










Serviços Personalizados
Journal
Artigo
 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkRevista Diacrítica
versão impressa ISSN 0807-8967
Diacrítica vol.26 no.1 Braga 2012
The inventory of oral stressed vowels in the Portuguese dialect of Graciosa, Azores
O inventário de vogais tónicas orais no falar da Ilha Graciosa, Açores, Portugal
Metodej Polasek*
*Univesidade Masaryk, Departamento Línguas e Literaturas Romanas, Brno, República Checa.
ABSTRACT
Each of the nine Azorean islands represents a specific speech community with a certain linguistic behavior which may or may not be analogous to the linguistic behaviors of other Azorean speech communities. The phonetic realization of stressed vowels constitutes its most important expression: there are more or less systematic changes of the vocalic timbres in relation to their standard Portuguese counterparts. This paper will describe acoustic properties of the stressed oral vowels in one particular Azorean speech community, the one of Graciosa Island, as well as the phonological processes which led to the shifts of the vocalic timbres of the stressed vowels in this particular dialect. It is a first step towards the main goal of the author: to develop a typology of the dialects, corresponding to individual islands, based on empirical acoustic data. One of the main issues is to find the most convenient method and instrumental tools for the study of particular dialects based on acoustic data.
Keywords: phonological processes, acoustic properties, stressed vowels, Azores, Graciosa.
RESUMO
Cada uma das nove ilhas do Arquipélago dos Açores representa uma comunidade linguística bem específica com um comportamento que pode ou não ser análogo a comportamentos linguísticos de outras comunidades açorianas. A realização fonética das vogais tónicas constitui a sua expressão mais importante: as mudanças mais ou menos sistemáticas dos timbres vocálicos relativamente aos seus equivalentes em português padrão. Este artigo apresentará propriedades acústicas das vogais tónicas orais numa determinada comunidade linguística insular portuguesa, a da Ilha Graciosa, bem como os processos fonológicos que levaram às mudanças dos timbres das vogais tónicas neste concreto dialeto. Trata-se da primeira etapa de um projeto do autor: desenvolver uma tipologia dos dialetos, correspondente ao vocalismo tónico de cada ilha em particular, com base em dados acústicos empíricos. Uma das principais preocupações nesta fase é a de encontrar a melhor metodologia possível, empregando os recursos atuais da fonética instrumental.
Palavras-chave: processos fonológicos, propriedades acústicas, vogais tónicas, Açores, Graciosa.
1. Introduction
According to the Ladefoged and Broadbents (1957) classification, with the denominations adopted from Adank (2003), there are three sources which cause the variance in the acoustic properties of each phonetic realization: phonemic variation (vowel-related variance; it is the most substantial source), anatomical/physiological variation (individual variation which originates from the differences between speakers in the shape and size of their vocal tract and larynx) and sociolinguistic variation (it originates from differences in social characteristics of speakers such as social background, educational level, age and gender). The anatomical/physiological variation and the sociolinguistic variation are speaker-related and their acoustic consequences need to be eliminated, at least partially, in order to enable us to compare the phonetic standards across speech communities. The regional background is the only aspect of sociolinguistic variation which is relevant for our study of the Azorean Insular dialects.
The present paper introduces a pilot research which was carried out by the author at the University Masaryk in Czech Republic in the area of acoustic phonetics applied to the Portuguese dialectology. The structure of this paper is as follows: the goals of the paper and the parameters and methods of the research are described in the first two sections. A special attention is given to the right choice and set-up of the tools of instrumental phonology which can be used for the analysis of vocalic formants. The inventories of the stressed vowels in the Standard European Portuguese and in the dialect of Graciosa are then compared. In the following section it is necessary to introduce the phenomenon of metaphony which is responsible for the partial re-organization of the vocalic system in Graciosa. Finally, a detailed overview of the phonetic realization of alternating stressed vowels in the dialect of Graciosa is provided in order to demonstrate the driving-forces of metaphony.
I would like to acknowledge the researchers of Centro de Linguística of the Lisbon University, especially Mr. João Saramago, and my coordinator, Mrs. Iva Svobodová, for their valuable support and motivation.
2. Goals
The aims of this paper are (i) to identify acoustic properties of the stressed oral vowels in the Graciosa dialect; (ii) to investigate the phonological processes which led to the shifts of the vocalic timbres of the stressed vowels in the dialect of Graciosa; and (iii) to find the most convenient methodological and instrumental tools for the study of particular dialects based on free speech recordings.
This paper is in fact a first step towards the main goal of the author: to treat the Azorean Insular dialects as an integral whole, to bring a concise description of the Azorean stressed vowels and to develop the typology of the dialects, corresponding to individual islands, based on empirical acoustic data. I share the opinion of Ladefoged (1988) that one of the tasks of phonological theory is to help to explain why languages have the sounds that they do. That is why the phonological theory is seen as a powerful tool to reach the objectives as just mentioned and will be employed more in the later stage of the project. This paper resorts mainly to the methods of induction and abstraction which facilitate the design of the system of oral stressed vowels in the Portuguese dialect of Graciosa.
The unstressed and nasal vowels were not comprehended in this study for the following reasons. According to Generative Phonology unstressed vowels are derived from the stressed ones by phonological processes - general rules of a vowel reduction of the stressed vowels. What the nasal vowels concerns, Generative Phonology also does not count with them in the deep structure and argues that, at the underlying level, nasal vowels are sequences of oral vowels followed by a nasal consonant (Mateus, Andrade, 2000). This hypothesis seems to be confirmed by a group of researchers from the University of Aveiro (Teixeira, Moutinho, Coimbra, 2003) who subjected the height of the European Portuguese Nasal Vowels to three different phonetic measurements. One of their conclusions is that the tongue height at beginning and end in velar stop contexts is dictated by the consonants[1]. The above mentioned approach of Generative Phonology might be the reason why the authors of acoustic descriptions of vowels in European Portuguese which serve as a reference for this paper[2] took only the stressed oral vowels and subjected them to a phonetic analysis.
3. Speech material and acoustic measurements
The present paper uses the speech material collected by the author in Graciosa in autumn 2008. The speech data was obtained from two informants (they will be labeled as Gr1 and Gr2) belonging to the subsection of the Graciosa population which is supposed to be the most conservative one. They are both male, more than 55 years old (Gr1 is 60 and Gr2 is 57 years old) and were born on the island (Gr1 in Fenais, municipality of Praia, Gr2 in Luz, municipality of Luz, both located in the Southern part of Graciosa Island, on the opposite side from Santa Cruz de Graciosa which is the cultural-political centre of Graciosa). From the socio-economic point of view they belong to the average group, lower rather than higher class, active in the primary sector (cultivation of vegetables and corn for own consumption only, together with cattle and hog breeding for own consumption or occasional sale) with the property of a country house and a small pasture area. Their education is limited however standard for the vast majority of the population of the same age in Graciosa: primary four-year classes. The uniformity of sociolinguistic variables valid for both informants eliminates sociolinguistic variation across the data set.
The data set which I use consists of 429 stressed vowel tokens (221 of them were obtained from Gr1, 208 from Gr2), extracted from two types of recorded conversations: free conversation and elicited conversation or so called sociolinguistic interview with the questionnaire containing all phonemes in various phonetic contexts. The intention of the elicited conversation was to stimulate the informant to pronounce the desired word but in the most natural way possible. This is in order to minimize the risk that the informants would autocorrect their pronunciation by eliminating vernacular features from their speech. The methodology of the speech data collection used by Delgado Martins (1988) and by Escudero, Boersma, Rauber, Bion (2009)[3] was not applicable for this fieldwork[4] because the characteristic phonetic phenomena of the dialect of Graciosa is retrievable only from the free speech. As previously mentioned, the data set consists of 429 stressed vowel tokens pronounced by two informants. The number of informants will need to be increased in the later phase of the project in order to eliminate more the negative effects of a possible anatomical/physiological variation of the data set.
First of all the recorded conversations had to be segmented to short sound files containing one word or a short sequence of words which facilitated an easier treatment of recordings[5]. The realizations of stressed vowel tokens selected from the short sound files were subjected to acoustic measurements in order to obtain the first three vowel formants (F1, F2 and F3) as basic acoustic characteristics of each vowel token. Due to the fact that the acoustic research of stressed oral vowels of Graciosa Portuguese represents a pivot research for the project mentioned above, two programs were used for formant measurements using the same set of vowel data. All 429 stressed vowel tokens were thus measured twice, once using SpeechStation2 and once Praat. The purpose of this double work is to obtain the possibility of choice of the most user-friendly and the most exact software for our goals. In both cases the measured signal was selected manually making sure that the surrounding speech sounds were not audible in the remaining signal[6]. All tokens were classified according to their acoustic properties into the phonemic groups and the mean value was calculated for each phoneme and for each informant separately, in both programs. The final values which in a certain way represent standards of stressed vowel in GP were calculated as an average of the phonemic values calculated for each informant. Also in this case we obtained two different pairs of values depending on the program used for the acoustic measurements.
