











 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
1.Introdução
Nas últimas décadas, a pesquisa qualitativa tem-se consolidado como instrumento básico na pesquisa, sendo que os pesquisadores utilizam-se dessa abordagem para compreender a perspectiva dos participantes, através da interpretação feita pela experiência do pesquisador. A utilização de programas computacionais, a partir da década de 1980, permitiu iniciar um processo para auxiliar a análise dos dados na pesquisa qualitativa.
Desde então, permanece um debate em relação à utilização de softwares no tratamento dos dados obtidos nas pesquisas qualitativas, que consegue, nos dias atuais, chegar a um consenso quanto à eficiência no gerenciamento e tratamento dos dados extraídos de uma pesquisa qualitativa com a utilização de softwares específicos para tal finalidade.
As principais vantagens na utilização de softwares amparam-se na organização e separação das informações, na melhoria na eficiência do processo de análise, na facilidade em se localizar segmentos de textos, e, finalmente, em uma grande agilidade na codificação.
Os softwares de uso livre baseiam-se no princípio da partilha do conhecimento tecnológico e da liberdade do seu uso, que, como tal, estão disponíveis para serem utilizados sem qualquer custo, a exemplo do Iramuteq, que vem se constituindo como uma importante ferramenta para o uso na pesquisa qualitativa e análise textual.
As mudanças e transformações sociais do século XX fizeram emergir os primeiros autores que trouxeram a abordagem da Responsabilidade Social, com foco nas atividades comerciais e industriais, com o conceito emergente de que as organizações, ao se relacionarem com a sociedade, tornam-se centros de poder, exercendo uma grande influência na vida das pessoas; trouxeram, conjuntamente, a noção de que o empresário necessita ter uma orientação não somente focada nos lucros, mas também em estar em sintonia com a sociedade (Bowen, 1957).
Para Borger (2013), o conceito de responsabilidade social tem sua origem nos Estados Unidos e na Europa, no final da década de 1950, e emergiu da crescente preocupação dos pesquisadores daquela época com o poder e grande autonomia que as empresas exerciam sobre a sociedade, sem qualquer preocupação com as consequências negativas das atividades empresariais em relação à exploração do trabalho, concorrência desleal, degradação ambiental e ao próprio abuso do poder econômico.
Esse grande poder e autonomia das empresas, sem qualquer tipo de preocupação com os impactos das suas atividades, faz surgir, na própria sociedade, um movimento de contraponto aos aspectos negativos que, de algum modo, impactavam a sociedade.
Na visão de Tenório (2006), a mobilização da sociedade exige dos governos que estes façam com que as empresas solucionem os problemas gerados pela industrialização, com a premissa básica de que o processo de industrialização representa o principal causador do aumento da produção, acúmulo de capital e a degradação da qualidade de vida das pessoas.
A conscientização da responsabilidade social e as obrigações das empresas vão ganhando força na sociedade com base na visão crítica de que as empresas devem ir além da geração de empregos e pagamento de salários, contemplando um olhar mais abrangente sobre as questões ambientais e trabalhistas (Tenório, 2006).
Segundo Dias (2012), somente a partir da década de 1960 começa a surgir um comportamento empresarial consciente, resultante da pressão da sociedade junto às empresas, nomeadamente, nos Estados Unidos, quando a sociedade civil se torna protagonista nesse processo de pressão sobre as organizações no sentido de um enquadramento progressivo das empresas para uma situação na qual os problemas sociais tenham de ser enfrentados pelas próprias empresas.
Guimarães (1984) defende a opinião de que a responsabilidade social deve vincular-se à ideia de que indivíduos e empresas devem ser responsabilizados pelos seus atos, e dessa maneira, conscientizarem-se de que são responsáveis e solidários não só pelos problemas, mas, principalmente, pelas soluções.
As empresas buscam atualmente uma legitimidade por meio de ações de cunho social, que integram as suas atividades, à medida que reconhecem e acreditam que tais ações trazem impactos positivos para a imagem corporativa, incluindo, a isso, a crença de que a sociedade atribui um valor adicional às empresas que transcendem o comportamento legal e ético (Oliveira & Gouvea, 2010).
Na visão de Domeneghetti & Meir (2009), a sociedade contemporânea tem realizado um amplo debate e reflexões sobre essa temática, em especial em relação ao meio ambiente, fazendo emergir o conceito sistêmico de “Sustentabilidade’’ assim como suas vertentes econômicas, políticas, culturais e sociais.
A dimensão social está relacionada à maneira com a qual as empresas interagem com a comunidade e com a sociedade, buscando suprir benefícios que não são obrigatórios, mas contribuem com diversos aspectos da vida dos cidadãos, permeando múltiplas áreas (Araújo, 2001).
