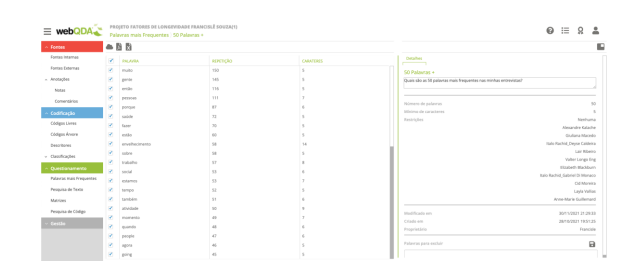
Figura 8 Aprofundamento da codificação aberta no webQDA® através das palavras mais frequentes e busca de palavras.
Na Figura 8, ilustramos uma busca pelas 50 palavras mais frequentes de um corpus de dados. Esta seria uma busca mais passiva e automática para o investigador em um primeiro momento. Depois ele deve ler com cuidado cada palavra, acessá-la com um click o seu contexto e compreender o nível de significado e sua potencialidade de se tornar mais um código ainda nesta fase de codificação aberta. Outra forma de automatizar a busca para responder às perguntas formuladas, é usar a “Pesquisa de Texto”. Neste caso, o investigador deve pensar previamente em palavras e expressões e usar esta ferramenta para pesquisar em todo o banco de dados se elas existem. Esta busca é muito mais ativa por parte do pesquisador porque ele deve imaginar antes quais as palavras que gostaria de pesquisar, independentemente da sua frequência. Ainda nesta fase de aprofundamento da codificação aberta, o investigador deve criar tanto códigos quanto possível, lendo linha por linha do texto e fazer buscas transversais no decorrer do processo. O produto final de tudo isso pode ser um aparente caos, ou uma grande quantidade de códigos e comentários, questionamentos e memorandos. O investigado não deve está preocupado com este aparente caos se ele for feito através de uma ferramenta, como o webQDA®, que indexou tudo nas suas bases de dados. Assim, nas próximas fases da teoria fundamentada e, com a ajuda destas tecnologias, será mais fácil e flexível modelar e praticar as próximas ações preconizadas pelo método. No final desta fase de aprofundamento, recomendamos a releitura das anotações que são imprescindíveis para a execução das próximas fases da teoria fundamenta. Quanto mais ricos forem estes comentários e memorandos, mais rico será o processo de construir a teoria. Desta feita, certifique-se que tenha anotações teóricas, anotações metodológicas, questionamentos dos sentidos, e anotações sobre os códigos criados e suas definições. Em resumo, na codificação aberta, temos pelo menos quatro grandes ações: i) formular perguntas consistentes e especificas aos dados, ii) codificar de forma precisa e exaustiva, iii) escrever memorandos e anotações para reflexões, iv) minimizar suas premissas prévias e focar nos dados.
3.4 Codificação Axial
Nesta fase, o investigador procura criar eixos conceituais com base nos códigos criados desde a fase inicial de codificação aberta. Na prática, o investigador terá uma lista de códigos livres, referências codificadas (unidades de texto) em cada código, anotações e memorandos, classificações e atributos dos entrevistados e das demais fontes de dados indexados no sistema (Ver Figura 9).
Com estas informações, é possível comparar códigos e reler textos (referências) no contexto dos códigos para contruir categorias relacionadas aos problemas e questões de investigação que se deseja estudar. O investigador começa a fazer reduções e síntese de códigos - juntando, eliminado, reescrevendo título dos códigos e suas definições. Este processo indutivo de agrupamento de códigos em categorias mais substantivas e representativas necessita no webQDA® de uma nova área de trabalho para organizar estas hierarquias de códigos. Esta nova área são os “Códigos em Árvore”, que apresentamos na Figura 10.
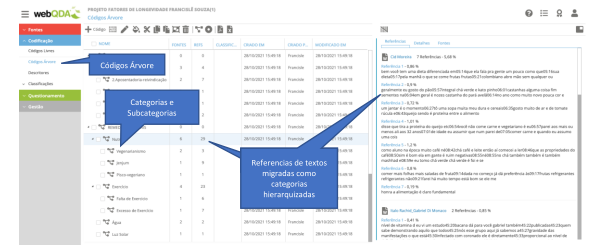
Com o sistema webQDA®, é possível em poucos cliques mover códigos livres para códigos em árvore de forma flexível e rápida. Não somente os códigos, mas todos as referências (textos) que foram codificadas em cada uma delas. Este conjunto de procedimentos procura fazer conexão entre os códigos e transformá-los em categorias. Liga os códigos aos contextos, às consequências, aos padrões de interações e às causas.