The phonetic program SpeechStation developed by Sensimetrics Corp. is used by some researchers in the field of Portuguese phonetics (like Bernardo for her study on the Portuguese of São Miguel, 2003). Its second edition, SpeechStation2, offers the possibility to measure formants of selected parts of signal in three different modes: as single spectrum (measurement in one point of the spectrum), multiple spectra (spectra in different moments can be chosen for contrastive analysis) and average spectrum (the programs calculate the average of the values across the selected sequence). The values obtained by any of these modes need to be assessed manually from the Spectrum Viewer screen. Therefore it is difficult to collect values other than F1, F2 or F3. Several settings need to be chosen before the measurements can start: analysis mode, window size and type and LPC order. The recommendations from the manual were followed and the following setting was applied for this pivot research: LPC analysis mode with the order 26, the window size 256 for the signals of sample rate 22 kHz. The pre-emphasis filter was activated. Even if the chosen set of settings assured more exact results than if the settings had remained default, the values obtained were scaled by 9Hz, a fact which did not assure the required accuracy of our measurements. In order to minimize the undesired effect of imprecision of the data collection, the mode of average spectrum was chosen. This mode offers the possibility to abstract from any fluctuation of the single values of formants across the selection of the signal by calculating the average frequency of each formant in the interval between the start and the end of selection. On the other hand the result is apparently more sensitive to phonetic surroundings of the measured stressed vowel. The use of the average spectrum mode could have therefore led in some cases to a distortion of the formant values compared to the measurements made in single spectrum mode. The single spectrum is considered to be standard, at least by the Portuguese acoustic researchers, due to the tradition: there was simply no possibility to get a mean formant value for a part of vowel signal before the digital signal processing came into use in the speech analysis.
The second phonetic program, Praat, developed by Paul Boersma and David Weenink, University of Amsterdam, is used worldwide for obtaining formant measurements. Praat differs from Speech Station2 in important respects. Formant measurements can be obtained semi-automatically: the user selects manually the part of signal which needs to be measured (the totality of the vowel signal without a transition part at the beginning and at the end of the signal) and the program uses its algorithm to extract the values of first five formants (F1-F5) at each vowel tokens temporal midpoint. Prior to the formant measurements the selected signal needs to be placed at zero crossings. Praat, in contrast to Speech Station2, is able to extract the fundamental frequency (F0) for each token, too. The single values of the selected formant appear in a separate window given in Hz with twelve decimals[7]; our results are rounded to two decimals. The default setting of the program to measure the formants right in the middle of selected signals is advantageous: the temporal midpoint of the signal is the most representative point for a formant frequency assessment not only if the frequency of formants is approximately constant across the selected signal but also in the cases where the course of one or more formants has a convex or concave shape. The analogous spectrographs were previously also used for measurements of frequencies in the middle of the signal where the formants had a constant value, and if there were no such parts of the signal available, then the conjunctional frequency values (in the temporal midpoint) of each vowel token were assessed. The output of the measurements made in Praat is in this respect comparable to the values obtained in the traditional way in the past. There was no need to change the default settings of the program or even search for modes other than single spectrum measurements (if I am right there is even no average spectrum mode available). Praat´s biggest advantage is without doubt the semi-automatically measuring which could save the researcher a lot of effort. The values obtained by both programs will be compared in later sections.
To my knowledge, the phonetic properties of all stressed vowels in the dialect of Graciosa (called as Graciosense in Portuguese, later in this text designated as GP only) have never been subjected to acoustic measurements. The acoustic analysis is, without doubt, crucial for the comprehension of the whole system, though. It is convenient to allude to the inventory of stressed vowels in Standard European Portuguese (later designated as SEP only) before the inventory of stressed vowels in GP is engaged.
4. Vocalic inventory of Standard European Portuguese (SEP)
Delgado-Martins, Portuguese linguist, published the first acoustic analysis of stressed vowels in SEP in 1973 and her data representing the mean values for each stressed vowel obtained from eight high-school educated male informants from Lisbon[8] became a reference study for all later acoustic researches in the field of European Portuguese. On the other hand, the most recent study on acoustic properties of stressed oral vowels was published in 2009 by the international team of researchers leaded by Escudero[9]. The aim of their paper is to examine four acoustic correlates of vowel identity in Brazilian Portuguese (BP) and European Portuguese (EP): first formant (F1), second formant (F2), duration, and fundamental frequency (F0). This time the acoustic analysis was not limited to the male population only. These two studies provide us with precious information concerning the stressed vowels in SEP but their formant measurements are not directly comparable to the acoustic analysis of stressed vowels in GP presented in this paper. The reason is simple: the data collection method employed in both above mentioned reference studies, the carrier sentence reading, is different from the way how the data was collected for the analysis presented in the present paper, as it has been said before.
The vocalic inventory of SEP in stressed position consists of eight vowels[10] and has a triangular configuration in the F1-F2 (first and second formants, respectively) vowel plot where the frequencies of F1 represent the level of openness of the single vowels and the F2 gives us the information about backness or better: how much the tongue root is advanced or retracted (the feature ATR/RTR[11]) during vowel articulation (see Graph 1). The presence or absence of labialization and its level also has impact on the localization of single vowels in the F1-F2 plot, influencing both F1 and F2. The vowel /a/ represents the peak of the triangle on the F1 axis (as it is the only open vowel in the inventory) and the remaining vowels are distributed in pairs along the F1 axis (except from the central vowel [?] which is a special segment standing apart of the phonological matrix of Portuguese) with different distances between the constituents of the pairs. The changing distance between the pair constituents as well as their specific localization in relation to the peak of the triangle is caused by F2. The number of levels of openness and of ATR/RTR depends on how detailed is the acoustic description of the vocalic inventory of SEP. We take over five levels of openness from Tláskal (2006) and for SEP we distinguish only three levels of ATR/RTR.
Table 1 – Vocalic inventory of SEP in stress position
| Front | Central | Back | |
| Close | /i/ | /u/ | |
| Close-mid | /e/ | /o/ | |
| Central | /ɛ/ | /ɔ/ | |
| Open-mid | [ɐ] | ||
| Open | /a/ |
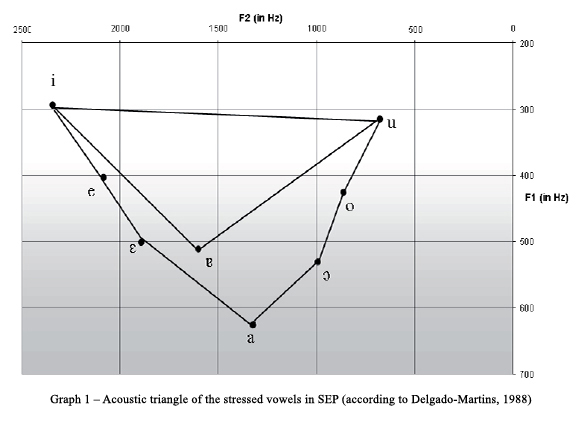
The existence of the phoneme /ɐ?/ is questionable, that is why I prefer to mark the vowel in the text with square brackets ([ɐ?;]). Generative Phonology presumes that this vowel is no phonemic segment because it has been transformed through phonological processes impacting the phoneme /a/ (Mateus, 1990). Its appearance in the context is very restricted and predictable as demonstrates Fikkert (2005). In my view it is a segment which is still a part of the inventory of stressed oral vowels of Portuguese at least from the phonetic point of view. In addition it does not impact the internal symmetry of the vowel inventory in SEP. That is why it will be comprehended in the acoustic analysis of the present paper[12].
5. Vocalic inventory of Graciosa Portuguese (GP)
The vocalic inventory of GP in stressed position is more complex than that which we have seen in the case of SEP. Along with the eight vowels habitual for SEP there are three additional segments ([ɑ, œ, i]) which will be called mixed vowels in this paper. This term was introduced by the Swiss-born doctor and linguist Conrad Amman in the 17th century[13] and stands for the German /ü, ö, ä/ which he interpreted as mixtures of /e/ with /u/, /o/ and /a/ respectively. The term is used in the present by some Portuguese authors like Santos (2003) because, similar to the above mentioned German vowels, the vowels [ɑ, œ, i] seem to combine, in a certain way, the acoustic properties of segments habitual for SEP. If we look at the F1 and F2 values obtained for the GP vowels captured in Graph 2, [ɑ] stands between [a] and [ɔ]; [œ] is situated between [e] and [o]; and [i] is approximately one quarter of the distance from [i] to [u].

Graph 2 shows the formant mean values of the stressed vowels in GP in the F1-F2 plot. First of all it enables us to classify the vowels according to their openness and the ATR/RTR feature. The way in which front vowels are organized in the F2 axis is still not relevant to us. We will keep them all in a common category called Front. One category for central vowels is also enough even if the category Central gains two more segments. For the purposes of a later analysis of certain phonological phenomena in GP it is nevertheless crucial to subcategorize the group Back in two levels of RTR of stressed vowels. They are, according to the mean F2 values of collected stressed vowel utterances, as follows: Back1 ([ɑ], /ɔ/) and Back 2 (/o/, /u/) where the members of the category Back2 have a more posterior pronunciation than those belonging to Back1. Table 2 summarizes our classification.
Table 2 – Vocalic inventory of GP in stressed position
| Front | Central | Back 1 | Back 2 | |
| Close | /i/ | [i] | /u/ | |
| Close-mid | /e/ | [œ] | /o/ | |
| Central | /ɛ/ | /ɔ/ | ||
| Open-mid | [ɐ?] | [ɑ] | ||
| Open | /a/ |
As we can deduce from Graph 2, there are two series of stressed vowels in GP; let us call them sub-inventories. The first one corresponds to the stressed vowel inventory SEP and we call it Stressed vowels before metaphonic shift. It contains seven[14] vowels (/a, ɛ, e, i, ɔ, o, u/) which represent an input for the metaphonic shift. I will explain later what metaphonic shift means. The second sub-inventory represents Stressed vowels after metaphonic shift and it amounts to four vowels (/ɑ, œ, i, o/). These segments appear exclusively in stressed position (obviously except from /o/). Each stressed vowel after metaphonic shift has its own counterpart (or two) in the other sub-inventory creating stressed vowel pairs: [ɑ] and /a/; /[œ] and /e/ + /ɛ/; [i] and /i/; [o] and /ɔ/ + /o/. The stressed vowel /o/ is specific because it belongs to both sub-inventories. In other words it does not have distinct acoustic properties as a stressed vowel before and after metaphonic shift.
5.1 Stressed vowels before metaphonic shift
The eight vowels habitual for SEP have similar acoustic characteristics in GP as the corresponding stressed vowels in SEP. We have subjected them to acoustic comparisons on the basis of their formant frequencies (F1 and F2) having in mind that the acoustic characteristics available for SEP and GP are not completely comparable due to the difference in the data collection methods (as explained in the section 3 of the present paper). The result is shown in Graph 3. The major discrepancies in relation to SEP which were observed are:
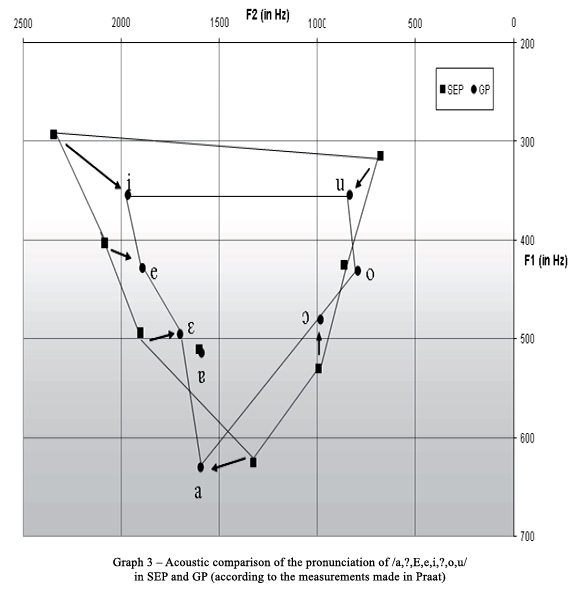
In F1:
More open pronunciation of close vowels /i/ and /u/ and slightly also of /a, ɛ, e, ɔ;, o/.
In F2:
More posterior pronunciation of front vowels /i/, /e/ and /ɛ/.
More front pronunciation of /a/ and /u/.
According to my hypothesis these light modifications in pronunciation of the Stressed vowels before metaphonic shift do not happen incidentally in GP and have their explanation in the existence of the second sub-inventory: Stressed vowels after metaphonic shift. The front vowels [i], [e] move towards the place of the pronunciation of their counterparts [i] and [œ] because otherwise their distance in Hz along the F2 axis would be too large (it is in fact a timbre assimilation). The localization of the central vowel [a] in the F1-F2 plot seems to change for the opposite reason: it is moving in the opposite direction from where [ɑ] is lying (it is rather a timbre dissimilation). In other words, the way in which the formant mean values of [i, œ, ɑ] are organized in Graph 2 is reflected in the disposition of [i, e, a]. On the other hand, the stressed vowels which do not have counterparts among the stressed vowels after metaphonic shift (in the case of [ɐ?]) or do not constitute a pair with a mixed vowel ([ɔ] and [o]), do not show any significant timbre shift, at least compared to the aforementioned shifts. The significant change in the pronunciation of [u], which also does not have any counterpart among the stressed vowels after metaphonic shift, is therefore unclear. Its lower pronunciation might be analogous to the higher level of openness of the remaining close vowels in GR compared to the standard of SEP.
5.2 Stressed vowels after metaphonic shift
Metaphony, according to The Encyclopedia of Language and Linguistics, is a phonetically motivated change due to the quality of a nearby segment[15] and it is traditionally called umlaut in German and English linguistic tradition. In our case the affected segment is the stressed vowel and the nearby segment is represented by the unstressed back vowel /u/ in final position (phonetically prominent or hidden in surface structure). Thus it is considered to be regressive assimilation consisting of a change of the vowel timbre (vowel harmony). The motivation for this is according to the proposal of Walker (2006) as regards perceptual markedness: metaphony improves perceptibility of height feature(s) in a vowel that is perceptually difficult (or perceptually marked) by causing them to also be expressed in a stressed syllable[16].
Dillon (2003) proposes another approach to metaphony, rather than the commonly adopted opinion that it is a kind of vowel harmony: The primary impetus for a change in the stem vowel is realization of a morpheme. That is, morpheme realization is the motivation for metaphony, and assimilation of the stem vowel to the final vowel happens to be to the means of morpheme realization[17]. It means that, according to Dillon, metaphony is not phonologically but a morphologically driven phenomenon. She employs Optimality Theory (Prince and Smolensky, 1993/2002; Kager, 1999) as a framework for the selection of the best output satisfying a set of phonological constraints and combines it with the Realizational Morpheme Theory (Kurisu, 2001) which provides a method of accounting for morpho-phonological phenomena. In two cases of Romance metaphony[18] she explains that metaphony should be seen as double morphemic exponence in which the input affix morpheme is phonologically realized both as a suffix and as a change in the stem[19] instead of as a vowel harmony.
The phenomenon of metaphony is, as we already anticipated, by no means limited to GP and other Insular Portuguese dialects but it can also be found in a few vernaculars of the Romance languages, such as in Sardinian, in some dialects spoken in Marche, Friuli and Central Veneto in Italy, in the dialect of Asturias in Spain and in certain dialects of Romania and Brazil[20]. The stressed input /a/ surfaces as [ɑ] or even as [ɔ] also in the Portuguese Creole dialect of Cabo Verde[21]. The highest occurrence and regularity of metaphony in Insular Portuguese dialects is believed to be present in Graciosa[22].
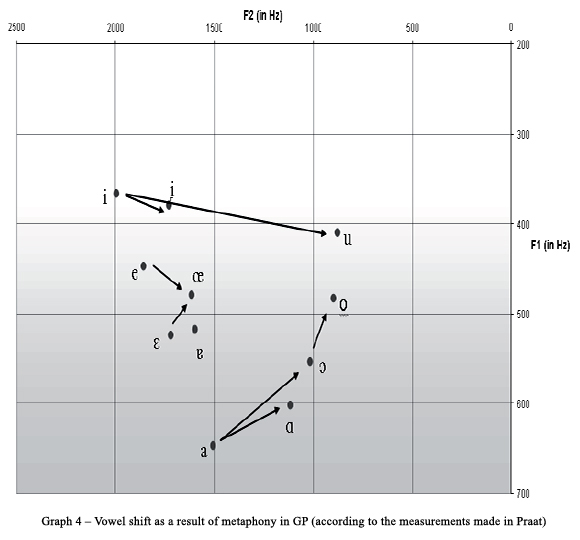
The phonemes which are subject to metaphony in GP are /a, e, ɛ, i, and ɔ/ - we will denominate these vowels as Metaphony Sensitive Phonemes (see Graph 4). In the context of the final unstressed vowel /u/ these vowels are shifted in the following way:
/a/ shifts to one of two possible allophones:
→ [ɑ] with higher and more posterior pronunciation than [a]
→[ɔ] with higher and more posterior pronunciation than [a] and with higher pronunciation than [ɑ]
/e/ → [œ] with slightly higher and more posterior pronunciation than [e]
/ɛ/ [œ] with higher and more posterior pronunciation than [ɛ]
/i/ shifts to one of two possible allophones:
→ [i] with more posterior pronunciation than [i]
→ [u] with more posterior pronunciation than [i] and with even more posterior pronunciation than [i] - rather exceptionally
/ɔ/ → [o] with higher and more posterior pronunciation than [ɔ]
As one may see the output of the metaphony shift in GP constitutes mainly mixed vowels, a fact which is rare compared to the mentioned dialects of Italian and Spanish where the output is constituted by the occurrence of standard phonemes[23]. The only exception is the process of metaphony with the input /ɔ/ which simply gets closed (the output then becomes [o]). Even if much less regularly, GP also knows the shift towards the standard phonemes in the case of the input /a/ (which is transformed to [ɔ]) and /i/ (the output is [u]). As we have seen such utterances constitute allophones for mixed vowels [ɑ][24] and [i], respectively. The data set which was subject to the acoustic measurements has proved that the mixed variants have a significant majority. For example [u] appears only in approximately 10%[25] of cases in metaphony with /i/ as input. The case of the metaphony with /a/ as input is more complex because the single realizations of [ɑ] and [ɔ] have very similar acoustic properties and it is not worthwhile (if it is possible at all) insisting on the establishment of an acoustic limit between the phonemes [ɑ] and [ɔ]. However, merely the fact that the mixed outcomes [i] and [ɑ], so characteristic of GP, have their allophones in [ɔ] and [u], opens a space for the hypothesis that the phoneme /ɑ/ constitutes a transition stage in a diachronic change of /a/ to /ɔ;/. The phoneme /i/ is then a step between /i/ and /u/. The situation in other speech communities where the metaphony is registered might support this hypothesis. An overview of all possible outputs of Graciosa metaphony with examples is shown below.
As regards the sound context, it is worth mentioning that the presence of the palatal glide [j] following immediately after the stressed vowel (thereby creating a diphthong) is not an objection for the realization of metaphony. I encountered it attached to the stressed vowel [œ] (dinheiro money). No glide was attested following [ɑ] because the diphthong ai [aj], normal in Standard Portuguese, is pronounced monophthongized in Graciosa, for example in baixo ['bɑʃ] low.
Graph 4 and Table 3 show clearly that metaphony in GP is above all a change of the stressed vowels in the direction front-back (ATR-RTR) triggered by a back final unstressed [u]. This is very important to highlight because the metaphony observed in the remembered dialects of Italian and Spanish has a different input-output correspondence: the final unstressed vowel (which is high and back at the same time) triggers a change in the height of the stressed vowel. The metaphony present in GP results also in raised vowels in some cases (when the inputs are /a, ɛ, ɔ;/), but obviously it is not common for all input-output relations, in contrast to RTR.
Table 3 – Vowel shift as a result of metaphony in GP
| Metaphonic Input | Metaphonic Output | Phoneme surfaces as | Shift in direction | Sound context | Example | Example pronunciation | Gloss |
| Stressed central open | Stressed back1 open-mid | /a/ → [ɑ] | + back + high | '_C(V[+back]) | carro | ['kɑR] | car |
| Stressed front central | Stressed central close-mid | /ɛ/ → [œ] | + back + high | '_C(V[+back]) | cedo | ['sœt] | soon |
| Stressed front close-mid | Stressed central close-mid | /e/ → [œ] | + back | '_(Gp)C (V[+back]) | perto dinheiro | ['pœɾt] [di'ɲœjɾ] | close money |
| Stressed back1 central | Stressed back2 close-mid | /ɔ/ → [o] | + back + high | '_C(V[-open]) | voto | ['vot] | vote |
| Stressed front close | Stressed central close | /i/ → [i] | + back | '_C(V[+back]) | isto | ['iʃt] | this |
| Stressed front close | Stressed back2 close | /i/ → [u] | + + back | '_C(V[+back]) | bicho | ['buʃ] | animal |
As I will mention in more detail in the following section, the final unstressed [u] is deleted in daily spoken Portuguese in Graciosa. This aspect naturally has its consequences for the Dillon prediction that the metaphony in Romance languages is a morpho-phonological phenomenon of double morphemic exponence. The final [u], morpheme of masculine gender, disappears in GP and it is expressed only by the stressed stem vowel. In the terms of Generative Phonology henceforth only the ATR/RTR feature of the stressed vowel is distinctive (compared to the feminine form). The double morphemic exponence no longer exists. This however does not prove that metaphony is or is not morphologically driven, it is only proof of the application of the economy principle do only when necessary. In this paper I will leave open the question whether metaphony is morphologically or phonologically driven. Further research is needed in order to prove if phonology can provide us with a purely formal system of rules and constraints able to generate the segments collected in Graciosa.
6. Diphthongization of stressed vowels in GP
Another phonetic phenomenon affecting the stressed vowels in GP exists in the development of semivowels either [j] or [w] ahead of the stressed vowel leading to the creation of raising diphthongs. This happens when the stressed vowel is preceded by an unstressed vowel with the ATR/RTR feature corresponding to the ATR/RTR feature of the raising semivowel (it is therefore a kind of progressive assimilation). The front semivowel [j] rises thus if it is preceded by an unstressed front vowel ([i, ĩ]) or front semivowel ([j]) and the back semivowel [w] if the pre-stressed vowel belongs to back vowels ([u, ũ, o, õ,]) or semivowel ([w]). The pre-stressed vowel and the stressed vowel do not need to belong to the same word as shown in Table 4. Sample acoustic measurements have shown that the timbre of the stressed vowel is not influenced by the raised semivowel element in the diphthong. The phenomena of diphthongization and metaphony may thus be independent. To be more explicit: they do not correlate but can co-exist in one word. That is why the description of the diphthongization of stressed vowels will not be developed more in this paper.
Table 4 – Exemplification of the phenomenon diphthongization of stressed vowel
| Pre-stressed vowel | Stressed vowel | Example | Example pronunciation | Gloss |
| /õ/ | /i/ | escondida | [ɨʃkõdw'iðɐ?] | hidden (f.) |
| /õ/ | /i/ | escondido | [ɨʃkõdw'it] | hidden (m.) |
| /w/ | /œ/ | não vejo | [n?ɐ̃wvw'œjʒ] | I can not see |
| /u/ | /a/ | lugar | [luɣw'aɾ] | place |
| /u/ | /ɑ/ | no barco | [nuβw'ɑɾk] | by ship |
| /i/ | /a/ | mijar | [miʒj'a] | to urinate |
| /j/ | /a/ | Em casa | [ɨ̃jkj'azɐ?] | at home |
| /ĩ / | /e/ | tender | [tĩdj'e] | to tend |
7. Phonetic realization of alternating stressed vowels in GP
The measured and analyzed acoustic properties of the stressed GP vowels will be described in more detail in this section. It is convenient to introduce first the variation across the data set which relates to the fact that our speech material consists of two corpora: the recorded stress vowel utterances are divided according to the informant who pronounced them (Gr1 or Gr2). At the same time we will compare the results of measurements made in two programs (Praat and SpeechStation2) and two different modes (single and spectrum) as explained in Section 3.
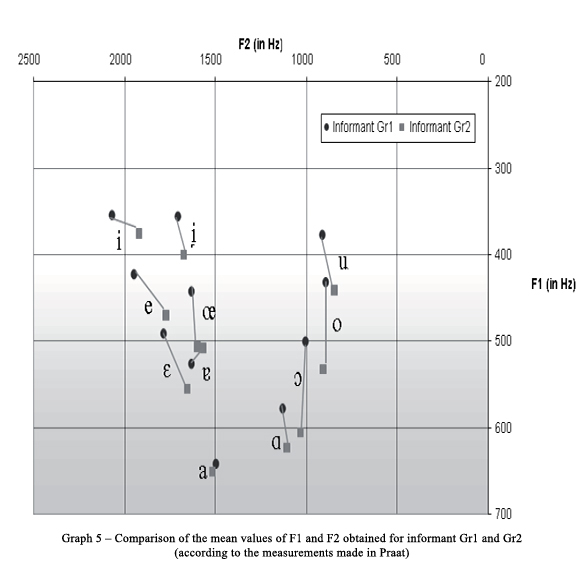
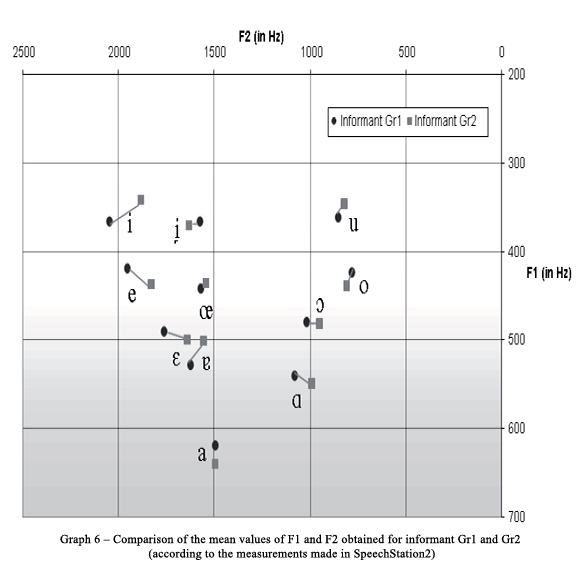
Let us begin with the measurements made by using Praat. If we compare the mean values of F1 and F2 counted for each of the informants separately (see Graph 5), we encounter discrepancies in the way how the stressed vowels are pronounced: the mean value of F1 for all vowels, except for [a, ?], is higher in the case of the informant Gr1 which means that these vowels are pronounced as more closed by him. Another contrast has been noted in the case of front vowels [i, e, ɛ] which are pronounced as more posterior by Gr2 (the mean value of F2 is lower in the case of Gr2).
We may be surprised by the fact that the results of measurements made in SpeechStation2 represent formant mean values which are less sensitive to individual variation. It means that mean values of all utterances of single phonemes pronounced by Gr1 do not differ greatly from the values which constitute a typical pronunciation of the same phonemes by Gr2. That is probably because the measurements in SpeechStation2 were made in a different mode than in Praat: by counting the average frequency for each vowel token registered between the beginning and the end of the measured signal (the mode of average spectrum). The contrast between the data represented by Graphs 5 and 6 have the following interpretation: the program SpeechStation2 and/or the average spectrum mode offer more coherent data in relation to individual variation and might be therefore more convenient for the analysis of inter-phonemic relations and for the phonemic variation in general (the vowel-related variance).
The following part of this section will be dedicated to the surface phonetic realizations of each phoneme which serves as input for the process of metaphony in GP. The regular shifts of the stressed vowels which are not caused by the metaphonic process will also be mentioned.
7.1 /a/ → [ɑ]/[ɔ]
The stressed central open vowel /a/ occurs after the metaphonic shift as back open-mid [ɑ] but the results often achieve the timbre of [ɔ] as it has been said in the previous section. The difference between the utterances of both allophones consists in a more ([ɔ]) or less ([ɑ]) closed pronunciation which is reflected in the value of F1 but partially also in more ([ɔ]) or less ([ɑ]) retracted tongue during the vowel articulation impacting the value of F2. The acoustic contrast between [ɑ] and [ɔ] is however very small.
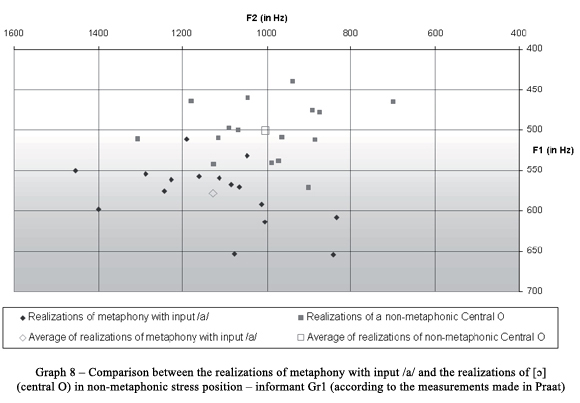
Graph 7 exemplifies the situation by comparing realizations of metaphony with input /a/ to the pronunciation of the vowel [ɔ] in stressed position not impacted by metaphony, all belonging to one informant - Gr2. One big part of the realizations of metaphony with input /a/ has the acoustic parameters of [ɔ]: the group of utterances with lowest values of F1 and F2 at the same time. It is problematic to quantify them; they represent approximately one half of all registered realizations of metaphony with input /a/. The way in which /a/, after metaphonic shift, is pronounced compared to the occurrence of stressed [ɔ] where metaphony is not involved, might be rather individual in GP. This hypothesis is based on the contrast between the data displayed in Graphs 7 and 8 which represent the individual pronunciation of [ɑ] and [ɔ] by Gr2 and Gr1, respectively. The distribution of single utterances across the F1-F2 vowel plot in the case of informant Gr1 (Graph 8) indicates that the mixed vowel [ɑ] as metaphonic output could be acoustically sufficiently distinct from [ɔ]. The formant mean values of both categories situated further from each other logically validate this statement. The input /a/ rarely surfaces as [ɔ] in the metaphony in the case of Gr1.
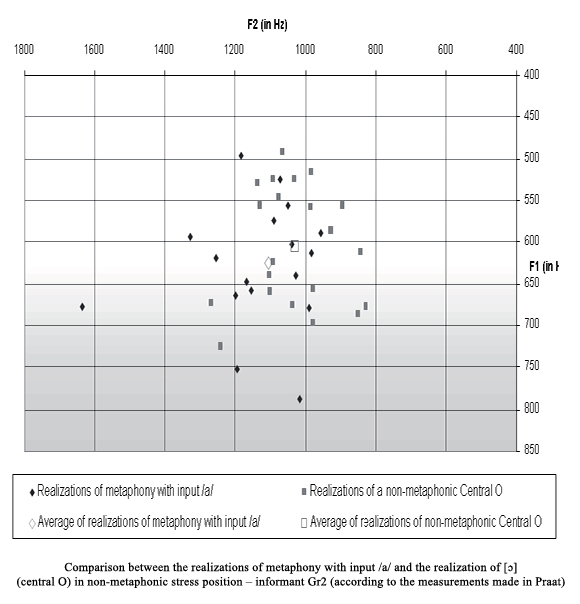
The spectra of the words containing [ɑ] or [ɔ] as outputs of metaphony confirmed that the deletion of unstressed back vowel [u] in final position, which caused the shift of the stressed vowel, is standard. The final vowel is deleted in all 28 cases of tokens in the singular (in the phonemic context C_#) and in four cases of a total of five tokens in the plural (in the context C_C#). The only case of the observed conservation of the post-tonic unstressed back vowel is the word carros cars. The reason for this was more likely an emphasized pronunciation (the duration of the stressed vowel was 0,158 s and the F2 indicating backness of the pronunciation was rather low compared to all collected tokens: 1027 Hz in Praat).
7.2 /i/ → [i]/[i]/[u]
This change occurs as a result of two different phonological processes affecting the phoneme /i/: regressive assimilation with the back vowel /u/ (metaphony) and as a timbre change in the vowel before a pause - that is to say, in the absolute final position of the word.
In the first case the unstressed back vowel in final position is deleted on a regular basis (in 39 cases out of a total of 43 tokens in the singular and in all four cases in the plural in the context C_C#) and the tongue root of the stressed vowel is more retracted under its influence. We encountered a large spectrum of the utterances of the stressed vowel which we divided into three groups corresponding to three allophones according to their F2 measured in Praat: standard[26] realization of [i] with F2 above 2000 Hz for Gr1 and above 1850 Hz for Gr2 (in 5 cases out of a total of 50 tokens, which is 10% of tokens), standard realization of [u] with F2 below 1200 Hz (in four cases out of a total of 50 tokens, which is 8% of all tokens) and as mixed vowel [i] with F2 spread between the two limits (in 41 cases out of a total of 50 tokens, which is 82% of all tokens). Only these 41 utterances will be taken into account for calculation of the mean frequency values for [i4]. In fact the acoustic properties of the mixed vowel [i]are very heterogeneous and the single utterances vary significantly along the horizontal (F2) as well as along the vertical axis (F1). The F2 values of the realizations we observed are spread between 1352,20 Hz and 1965,99 Hz in the case of Gr1 and between 1399,50 Hz and 1829,39 Hz in regard to Gr2. The values of F1 indicating vowel openness vary from 312,93 Hz to 411,25 Hz in the case of Gr1 and from 334,36 Hz up to 521,34 Hz by Gr2. These large intervals and the approximate evenness of allocation of all utterances in the space delimited by the above mentioned limits, as shown in Graph 9, leads us to the conclusion that the allophone [i] has no standardized pronunciation so far. Its single outcomes seem to freely combine the articulatory properties of two extremes: [i] and [u], concerning the position of the tongue root as well as the roundness. The more rounded the timbre, the higher the value of F1 and the lower the value of F2. The phonetic context of the observed vowel has apparently no direct impact on its timbre: as expected, one informant pronounced the same word in free speech in many ways.
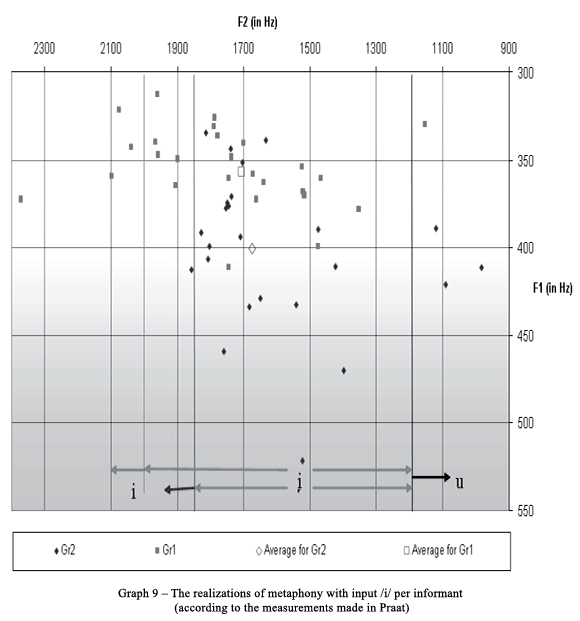
The regressive assimilation of the stressed /i/ with the final unstressed back vowel /u/ is regularly followed by deletion of the final vowel. I observed it in 43 out of 47 collected tokens (including four times in plural where the fricative [ʃ] follows the stressed vowel).
The timbre change in the vowel /i/ before a pause is characteristic of the stressed vowel /i/ and does not exist in the case of the remaining vowels which change their timbre in metaphony (/a, ɛ, e, ɔ/). This may be because the vowel /i/ carries stress in the final position of the word unlike the remaining Metaphony Sensitive Phonemes. Lowered /i/ was registered in words like aqui here, ali there or in forms of the first person singular of the indicative past simple (conheci I knew, perdi I lost, vi I saw). On the other hand, we did not encounter vowel shift when the stressed vowel is followed by phonemes, neither with consonants: /l/ (barril barrel, abril April), /r/ (infinitives dormir to sleep, ir, to go), /s/ (in verb forms quis I wanted, diz he says) nor vowels: /a/ (dia day, also in forms of the first and third person singular of the indicative imperfect tense queria I wanted, conhecia I knew, aparecia I appeared) where the vowel /i/ also carries stress. It means that the absolute final position creates the necessary condition for this alternation.
i → ị / _#
In situations other than the absolute final position, the vowel/i/ alternates with /ị/provided that it is followed by the unstressed back vowel /u/: viu he saw, which creates a context not significantly different from the context of metaphony as it is also a case of regressive assimilation. In contrast to metaphony the unstressed final vowel, which triggers the shift of the stressed vowel, remains pronounced. It is not cancelled.
i → ị / _(C)V[+back]
When we collect all single realizations of /i/ in the absolute final position (they are five in total) we see that they constitute a heterogeneous group of phones from the acoustic point of view. According to the criteria established for [ị] only three vowel tokens could be classified as a typical case of [ị]. The remaining two tokens, both pronounced by Gr2, are lying in the F1-F2 vowel plot close to the artificial border 1850 Hz for Gr2. If we compare these realizations to the standard [i] pronounced by the same informant we see that their F1 is rather higher and F2 is rather lower than the average [i] which means that these vowels are pronounced slightly more rounded than it is usual for [i].
7.3 /e///ɛ/ → [œ]
The realization [œ] as an output of metaphony, neutralizesthe contrast between the inputs /e/ and /ɛ/ in the stressed word position. It occurs in cedo early(where in SEP it appears as [e]) as well as in perto near (where in SEP it surfaces as [ɛ]). The occurrences of the mixed vowel [œ] constitute again a very heterogeneous group. The level of their openness rises from values close to the average obtained for [ị (F1= 356,77 Hz for Gr1 and F1= 400,21Hz for Gr2) up to the mean value of [ɛ] in GP (F1= 491,54 Hz for Gr1 and F1= 555,89 Hz for Gr2).
F2, providing information about the ATR/RTR feature of the realizations measured, scales down from 1829,57 Hz (close to the mean F2 of [e] in GP) to 1345,09 Hz[27]. The collected data set proved that there is no direct relation[28] between the acoustic properties of the single realizations of [œ] and the pertinence of the stressed vowel either to the phonemes /e/ or /ɛ/ in the deep structure. That is why there is no reason to distinguish between two mixed vowels according to the input (/e/ and /ɛ/). In addition the right assessment of the metaphonic input is insecure because there is no way to find out the right phoneme which is surfaced by [œ]. Thus a simplification has to be admitted by assuming that the input corresponds to the vowel which occurs in the stressed position of the particular word in SEP, for example /ɛ/ in tecto ceiling, velho old or amarelo yellowand /e/ in mesmo same, negro black or bezerrocow.
The deletion of the unstressed back vowel [u] in final position is also normal for the metaphony with [œ] as output: its conservation was recorded only in three cases out of 35 tokens (and never in plural before the fricative [ʃ]).
The stressed /e/ alternates with [œ] when it is followed by the semivowel [w] in the verb morpheme of third person singular of the indicative past simple eu (adoeceu he became ill, nasceu he was born). /ɛ/ alternates with [œ] in the word ilhéu small island. It is in analogy with the regressive assimilation of /i/ in viu.
7.4 /ɔ/ → [o]
The metaphonic alternation of the vowels /o/ and /ɔ/ can be seen as problematic because the surface utterance is not a mixed vowel and the input is not certain in all cases. The alternation only takes place when the input is /ɔ/ but similar to the shift /e///ɛ/ → [œ] there are no means to assure correct assessment of the metaphonic input. In words like maragoto[29]wrasseand porcos pigs it is probably due to the process of metaphony that the stressed vowel is close-mid ([o]) instead of central ([ɔ]) which occupies stress position in these words in SEP. However there might be some cases where the final unstressed vowel is neither back nor high (it means there is no metaphony in place) and where in GP we hear [o] instead of [ɔ], as it is usual in SEP. This case was not encountered in the presented speech data of GP but such cases were collected in other islands of the archipelago[30], thus the local standard way of pronunciation of stressed /o/ might be different from the one of SEP in some cases. It means that we have to be careful in the generalization that attributes all utterances of [o] in GP in the context of back final unstressed vowel to metaphony even if the standard pronunciation in SEP is [ɔ]. In addition, it was not always the expected pronunciation which was recorded: logo ['lɔk] soon and tocos ['tɔkʃ] hits (both pronounced by Gr2).
8. Acoustic properties of stressed vowels in Graciosa Portuguese
Table 5 reports the mean values of F1, F2 and F3 for all stressed oral vowels of GP obtained from 429 utterances analyzed in the speech of both informants. I have placed them in relation to the data of SEP published by Delgado-Martins (1988) in order to confront mean values of the first three formants for both variants of Portuguese. As it has been said before, this comparison is not methodologically correct (different data collection methods) , the values for SEP have been mentioned for a reference only. Mixed vowels (in gray cells) which do not have their equivalents in SEP are compared to their counterparts in the sub-inventory Stressed vowels before the metaphonic shift ([œ] with [e] on this occasion). The values marked in bold in Table 5 may represent certain standard pronunciation of the stressed vowels in the male population in GP and they serve as source data for Graph 2.
Table 5 – Mean values for F1, F2 and F3 of stressed vowels in GP in Hz (according to the measurements made in Praat) compared to SEP (according to Delgado-Martins 1988)
| F1 | F2 | F3 | Vowel tokens | |||||||
| GP | SEP | dif. | GP | SEP | dif. | GP | SEP | dif. | ||
| /i/ | 365,94 | 293,58 | 72,36 | 1995,19 | 2343,36 | -348,17 | 2690,31 | 2984,72 | -294,42 | 60 |
| /i4/ | 378,49 | - | 84,91 | 1689,67 | - | -653,69 | 2415,28 | - | -569,44 | 41 |
| /e/ | 447,06 | 403,19 | 43,87 | 1858,14 | 2083,94 | -225,80 | 2573,79 | 2588,83 | -15,04 | 47 |
| /¿/ | 474,80 | - | 71,61 | 1615,02 | - | -468,93 | 2531,42 | - | -57,41 | 47 |
| /E/ | 523,72 | 501,10 | 22,62 | 1720,31 | 1893,21 | -172,90 | 2594,82 | 2565,08 | 29,74 | 36 |
| /?/ | 517,22 | 511,13 | 6,09 | 1598,38 | 1602,07 | -3,69 | 2676,50 | 2558,80 | 117,70 | 9 |
| /a/ | 646,75 | 626,04 | 20,71 | 1506,73 | 1325,77 | 180,96 | 2538,54 | 2439,89 | 98,65 | 60 |
| /A/ | 601,67 | - | -24,37 | 1116,95 | - | -208,83 | 2680,65 | - | 240,76 | 32 |
| // | 553,14 | 530,70 | 22,43 | 1016,40 | 993,91 | 22,49 | 2654,19 | 2407,03 | 247,155 | 37 |
| /o/ | 482,62 | 425,53 | 57,09 | 898,29 | 863,59 | 34,70 | 2681,66 | 2414,06 | 267,60 | 27 |
| /u/ | 409,58 | 315,00 | 94,58 | 877,91 | 677,80 | 200,11 | 2464,04 | 1662,29 | 801,75 | 24 |
The differences between the final mean values of each formant in GP and SEP reflect all 420 single vowel tokens taken into account in the calculation of any of the eleven phonemes/allophones in GP. Similarly to the paper of Delgado Martins (2002)[31] I established a relationship between F1 and F2 of each vowel token analyzed and the formant mean values in calculating the single absolute deviation. The average of all collected absolute deviations per phoneme/allophone was calculated according to the following formula.
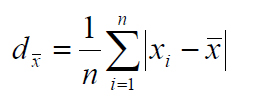
Where dx? is average absolute deviation, n is the number of tokens included in the formula, xi is the single utterance and x? is the formant mean value. In order to make the average absolute deviations per phoneme/allophone comparable with each other it is necessary to relate them to the formant mean values. The result is an absolute unit, expressed as a percentage, called coefficient of variation (cv) defined as the ratio of the average absolute deviation to the mean.
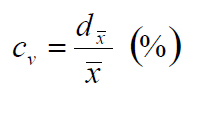
The coefficient of variation gives us an idea of how each phoneme/allophone is stable in the speech material observed. The higher the percentage, the more variable are the single utterances of the stressed vowel in question. First I calculated the coefficient of variation of each phoneme/allophone per informant by using the formant mean value belonging to the respective informant (see Table 6). Later I combined all absolute deviations belonging to the same phoneme and related them to the final phonemic mean value (calculated as average of the phonemic mean values per informant). For this general overview please refer to Table 7.
Table 6 – Average absolute deviation and the coefficient of variation of F1 and F2 in the corpus of Gr1 and Gr2 (according to the measurements made in Praat)
| F1 | F2 | |||||||
| informant Gr1 | informant Gr2 | informant Gr1 | informant Gr2 | |||||
| dx? (Hz) | cv (%) | dx? (Hz) | cv (%) | dx? (Hz) | cv (%) | dx? (Hz) | cv (%) | |
| /i/ | 22,47 | 6,32 | 27,19 | 7,23 | 104,22 | 5,04 | 50,09 | 2,61 |
| /ị/ | 17,34 | 4,86 | 35,34 | 8,83 | 144,43 | 8,47 | 113,40 | 6,77 |
| /e/ | 18,51 | 4,37 | 27,35 | 5,82 | 103,88 | 5,33 | 121,47 | 6,87 |
| /œ/ | 27,35 | 6,18 | 75,70 | 14,93 | 85,71 | 5,26 | 223,46 | 13,97 |
| /ɛ/ | 18,87 | 3,84 | 23,94 | 4,31 | 95,52 | 5,35 | 95,30 | 5,76 |
| /ɐ?/ | 24,88 | 4,73 | 11,14 | 2,19 | 85,36 | 5,23 | 59,00 | 3,77 |
| /a/ | 33,86 | 5,28 | 43,20 | 6,63 | 61,20 | 4,09 | 92,28 | 6,08 |
| /ɑ/ | 30,96 | 5,35 | 56,77 | 9,09 | 133,74 | 11,86 | 117,14 | 4,20 |
| /ɔ/ | 28,45 | 5,68 | 63,63 | 10,51 | 113,82 | 11,36 | 95,61 | 9,28 |
| /o/ | 21,54 | 4,98 | 49,22 | 9,24 | 126,91 | 14,23 | 62,58 | 6,92 |
| /u/ | 22,88 | 6,06 | 57,14 | 12,95 | 103,53 | 11,38 | 111,45 | 13,17 |
Table 7 – Average absolute deviation and the coefficient of variation of F1 and F2 in GP (according to the measurements made in Praat)
| F1 | F2 | |||
| dx? (Hz) | cv (%) | dx? (Hz) | cv (%) | |
| /i/ | 24,83 | 6,78 | 77,16 | 3,87 |
| /ị/ | 26,75 | 7,07 | 128,21 | 7,59 |
| /e/ | 21,90 | 4,90 | 110,62 | 5,95 |
| /œ/ | 45,48 | 9,58 | 137,37 | 8,51 |
| /ɛ/ | 22,42 | 4,28 | 95,40 | 5,55 |
| /ɐ?/ | 20,30 | 3,92 | 76,57 | 4,79 |
| /a/ | 38,53 | 5,96 | 76,74 | 5,09 |
| /ɑ/ | 44,26 | 7,36 | 125,19 | 11,21 |
| /ɔ/ | 48,42 | 8,75 | 103,49 | 10,18 |
| /o/ | 39,99 | 8,29 | 84,03 | 9,35 |
| /u/ | 38,58 | 9,42 | 107,16 | 12,21 |
The data presented in Table 7 reveal clearly two general trends of variation for both variables: openness (F1) and place of articulation (F2). The coefficient of variation is higher for
- the back phonemes /ɔ/, /o/ and /u/, in analogy with the results of Delgado Martins (2002)
- the mixed vowels [ị], [œ] and [ɑ].
On the other hand there are vowels which should be considered as stable:
· /e/, /ɛ/ and [ɐ?][32] in the way how open or closed they are
· /i/, /ɛ/, /a/ and /?ɐ/ in the horizontal position of the tongue during their articulation
The results confirm, in my view, the hypothesis that the allophones of mixed vowels in GP have no standard way of articulation and in a certain way freely combine the articulatory properties of two phonemes between which they are located in the F1-F2 diagram.
Table 6 however suggests that phonetic variation of single utterances across the data is strongly dependent on individual articulatory behavior of each informant. The coefficients of variation per formant and phoneme/allophone are in general slightly higher in the corpus of Gr2 which means Gr2 more likely pays less attention to his vowel articulation. For the mixed vowels this generalization does not count. The phoneme [œ] shows extremely high values for Gr2 in both F1 and F2, in contrast with Gr1. Such a high discrepancy could, in my view, be explained only by the existence of two or more individual allophones of [œ] in the speech of Gr2. The results obtained for the allophone [ɑ] are different: the coefficient of variation is much higher in the case of F2 by Gr1, compared to Gr2 and in the case of F1 by Gr2 compared to Gr1. It is in analogy with the back vowels (except from /u/ what F2 concerns). This means that the vowel tokens pronounced by the informant Gr1 have a stable level of openness but vary in the position of articulation in the frame of single phonemes.
9. Conclusion
The acoustic analysis presented in this paper made possible a modulation of the system of oral stressed vowels in Graciosa Portuguese (GP). This Insular dialect is supposed to be a model example of the Insular Portuguese metaphony. The main characteristics of this sort of metaphony are: the tongue retraction during the pronunciation of all categories of stressed vowels (front, central and back) and partially also the closing (the affected vowels become higher) under the influence of the unstressed final high back vowel /u/ which is deleted in speech. The stressed vowels representing output of metaphony are mostly mixed and constitute a specific sub-inventory of the stressed vowels in GP. Their single phonetic realizations exhibit a great coefficient of variation in the values of the first two formants (representing the level of openness and the ATR/RTR feature). No relationship was found between the timbre of the metaphony output vowels and the presence of the semivowel element appearing to the right of it in a word or raising to the left of it under the condition it is preceded by an unstressed vowel or semivowel carrying the same ATR/RTR feature. The results presented in the paper should be supported by analyzing of speech data obtained from more informants, especially what the phonetic realization of alternating stressed vowels concerns.
Apart from metaphony, the mixed vowel [ị] appears regularly in the final stressed position, immediately before a pause. This is a very interesting phenomenon which could prove that metaphony is phonologically driven in GP (shift of the stressed vowel to a more retracted vowel category under certain circumstances, i.e. if not followed by an unstressed vowel). It remains however to be defined with more precision and proved formally, probably in the framework of the Auto-segment theory which admits that certain segments influence other segments even if they are phonetically deleted. It is thus a challenge for future studies in this area.
This paper has not only the acoustic and systematic study of the oral stressed vowels in Graciosa Portuguese (GP) as its objective, but it is also attempting to find the most appropriate methodology and instruments for the study of particular dialects based on acoustic data. The measurements were made in two different PC programs developed for the purpose of speech analysis (Praat and SpeechStation2) by using different modes for the calculation of formants values (single and average spectrum mode, respectively). The comparison of the results obtained in these two programs has brought us to the following conclusion. The average mode, where the researched value is calculated as the mean frequency of each formant within the selected interval of the signal, might be more appropriate for studying the relationship between phonemes in a particular dialect and of the regional variation in pronunciation of the stressed vowel. That is because this mode provides values less sensitive to individual phonetic variation. The more widely used single spectrum mode, which measures formant frequencies right in the temporal midpoint of the signal, is indispensable for the assessment of obtained mean values of each phoneme in the particular dialect in relation to the referential pronunciations of the language in question.