A própria complexidade dessas relações existentes entre as empresas e a sociedade exige um grande esforço a fim de melhor se compreender o que vem sendo feito para mitigar os diferentes aspectos das ações empresariais bem como o entendimento sobre aqueles impactados pelas atividades empresariais.
A problematização dessa temática, essencialmente complexa e multidisciplinar, está ligada aos aspectos da mensuração e quantificação da forma com que as empresas, de um modo geral, atuam no campo da responsabilidade social empresarial no mundo, e às ferramentas utilizadas para a mensuração da responsabilidade social empresarial.
A partir desse contexto, o presente estudo tem por objetivo apresentar um mapeamento da utilização da metodologia fuzzy para a análise da responsabilidade social empresarial nas relações do trabalho no mundo, utilizando-se de uma revisão bibliográfica, efetuada no período que compreende os anos entre 2013 e 2020, e por meio de análise textual de palavras através da utilização do software Iramuteq.
O artigo organiza-se em cinco sessões, sendo estruturado da seguinte forma: Introdução - Quadro Teórico - Uso do Software Iramuteq de Análise de Palavras - A Metodologia Utilizada na Pesquisa - Os Resultados com uma Análise e Validação pelo Iramuteq - Conclusões.
2.Quadro Teórico
Segundo Fellenberg (1980), a preocupação em relação aos aspectos ambientais nas atividades empresariais, remontam à antiga Grécia e ao Império Romano, com os seus curtumes e pequenas fundições, sendo que naquela época, essas atividades dependiam de autorização para o seu funcionamento, como medida protetiva, em defesa da população, contra os odores e gases tóxicos e desagradáveis emitidos. Já naquela época existia a obrigação de instalação de chaminés como medida de mitigação da poluição.
Tinoco (2001) destaca que, para uma melhor compreensão da responsabilidade social, faz-se necessário entender o ambiente de negócios no qual as empresas estão inseridas, suas interações e os grupos de interesses agregados na cadeia produtiva dos negócios. Esses grupos compreendem fornecedores, empregados, acionistas, provedores de recursos financeiros, clientes e o Estado.
Os diferentes fatores que permeiam a responsabilidade social, muitas vezes, extrapolam esse relacionamento, basal e simplista, pela presença de crescentes mudanças nas expectativas dos clientes, colaboradores e fornecedores em relação à postura da empresa e suas atitudes nos aspectos éticos e ambientais nas relações do trabalho e nas inovações das ações sociais junto à comunidade (Tachizawa, 2015).
Para melhor se compreender a responsabilidade social empresarial em sua visão mais ampla, Elkington (1997) formulou o conceito triple bottom line, que trata da mensuração dos resultados nas empresas em diferentes dimensões: econômica, ambiental e social, partindo da premissa de que as empresas, para garantir sustentabilidade econômica, não podem comprometer, mas, necessariamente, mitigar os impactos ambientais e sociais de suas atividades.
Além da compreensão dos diferentes grupos de relacionamento que interagem com a empresa, faz-se necessário ter uma ampla visão sobre as inter-relações da responsabilidade social empresarial, no âmbito econômico, social e ambiental, com as quais a empresa se depara.
A Figura 1 ilustra uma representação gráfica dessas inter-relações existentes nas três dimensões abordadas: econômica, social e ambiental.

Fonte: Wissmann (2017).
Na dimensão econômica, na visão de Araújo (2001), o lucro pode ser facilmente explicado por meio da apresentação de um modo de mensuração da eficiência com que as empresas se utilizam dos fatores de produção de produtos e serviços para o atendimento das necessidades humanas.
Dias (2012) defende a ideia da relevância do aspecto da cultura empresarial se fazer presente nas empresas, nas ações efetivas e na responsabilidade social por meio de recursos como: legislação, multas, penalidades severas, vigilância dos agentes interessados, meios de comunicação e rápida difusão das denúncias; a responsabilidade social vai assim se transformando, gradativamente, em um processo de incorporação cultural que força a empresa a adotar políticas transparentes perante a sociedade e seus acionistas ao longo de toda a cadeia produtiva.
Existe uma complexidade nas diferentes abordagens da responsabilidade social empresarial, com aspectos multidisciplinares e forças internas e externas da empresa; nesse sentido, o presente estudo foca-se nos aspectos relacionados à responsabilidade social nas relações do trabalho e em seus principais aspectos.
3.Metodologia
O estudo adota uma abordagem qualitativa, sendo que a pesquisa denominada qualitativa não se apresenta com uma rigidez de utilização uma vez que cabe ao pesquisador garantir a flexibilidade que julgar necessária, o compromisso de apresentar um quadro bastante nítido da teoria, assim como assumir uma postura metodológica com um processo continuo de validação (Silva, Gobbi, & Simao, 2005).
O objetivo da pesquisa tem um caráter exploratório, mas com foco em explicitar o problema estudado, não perdendo de vista a amplitude com que a problemática se apresenta (Dalfovo, Lana, & Silveira, 2008).
Os procedimentos técnicos do estudo restringem-se em uma pesquisa bibliográfica e documental, e utilizou a análise de conteúdo como ferramenta de análise documental ancorada em artigos científicos de periódicos arbitrados. A pesquisa está enquadrada como ‘descritiva’, visto que exclui a interferência do pesquisador na análise dos dados coletados pela utilização de uma ferramenta, ou seja, de um software de análise (Gil, 2008).
A busca dos artigos científicos envolveu as seguintes palavras-chave: fuzzy social responsibility e social responsability using fuzzy, sendo previamente selecionados 22 artigos, todos em língua inglesa, que possuíam aderência aos objetivos do presente estudo; após a leitura dos artigos, somente 11 artigos, que efetivamente tratam da análise da responsabilidade social com a utilização da ferramenta especialista fuzzy, foram selecionados para serem aplicados no software de análise de palavras Iramuteq.
Optou-se por manter os 11 artigos selecionados na língua de origem na qual foram escritos, e, consequentemente, realizar todas as análises no Iramuteq na língua inglesa com a finalidade de se evitar qualquer tipo de distorção na tradução. O software livre Iramuteq se constitui a partir de um método informatizado de análise textual que organiza a estrutura e os discursos linguísticos por meio das relações entre as características lexicais mais frequentes nos contextos. A literatura científica das publicações disponíveis sobre o tema pesquisado pode ser encontrada nos seguintes portais científicos pesquisados: CAPES Scopus, Google Acadêmico e Web of Science.
O tratamento e validação dos dados embasou-se no software R (www.r-project.org), desenvolvido por Ratinaud, e na linguagem de programação Python (www.python.org) na qual se ancora o software de análise textual Iramuteq (Interface de R pour les Analyses Multidimensionnelles de Textes et de Questionnaires), com resultados obtidos a partir da Análise de Similitudes e Semelhanças, por Nuvem de Palavras, por Estatísticas Básicas do Corpus Textual, e pela Classificação Hierárquica Descendente (Ratinaud, 2009).
Na Tabela 1, é descrita a estrutura das ferramentas utilizadas na coleta, análise, exploração, tratamento e validação dos dados obtidos.
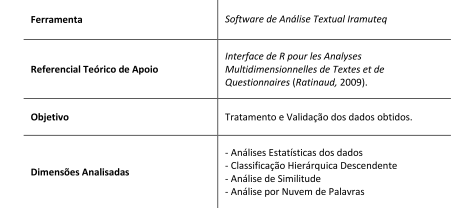
Fonte: Mannarelli Filho, Donadon, Pigatto, Queiróz, & Baptista, (2021), adaptado pelos autores.
3.1 Detalhamento da Análise de Conteúdo Proposta
Os dados dessa pesquisa qualitativa são embasados nos referenciais teóricos para Análise de Conteúdo propostos por Godoy (1995), Silva, Gobbi, & Simao, (2005) e Bardin (2011). Complementarmente, Bardin (2011) conceitua a Análise de Conteúdo como sendo um conjunto de técnicas de análise das comunicações, o qual se utiliza de procedimentos sistemáticos, com objetivos que visam a descrição do conteúdo da mensagem para inferir conhecimentos os quais devem servir de informação e como representação de uma característica de conteúdo ou de um conjunto de características relevantes a ser considerado.
Segundo Godoy (1995), existem três fases fundamentais que precisam ser respeitadas para a elaboração de uma análise de conteúdo: a primeira representa uma pré-análise e a exploração do material, quando é estabelecido um esquema de trabalho que deve ser preciso e com procedimentos bem definidos, embora flexíveis. A segunda fase consiste em cumprir as decisões tomadas anteriormente e, na terceira etapa, deve-se apoiar nos resultados brutos, tornando-os válidos e significativos.
Na presente pesquisa, para a visualização da primeira fase da análise de conteúdo, elegeram-se as palavras-chave descritas na Figura 1, que estavam estritamente em sintonia com os objetivos propostos, e que foram apuradas na revisão sistematizada da literatura; todas as palavras-chaves foram utilizadas para a seleção dos trabalhos, e, subsequentemente, revisadas; na sequência, foram selecionados os artigos que posteriormente serviram de base de dados para elaboração do corpus textual que, por sua vez, foi tratado e validado pelo Iramuteq.
3.2 Análises do Iramuteq
Uma análise textual consiste em um tipo específico de análise de dados, a partir de um texto transcrito produzido em diferentes contextos, podendo este ser um artigo científico, entrevistas transcritas, etc. Esse tipo de análise é aplicado em estudos e investigações para quantificar variáveis essencialmente qualitativas, originadas de um texto (Camargo & Justo, 2013).
O software permite a realização de vários tipos de análises, sendo que no escopo deste artigo, focou-se somente nas seguintes análises:
Análises das Estatísticas Textuais: fornece o número de textos e segmentos de textos, recorrências de frequência média das palavras, bem como a frequência total de cada forma, e sua classificação gramatical de acordo com o dicionário de formas reduzidas.
Classificação Hierárquica Descendente (CHD): representa um método proposto por Reinert (1990) que classifica os segmentos de texto em função dos seus respectivos vocabulários, sendo o conjunto deles repartido com base na frequência das formas reduzidas. Essa análise visa obter classes textuais que, ao mesmo tempo, apresentam um vocabulário de palavras semelhantes entre si, e um vocabulário diferente, contendo palavras de outras classes.
3.3 Corpus Textual
Segundo Camargo & Justo (2013) um corpus textual é um conjunto de textos, compilados pelo pesquisador, o qual representa o objeto de análise, que, por sua vez, pode ser constituído por um conjunto de artigos científicos publicados em um determinado período de tempo, pela transcrição de várias entrevistas sobre um determinado tema de estudo ou, ainda, por diversas respostas, para questões em aberto, de um questionário de pesquisa.
A construção do corpus representa a base de dados composta pelo conjunto de palavras selecionadas pelo pesquisador com o propósito de alimentar o software para viabilizar a realização das análises. O Iramuteq exige corpus com processador de texto com formato TXT e gravação no formato UTF-8, podendo ser utilizado o aplicativo para texto OpenOffice Writer ou o Bloco de Notas, disponível no Windows, sendo o Bloco de Notas o processador utilizado na presente pesquisa.
Seguem algumas regras que foram cuidadosamente adotadas para a construção do corpus textual:
No início de cada artigo utilizou-se a linha de programação do Iramuteq: **** *art 01 e, sucessivamente, para os demais artigos, art 02, art 03 ... art 11.
Efetuou-se uma limpeza em cada um dos textos, com a remoção de aspas, apóstrofo, cifrão, porcentagem, asterisco, reticências, travessão, negrito, itálico, grifo e outros sinais similares, assim como recuo de parágrafo, margens, tabulações e justificação do texto, sendo mantidos somente os símbolos permitidos: ponto, dois pontos, vírgula, interrogação e exclamação.
Formatação de texto todo corrido, sem mudança de linha.
Ajuste nas palavras compostas, que devem ser unidas por underline, mesmo aquelas unidas ortograficamente pelo hífen. Ex.: recém-casado, anti-inflamatório, Distrito Federal.
Eliminação de frases não condizentes com o assunto tratado.
Eliminação dos títulos e subtítulos dos artigos como: Introduction, Methodology, Literature Review, Conclusion.
Para uma melhor compreensão das análises realizadas pelo Iramuteq, considera-se importante compreender de que maneira o software realiza as análises: separando o corpus em segmentos de texto com tamanho de três linhas, as quais são dimensionadas pelo próprio software em função do tamanho do corpus. Esses segmentos são denominados “ambiente das palavras” e seu tamanho também pode ser configurado pelo pesquisador que, no presente estudo, considerou a formatação padrão do software. A Figura 2, abaixo, melhor apresenta as noções conceituais de ‘corpus’, ‘texto’ e ‘segmentos de texto’.

Fonte: Camargo e Justo (2013), adaptado pelos autores.
Segundo Camargo & Justo (2013) e Donadon (2018), para se estabelecer e compreender uma análise textual validada, é necessário explicitar conceitualmente esses norteadores utilizados:
Corpus: o conjunto de textos que se pretende analisar compilado, pelo Iramuteq, a partir do material selecionado na empresa, de acordo com as especificidades da mesma, sendo estas de porte (grande, média ou pequena), e de outros quesitos que determinam o diferencial no material a ser analisado;
Texto: cada um dos materiais compilados na entrevista o qual irá compor o corpus − se uma determinada análise diz respeito às respostas de “n” participantes a uma questão aberta, cada resposta será um texto, e teremos “n” textos;
Segmentos de texto: são partes do texto, na maioria das vezes em torno de três linhas, dimensionadas pelo próprio software. Assim, corpus, texto e segmentos de texto constituem o objeto de análise do Iramuteq.
Observa-se que o corpus representa o conjunto maior no qual está presente todos artigos, conjuntamente, o texto representa as partes dos segmentos de textos que serão processados pelo software.
3.4 Tratamento do Corpus no Iramuteq
Os 11 artigos selecionados em língua inglesa foram devidamente ajustados com as recomendações do item 3.3 e compilados em um corpus textual válido para servir de base de entrada de dados para o Iramuteq. Utilizou-se como critério de seleção dos artigos as palavras-chave de busca nas bases de dados: social resposability, fuzzy.
Realizaram-se diversos testes de validação, inclusive, com a limpeza e exclusão de palavras para que o resultado final da Análise de Similitude e Nuvem de Palavras tivessem uma apresentação gráfica bastante significativa e de interpretação consistente; desse modo, o melhor resultado obtido foi com palavras que apresentaram recorrência com frequências acima de 60, nos 11 textos analisados, para ambas as pesquisas. A tabela 2, abaixo, apresenta os 11 artigos selecionados e analisados, com uma abrangência em diversos países em aderência com o objetivo do presente estudo.

Fonte: elaborado pelos autores.
Observam-se artigos aderentes à temática pesquisada de responsabilidade social nas relações do trabalho com a utilização da metodologia fuzzy, e sua distribuição geográfica global.
4.Resultados
Os resultados serão apresentados e discutidos, concomitantemente, à medida que os resultados do software Iramuteq são extraídos.
4.1 Análises Estatísticas Dos Dados
As estatísticas básicas da análise trazem informações sobre o Resumo das análises, sendo:
Número de textos analisados: 11
Número de ocorrências: 54.002
Número de formas: 4.544
Número hápax (palavras aparecem só uma vez): 2.050
Médias das ocorrências no texto: 4.909,27
Essas estatísticas básicas servem, essencialmente, para uma visualização geral do corpus que está sendo analisado. Nota-se ainda que um importante gráfico estatístico relaciona, no eixo das abcissas, os logaritmos das frequências das palavras por ordem decrescente e, no eixo das ordenadas, as frequências das formas, como podem ser visualizadas na Figura 3.
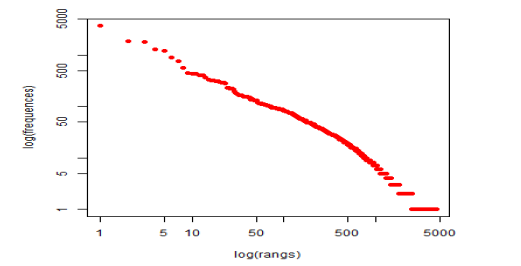
Fonte: fornecido pelo software Iramuteq.
Esse gráfico tem relevância para a validação da consistência da análise do corpus, tendo em vista que para uma análise ser considerada consistente, o gráfico precisa apresentar em uma aproximação de uma reta linear descendente do tipo y = -ax + b. Na presente situação, o gráfico apresenta-se plenamente ajustado, o que valida estatisticamente o corpus analisado.
4.2 Classificação Hierárquica Descendente
O método de Classificação Hierárquica Descendente (CHD), proposto por Reinert (1990), classifica os segmentos de texto em função de seus respectivos vocabulários, sendo que o conjunto destes é separado com base na frequência das formas reduzidas. Busca-se obter classes que apresentam vocabulários semelhantes entre si assim como os segmentos de texto associados a cada uma das classes, e, ainda, palavras estatisticamente significativas, o que possibilita uma análise mais qualitativa dos dados (Camargo & Justo, 2013).
Os resultados da aplicação do Método Reinert no Iramuteq fazem emergir inicialmente as seguintes informações básicas:
Número de Textos:11
Número de textos segmentados: 1.497
Número de formas: 5.560
Número de ocorrências: 54.002
Número de formas ativas: 3.974
Número de formas suplementares: 570
Número de segmentos aproveitados para análise:1.129
Número de segmentos classificados 1.129 em um total de 1.497, que representa um percentual de aproveitamento 75,42%
Segundo Camargo & Justo (2013), faz-se necessário um aproveitamento de mínimo de 70% nos segmentos classificados para validação da análise, uma vez que um aproveitamento de segmentos abaixo deste mínimo indica baixa representatividade do material para análise no Iramuteq.
Após o processamento no Iramuteq, o CDH cria um dendrograma das classes que além de fazer uma apresentação das diferentes classes encontradas, demonstra ligação entre elas, ou seja, as suas associações. O dendrograma é apresentado na Figura 4 com as classes que emergem da análise CDH do corpus textual, sendo quatro classes em diferentes cores.

Fonte: fornecido pelo software Iramuteq.
Este dendrograma, mostra que o corpus foi dividido em dois subcorpora: o primeiro com as classes 1 e 3, sendo a classe 1 de cor vermelha, com 28,20% do total, e a classe 3 de coloração azul clara, com 21,20%. O segundo agrupamento se apresenta composto pelas classes 2 e 4, sendo a classe 2 de cor verde clara que representa 27,40%, e ainda a classe 4, de cor azul escura, com 23,20% do total.
Essas classes representam o agrupamento das palavras encontradas nos 11 textos que compõem o corpus textual da presente pesquisa. O Iramuteq possibilita, ainda, um outro tipo de dendrograma que complementa a Figura 4, o qual permite um detalhamento da análise uma vez que aponta as palavras mais representativas em cada uma das classes cuja demonstração se dá em ordem decrescente, sendo classificada por meio de uma visualização por tamanho a qual revela o grau de frequência com que essas palavras se manifestam no corpus.
Esse nítido detalhamento pode ser visualizado na Figura 5 na qual se deve observar a inexistência de uma prevalência de qualquer das classes criadas pelo Iramuteq, sobre as demais; pode-se notar, ainda, que na presente pesquisa existe um equilíbrio entre as classes, ficando na faixa de 20%.

Fonte: fornecido pelo software Iramuteq.
A partir do dendrograma acima detalhado são visualizadas as palavras que obtiveram maior percentual, em relação à frequência média entre si e à diferença entre elas.
Na Figura 6, abaixo, o Iramuteq apresenta as mesmas quatro faixas, que emergem da análise do software, sendo que em cada uma das faixas visualiza-se uma Nuvem de Palavras, com ênfase no tamanho das palavras, com maior frequência, que, por sua vez, são demonstradas nos textos que compõem o corpus analisado.

Fonte: fornecido pelo software Iramuteq.
A Figura 6 acima produz uma forma diferente de apresentar as palavras mais representativas em cada uma das classes extraídas pelo software, podendo ser visualizadas, em cada uma das classes, uma nuvem de palavras na qual as palavras ganham realce de tamanho em função da sua frequência de ocorrência.
O primeiro grupo, composto pelas classes 1 e 3, traz as seguintes palavras mais representativas a partir das nuvens de palavras:
Na Classe 1, vermelha, observa-se as seguintes palavras relevantes: social, responsability, sustentability, corporate, organization.
Na Classe 3, azul-clara, constam as seguintes palavras: driver, source, practice.
No segundo grupo das classes 2 e 4, as palavras que têm maior relevância, são:
Na Classe 2, verde clara: fuzzy, expert, method, score, membership.
Na Classe 4, azul escura, têm-se as palavras: hub, network, objective, speak, node.
A apresentação da Figura 7 em conjunto com a Figura 6 demonstra o processo que permite a inferência de nomes para as classes extraídas do software. A Análise Fatorial por Correspondência (AFC) é uma representação gráfica dos dados para ajudar na visualização da proximidade entre classes ou palavras.
O Iramuteq ainda viabiliza a Análise Fatorial por Correspondência (AFC): uma representação gráfica dos dados que ajuda na visualização da proximidade entre classes e palavras. A Figura 7, que foi gerada pelo software, apresenta as quatro classes extraídas com suas palavras-chave de relevância, com o agrupamento e destaque das palavras com maior frequência para cada uma das classes, e, ainda, de que maneira as quatro classes encontram-se relacionadas umas com as outras.
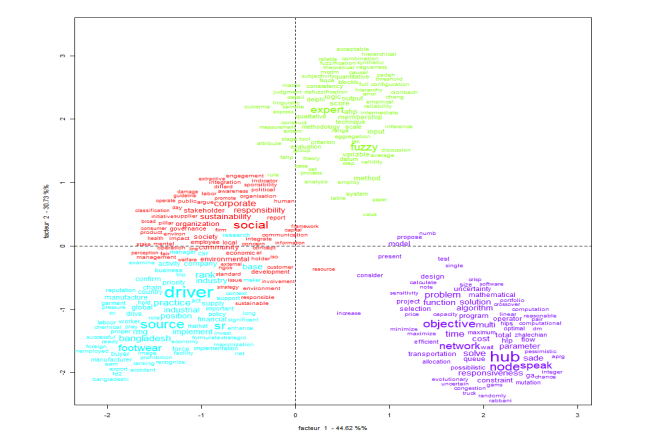
Fonte: fornecido pelo software Iramuteq.
4.3 Análise De Similitude
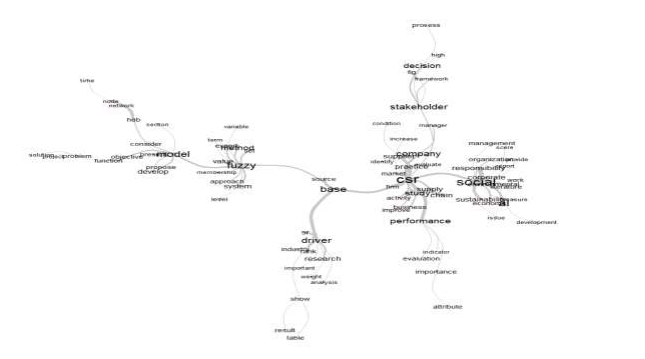
As figuras geradas denominadas “Árvore de Similitude” ou “Árvore de Semelhança” caracterizam-se pela apresentação de um desenho no formato de uma árvore e suas respectivas ramificações nas quais o resultado mostra-se representado por uma interface de interação e comunicação entre as distintas partes envolvidas e suas conexões. As Figuras 8 e 9 trazem a mesma demonstração do resultado de Similitude, sendo que a Figura 8, com a criação de um halo colorido que agrupa as palavras similares em conjuntos de proximidade, possibilita uma melhor visualização desse agrupamento; a Figura 9 apresenta a mesma similitude, mas sem os respectivos halos de agrupamento.
Com a finalidade de melhorar a visualização da Árvore de Similitude, realizou-se uma filtragem no registro da frequência das palavras com maior recorrência de apresentação, optando-se por classificar somente aquelas com mais de 20 repetições para, desse modo, melhorar o aspecto classificatório em relação à expressão das mesmas nas suas concorrências e correlações ao longo dos textos analisados.
Na Árvore de Similitude da Figura 8, que corresponde à apresentação com halos de agrupamento, observa-se cinco halos, sendo o halo amarelo a raiz principal, com a predominância da palavra CSR, Corporate Social Responsability; a partir deste centro irradiam três outros halos:
Azul claro, com prevalência das palavras stakeholders, decision e process;
Verde, contendo social, corporate e development;
Azul escuro, com driver e base.
A partir do halo azul escuro, cria-se um novo halo de cor rosa, indicando as palavras com maior frequência correlacionadas com fuzzy e method. Finalmente, um halo de cor laranja proveniente do halo azul escuro, agrupa-se às seguintes palavras: model, propose e problem.
A construção desses halos é importante na análise do conteúdo extraído a partir do processamento do Iramuteq, pois permitem uma visualização do agrupamento, do modo que as palavras de maior frequência nos textos selecionados estão se relacionando entre si, de que maneira elas se agrupam e, por fim, como esse grupo de palavras se conectam.
A Figura 8, onde é apresentada a Árvore de Similitude com a presença dos halos, traz os mesmos resultados da Figura anterior, sendo que o agrupamento com os halos permite uma ampla e clara visualização gráfica do agrupamento das palavras e suas conexões.

Fonte: fornecido pelo software Iramuteq.
A Figura 8 deve ser analisada por meio da interface (área em que os vocábulos do corpus textual temático interagem e agrupam-se com maior ou menor intensidade); as diferentes cores possibilitam uma melhor visualização desses agrupamentos de palavras. O resultado ainda deve ser compreendido pelo tamanho dos vértices coloridos assim como o tamanho das próprias palavras, que estão em proporcionalidade com a frequência das palavras nos textos analisados, indicando não só a força das concorrências entre os vocábulos, mas, principalmente, como os seis agrupamentos se relacionam.
Nesse tipo de apresentação gráfica da Análise de Similitude com halos coloridos a intensidade da cor (mais acentuada ou mais leve) e a própria espessura dos traços que unem as palavras na imagem apresentada contêm discursos subliminares com significados que determinam a indicação da conectividade, que, por sua vez, contribui para a identificação de toda estrutura do próprio corpus analisado.
A Figura 9 apresenta a mesma Análise de Similitude da Figura 8, sem os respectivos halos coloridos.
Fonte: fornecido pelo software Iramuteq.
A Árvore de Similitude, extraída do software, sem os halos coloridos, mostra as mesmas relações da Figura 8; entretanto na Figura 9, não existe um agrupamento por halos e tem-se uma visualização apenas das conexões existentes entre as palavras.
4.4 Análise Por Nuvem De Palavras
O resultado da Nuvem de Palavras pode ser visualizado na Figura 10 e representa uma organização pelo agrupamento das palavras encontradas nos textos em função da frequência com que essas palavras aparecem; presenta-se como uma análise lexical simples, porém, graficamente, muito relevante já que permite uma rápida identificação das palavras-chave do corpus textual analisado.

Fonte: fornecido pelo software Iramuteq.
Observa-se, na nuvem de palavras, a prevalência das palavras: fuzzy, social, driver, stakeholders, corporate social responsability (csr).
Na Nuvem de Palavras apresentada na Figura anterior existe um alinhamento do discurso no contexto de todos os textos, de maneira que as palavras mais frequentes aparecem destacadas pelo tamanho e coloração acentuada, o que demonstra a força da projeção dessas palavras em todos artigos que compuseram o corpus textual.