3.5 Aprofundamento da Categorização
Para aprofundar o processo de codificação axial é necessário questionar. Pergunte: O que aconteceria se as circunstâncias, ordem dos eventos, características das pessoas, lugares e contextos entre outros, fossem diferentes? Em que os eventos e fatores são semelhantes e diferentes dos outros? Que nova informação obteria se lesse o texto numa ordem diferente (associação livres, cruzamento da paisagem de categorias)? E se comparasse os extremos de uma dimensão de análise (técnica da inversão)? No webQDA® é possível, por exemplo, cruzar um conjunto de categorias para verificar se existe sobreposição de referências em códigos auto excludentes. Para exemplificar, imagine uma categoria que tenha duas subcategorias, uma Positiva e outra Negativa. Se no processo de codificação você se enganar e acabar por colocar as mesmas referências nestas duas subcategorias o webQDA®, poderá denunciar esta interceção de categorias auto excludentes - se uma referência for codificada como “positiva”, não poderá ser codificada na mesma categoria codificada na subcategoria “negativa” (Ver Figura 11).
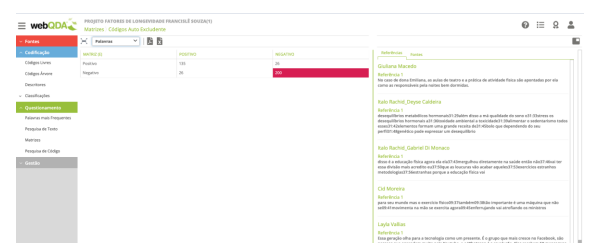
Na Figura 11, foi representada as duas subcategorias cruzadas com operador booleano de intercessão (E) com elas mesmas. Neste caso, existe uma referência com 26 palavras que está codificada na subcategoria positivo e negativo ao mesmo tempo. Esta verificação, para está correta, deveria ter resultados somente nas células da diagonal da matriz. É importante verificar que ao clicar na célula com 200 palavras, o sistema apresenta os textos e as referências que elas correspondem. Desta forma, o investigador pode aprofundar e corrigir o sistema de análise relendo os textos codificados. Neste ponto, é importante relembrar que estamos trabalhando com a teoria fundamentada que tem um processo iterativo (Ver Figura 2), que implica novos ciclos de dados que entram no sistema para ser analisado. Assim, estes procedimentos de cruzamentos de matrizes podem ser usados em outras fases e em outras necessidades do investigador e das questões de investigação. Para aprofundar ainda mais esta fase da análise, recomendamos a ferramenta “Pesquisa de Código” disponível no webQDA®. Em resumo, na codificação axial, teremos os elementos para a ligação de conceitos (ou categorias) com os dados e conceitos (ou categorias) para explorar as: i) condições, ii) contextos, iii) consequências e iv) estratégias (ações e integrações).
3.6 Codificação Seletiva
Na visão de Strauss e Corbin (1998), nesta fase, procuramos a integração de todas as categorias em uma teoria. Isso é feito por meio de um agrupamento em torno de uma categoria central ou dimensão de análise transversal. Esta categoria central é a linha condutora da teoria. Assim, como em outras fases, a comparação constante é fundamental para esta fase de codificação. Para estabelecer esta categoria central, recorremos ás determinações das condições causais, os contextos e condições dos entrevistados e demais intervenientes da pesquisa, bem como as estratégias e suas consequências. A natureza desta categoria central é diferente das categorias ou códigos criados nas fases anteriores. Embora se possa chamar também de código, esta categoria central tem uma natureza de síntese analítica. Para Gibbs (2009) existem pelo menos três tipos de códigos:
“Código Espelho - descreve como um espelho o que é expresso nos dados. Descreve com códigos, com termos tendencialmente semelhantes aos encontrados nos dados. Pode corresponder a codificação aberta da teoria fundamentada. São também chamados Códigos in Vivo (ligados a Codificação Aberta).
Código Síntese - são categorias que expressam uma síntese de ideias de vários códigos espelhos ou do amadurecimento teórico de um código espelho (Ligados a Codificação Axial).
Código Analítico - são categorias teóricas com alto poder explicativo, analítico e criativo. Pode corresponder à codificação axial ou codificação seletiva da teoria fundamentada.” (Gibbs, 2009).
A categoria central na codificação seletiva tem este alto poder explicativo, analítico e criativo. Neste ponto, podemos questionar: Como o webQDA poderia ajudar no processo analítico de construção desta categoria central e suas múltiplas relações? Na Figura 12 apresentamos uma visualização de um sistema de códigos e categorias centrais e suas respectivas referências associadas.
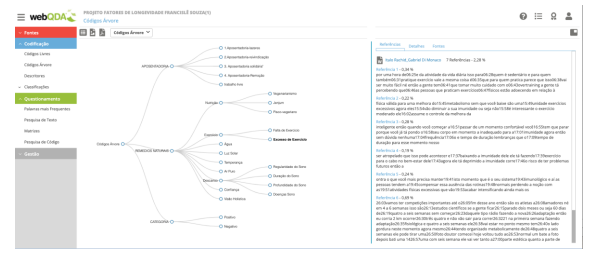
Com esta visualização, flexibilidade de mudança dos nomes dos códigos, acesso direto a todas as unidades de textos (referencias), acesso aos memorandos de forma dinâmica, é possível construir a categoria central neste processo cíclico. Por esta necessidade de dinamismo de codificação e cruzamento de dados codificados, o investigador poderá, nesta fase, recorrer a outras ferramentas do webQDA®: i) a pesquisa de código e ii) as matrizes quadráticas e triangulares.