References
Adank, Patti (2003), Vowel Normalization: a perceptual-acoustic study of Dutch vowels,Wageningen, Ponsen & Looijen. [ Links ]
Asher, R. E. (ed.) (1994), The Encyclopedia of Language and Linguistics, Oxford, Pergamon Press. [ Links ]
Bernardo, Maria Clara Rolão & Montenegro, Helena Mateus (2003), O Falar Micaelense, Viseu, João Azevedo Editor. [ Links ]
Carvalho, J. Herculano de (1958), Sincronia e diacronia no sistemas vocálicos do crioulo caboverdiano in (1962), Miscelánea-Homenaje a André Martinet. Estricturalismo e História, vol. 3, La Laguna, pp. 43-67. [ Links ]
Delgado-Martins, Maria Raquel (2002), A Fonética do Português, Trinta anos de investigação,Lisboa, Caminho. [ Links ]
Delgado-Martins, Maria Raquel (1988), Ouvir falar. Introdução à Fonética do Português, Lisboa, Caminho. [ Links ]
Delattre, Pierre (1951), The Physiological Interpretation of Sound Spectrograms in Publications of the Modern Languages Association, vol. 66, pp. 864-875, in Delattre, Pierre (1966), Studies in French and Comparative Phonetics, The Hague, Mouton, pp 225-235. [ Links ]
Dillon, Caitlin M. (2003), Metaphony as Morpheme Realization, Not Vowel Harmony, Indiana University, disponível em https://www.indiana.edu/~iulcwp/pdfs/04-dillon.pdf/, consultado em 10/02/2011. [ Links ]
Escudero, Paola & Boersma, Paul & Rauber, Andréia Schurt & Bion, Ricardo A. H. (2009), A cross-dialect acoustic description of vowels: Brazilian and European Portuguese,Acoustical Society of America, disponível em http://www.fon.hum.uva.nl/paul/papers/Portuguese2009.pdf, consultado em 01/08/2012. [ Links ]
Fikkert, Paula (2005), From phonetic categories to phonological features specification: Acquiring the European Portuguese vowel system, Lingue e Linguaggio, vol. 4(2), pp 263-280. [ Links ]
Harrington, Jonathan (2010), Acoustic Phonetics, in Harcastle, William J. & Laver, John & Gibbon Fiona E. (ed.) (2000), The Handbook of Phonetic Sciences,Chichester, Blackwell Publishers Ltd., pp. 81-129. [ Links ]
Jakobson, Roman & Fant, C.Gunnar M. & Halle, Morris (1952), Preliminaries to Speech Analysis. The Distinctive Features and Their Correlates, Massachusetts, Institute of Technology. [ Links ]
Kager, Rene (1999), Optimality theory, Cambridge, Cambridge University Press. [ Links ]
Kurisu, Kazutaka (2001), The phonology of morpheme realization, Santa Cruz, University of
California, dissertation, disponível em http://roa.rutgers.edu/files/490-0102/490-0102-KURISU-0-0.PDF, consultado em 16/05/2012.
Ladefoged, Peter (1988), The many interfaces between phonetics and phonology in Phonologica, in Dressler, Wolfgang U. (ed.) (1992), Proceedings of the 6th International Phonology meeting,Cambridge, Cambridge University Press, pp. 165-179. [ Links ]
Ladefoged, Peter & Broadbent, Donald E. (1957), Information conveyed by vowels in Journal of the Acoustical Society of America 29, pp. 98-104. [ Links ]
Mateus, Maria Helena & Andrade, Amália & Viana, Maria do Céu & Villalva, Alina (1990), Fonética, fonologia e morgologia do português, Lisboa, Universidade Aberta. [ Links ]
Mateus, Maria Helena & d´Andrade, Ernesto (2000), The phonology of Portuguese, Oxford, Oxford University Press. [ Links ]
Prince, Alan & Smolensky, Paul (1993/2002), Optimality theory: constraint interaction in generative grammar,Rutgers Optimality Archive, disponível em http://roa.rutgers.edu, consultado em 01/08/2012. [ Links ]
Santos, Isabel Almeida (2003), Variação Linguística em Espaço Rural. A vogal [ü] numa comunidade do Baixo Mondego,Lisboa, Imprensa Nacional-Casa da Moeda. [ Links ]
Segura da Cruz, Maria Luisa & Saramago, João (1999), Açores e Madeira: autonomia e coesão dialectais, in Faria, Isabel H. (ed.) (1999), Lidley Cintra - Homenagem ao homem, ao Mestre e ao cidadão,Lisboa, Edições Cosmos e Faculdade de Letras da Universidade de Liboa, pp. 707-738. [ Links ]
Teixeira, António & Moutinho, Lurdes Castro & Coimbra, Rosa Lídia (2003), Production, Acoustic and Perceptual Studies on European Portuguese Nasal Vowel Height, in International Congress Phonetic Sciences, pp 3033-3036. [ Links ]
Tláskal, Jaromír (2006), Fonetika a fonologie soucasné evropské portugaltiny,Praha, Karolinum press. [ Links ]
Walker, Rachel (2006), Vowel Harmony and Licensing: Stress Sensitivity in Metaphony,Indiana University, disponível em https://www.indiana.edu/~lingdept/pdfs/Walker Veneto6-21.pdf/, consultado em 10/02/2011. [ Links ]
Notes
[1] Teixeira, Moutinho, Coimbra (2003, p. 4).
[2] Escudero, Boersma, Rauber, Bion (2009), Delgado Martins (1988).
[3] They follow the methods introduced by Adank (2003).
[4] Their informants were producing the vowels by reading of carrier sentences especially designed for this purpose by the researcher.
[5] The segmentation into small files is not necessary for formant measurements in Praat since this software has the TextGrid option which allows much easier and more reliable data segmentation and labeling. The manipulation with long recordings in SpeechStation2 is very problematic. The creating of small files makes the researchers life easier.
[6] This procedure has been adopted from Adank (2003).
[7] This is done if the researcher measures vowel formants manually. If scripts are used the researcher can predefine the number of decimals.
[8] For more information about her research see Delgado-Martins (2002; 41-52)
[9] Escudero, Boersma, Rauber, Bion (2009)
[10] SEP contains in fact nine vowels. One of them, [ö], never occurs in stressed position.
[11] Advanced Tongue Root/Retracted Tongue Root
[12] Escudero, Boersma, Rauber, Bion (2009) omits [ɐ?] in contrast to Delgado-Martins (2002).
[13] According to The Encyclopedia of Language and Linguistics (1994).
[14] [?ɐ] is not counted as no methaphy impacting [ɐ?] has been registered.
[15] The Encyclopedia of Language and Linguistics (1994: volume 5, p. 2610).
[16] Walker (2006, p. 4).
[17] Dillon (2003, p. 5).
[18] The Lena dialect of Spanish and the Treia dialect of Italian.
[19] Dillon (2003, p. 8).
[20] Dillon (2003) and Walker (2006).
[21] Segura da Cruz, Saramago (1999) referring to Carvalho (1958).
[22] Segura da Cruz, Saramago (1999, p. 723).
[23] In the Spanish dialect Lena, spoken in Asturias, the stressed input mid vowels (/e, o/) surface as high ([i, u], respectively), and stressed input low vowels (/a/) surface as mid ([e]) in the context of a suffix high vowel. The metaphonic alternations in Treia, the Italian dialect spoken in Marche, differ from Lena in the stressed low vowels which do not undergo metaphony (Dillon 2003).
[24] The input /a/ surfaces as [ɐ], eventually also as [ɔ] in the Portuguese Creole of Cabo Verde.
[25] The clear pronunciation of [u] as output of metaphony was registered five times: once pronounced by the informant Gr1 and four times by Gr2.
[26] The term standard used in this paragraph applies to the Graciosa reality and has nothing to do with the standards of European Portuguese defined by Delgado-Martins (2002).
[27] Both extremes were obtained from informant Gr2 who has a very divergent set of tokens.
[28] However the input /e/ tends to surface as slightly more advanced [œ] compared to the input /ɛ/.
[29] Local expression for maragota.
[30] Bernardo, Montenegro (2003, p. 46).
[31] The author followed the principles formulated by Delattre (1951) and by Jacobson, Fant, Halle (1952).
[32] In this case we registered only few realizations of [ɐ?] in the stressed position, the fact which could have influenced its low average absolute deviation.