Nesse resultado da Nuvem de Palavras observa-se ainda o nível de correlação entre os vocábulos que têm maior frequência relativa, com destaque para fuzzy, social, corporate social responsability (csr), model, company, stakeholders, performance, sustainability, responsability, sendo esse o grupo de vocábulos que reforça os discursos predominantes nos textos analisados na presente pesquisa. A Nuvem de Palavras serve, inclusive, para corroborar os resultados obtidos anteriormente, na Análise de Similitude, pois ambas apresentam evidências na identificação de discursos semelhantes, o que comprova o rigor estatístico e metodológico do software Iramuteq, que é, ainda, validado pela otimização e organização dos dados assim como pelo resgate contextual apresentado.
Finalmente, a Análise de Similitude juntamente com a Nuvem de Palavras são, simultaneamente, realizadas com todo o rigor estatístico do software R e das análises feitas pelo Iramuteq, por meio das conexões apresentadas e identificadas nas Figuras geradas nos respectivos gráficos, validando os resultados obtidos pelas análises efetuadas.
5.Conclusões Finais
A motivação do presente estudo está associada pelo interesse em identificar os aspectos da utilização da lógica fuzzy para uma ampla compreensão da responsabilidade social nas relações do trabalho no mundo por meio de publicações científicas, do período entre 2013 e 2020, e da realização da análise de 11 artigos científicos publicados nessa temática.
A revisão bibliográfica faz emergir uma complexidade da responsabilidade social empresarial nas relações do trabalho e seus aspectos multidisciplinares correlatos, os quais abrangem os principais grupos de relacionamento social: empreendedores, acionistas, fornecedores, clientes, empregados e estado, bem como as inter-relações existentes nas dimensões do triple bottom line: econômica, social e ambiental.
O estudo traz uma abordagem qualitativa, com um processo continuo de validação dos dados, e tem um caráter exploratório para explicar o problema pesquisado, sendo que os procedimentos técnicos do estudo se restringem a uma pesquisa bibliográfica e documental, utilizando-se de uma análise de conteúdo ancorada nos 11 artigos científicos de periódicos selecionados.
À medida que se utiliza um software de análise como ferramenta básica, a pesquisa vai-se enquadrando no modelo de pesquisa denominado “descritivo” uma vez que exclui a interferência do pesquisador na análise dos dados coletados. A temática da responsabilidade social abordada nas relações do trabalho, ainda em processo de construção, consolida-se como uma importante vertente na temática mais ampla da responsabilidade social, assim como firma-se como um tema com abrangência não só nos países desenvolvidos, mas também nos países em desenvolvimento. Vale ressaltar a dificuldade na mensuração dessa responsabilidade nas empresas, e os benefícios da utilidade da metodologia fuzzy que possui os recursos adequados para tal finalidade.
A utilização do software de análise textual Iramuteq, como ferramenta de análise léxica, representa um diferencial no estudo na medida em que afasta qualquer interferência do pesquisador na análise de dados ao mesmo tempo que valoriza o papel do pesquisador na análise dos dados que emergem do software, cujo papel consiste em focar-se na interpretação dos autores (Camargo & Justo, 2013; Pinto, Mazieri, & Vils, 2017).
As restrições do estudo estão ligadas à subjetividade dos autores na escolha das palavras-chave de busca dos artigos selecionados e, ainda, na seleção final dos artigos para a composição do corpus textual de análise do software.
Deve-se entender ainda, como uma limitação ao presente estudo, as restrições dos resultados que emergem do software Iramuteq, os quais são apresentados de maneira padrão como: Dendrograma, Análise de Similitude e Nuvem de Palavras; tais restrições exigem um grande esforço por parte dos pesquisadores em apresentar conclusões que podem estar sujeitas a erros de interpretação ainda que se tenha optado por manter a língua inglesa original dos artigos como forma de manter a integridade dos artigos selecionados.
Existem novas linhas de pesquisa que se apresentam através do resultado do presente estudo, nomeadamente, nas vertentes voltadas para a mensuração de aspectos subjetivos como a mensuração da responsabilidade social nas relações do trabalho das empresas; a utilização de metodologias quantitativas como a lógica fuzzy está presente nesse esforço no sentido de melhor direcionar essas novas linhas pesquisa.
Pode-se, finalmente, concluir que o objetivo do presente estudo, desenvolvido por meio de uma revisão bibliográfica documental e exploratória, foi plenamente atingido e que o mesmo possibilitou identificar a utilização da lógica fuzzy como uma importante ferramenta para a mensuração da responsabilidade social nas relações do trabalho em diversos países, com significativo avanço como uma ferramenta quantitativa para se conseguir mensurar fatores estritamente qualitativos e, muitas vezes, subjetivos.
Concomitantemente, o software Iramuteq permite, com sua ancoragem em bases estatísticas R, convalidar esse tipo de utilização e fazer a mensuração quantitativa e qualitativa, nesse campo de estudo.