3.7 Triangulação do sistema de análise com matrizes
Para utilizar as ferramentas de matrizes e pesquisa de código no webQDA® ou em qualquer sistema para análise, o investigador deve sempre partir de uma pergunta. Os questionamentos mais básicos que deveriam ser feitos por todos os pesquisadores na fase de codificação seletiva, são aqueles que cruzam os códigos descritivos (contextos, condições, entre outros) com códigos mais interpretativos (estratégias, consequências). Por exemplo: existem fatores de longevidade mais mencionados por homens e por mulheres? Será que há relação entre a categoria B e as profissões dos entrevistados? Quantos anos têm os entrevistados que falam sobre as causas e/ou as consequências codificadas com os códigos X? Este tipo de perguntas sempre pressupõem uma triangulação com operadores booleanos de intercessão nos sistemas. É observando a Figura 12 e outras partes do sistema no webQDA®, despertando a curiosidade e formulando perguntas que se inicia a triangulação de dados para se obter respostas e feedback que apoiará o investigador para construir teorias e conceitos na teoria fundamentada. Na Figura 13, apresentamos uma matriz que cruza dados para responder a seguinte pergunta: “Existe alguma relação entre as profissões dos entrevistados e o que eles falam sobre o regime nutricional na longevidade das pessoas?”
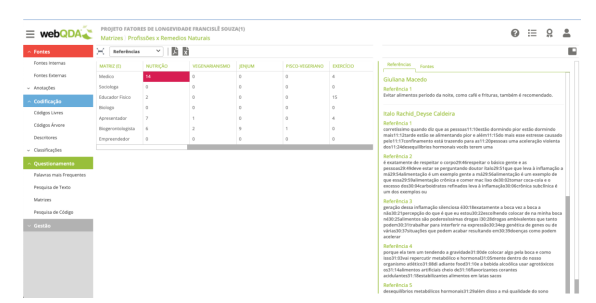
O objetivo deste artigo não é ser um tutorial, mas dar noções sobre as potencialidades deste tipo de tecnologia em todo o processo da teoria fundamentada. Assim, é essencial na fase de construção da categoria central ter a possibilidade de visualizar de forma rigorosa e sistemática os padrões dos dados codificados e revistar sob novas perspetivas das matrizes. O foco não deveria ser somente os números apresentados em cada célula da matriz, mas os textos associados. Cada célula pode ser apresentada por número de referências (unidade de texto), número de palavras e número de documentos (Número de entrevistados, por exemplo). Desta forma, é possível com base nestas triangulações compreender profundamente se existe novos padrões com novos ciclos de análise de dados. Embora a saturação teórica seja uma dificuldade conhecida, estes cruzamentos de dados possibilitam ao investigador mais elementos de confiança para declarar se ela foi alcançada ou não. Segundo Bryman (2012), nem sempre os resultados da Teoria Fundamentada são teorias substantivas ou teorias formais, mas conceitos, categorias, propriedades. Mais especificamente:
4.Considerações Finais
É possível atribuir vários motivos para o sucesso da teoria fundamenta como metodologia de investigação qualitativa. Esta popularidade é apontada por alguns autores (Andrews et al., 2017; Santos et al., 2018) nas suas áreas especificas. Por exemplo, Santos et al. (2018) que chegam a dizer que “a Teoria Fundamentada nos Dados, abreviada como TFD, é um dos métodos mais utilizados na pesquisa qualitativa em enfermagem” (p.2). Acreditamos que o primeiro motivo deste sucesso é por ser uma metodologia detalhada, ou seja, sem ser prescritiva, sugere um passo a passo geral para a investigação. Mas o detalhamento do processo de análise é sem dúvida o que mais segurança passa para iluminar a “caixa preta” da análise qualitativa de dados. Existe naturalmente uma tensão entre a liberdade criativa de análise de dados contextualizados e a segurança de um processo de análise bem estabelecidos e mesmo prescritivo. Assim, existe espaços e aprendizagem tanto para o analisador iniciante quanto para o sénior que domine os fundamentos teóricos, contextuais e processos analíticos. Outro fator importante na popularização da teoria fundamenta é a comparação contante e a influência dos conceitos chaves no processo de análise. Todos estes elementos foram revolucionários em 1967 quando Glaser e Strauss (1967) publicaram o primeiro livro. Todas as controvérsias e disputas que se seguiram só serviram para aprimorar e popularizar a metodologia de investigação e de análise de dados. Apesar de tudo, acreditamos que popularização da Grounded Theory foi acelerada com a facilidade de codificação, flexibilidade de cruzamento e outros atributos que os usos de software de análise qualitativa de dados foram sendo cada vez mais utilizados. Estes sistemas tecnológicos, também chamados de Computer-assisted qualitative data analysis software (CAQDAS) ou mais recentemente somente de Qualitative Data Analysis Software (QDAS), ainda não têm um sistema exaustivo de inteligência artificial, mas existem outros tantos desafios que Evers (2018) traduziu através de sete questões:

