











 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introdução
As atividades de perfuração na indústria de petróleo e gás são uma preocupação partilhada entre as Joint Ventures, agências governamentais e o público em geral (Silva, Costa, & Barreiros, 2006). Estas podem afetar a rentabilidade das empresas e o seu meio ambiente (Hoffimann, Mao, Wesley, & Taylor, 2018). As operações de perfuração envolvem um planeamento e execução detalhados para obter uma exploração viável do poço. O planeamento permitirá atingir a eficiência da perfuração, minimizando o custo de tempo improdutivo (NPT - Non-Productive Time).
Os programas de vigilância ativos utilizam grandes volumes de dados gerados em vários estágios do processo de perfuração (Silva, Martins, Doria Neto, Rodrigues, & Da Mata, 2016). Apesar do aumento da confiança nas medições quantitativas em tempo real no local da perfuração, os dados gerados em relatórios diários de perfuração (DDR) e gravações de atividades não têm sido devidamente aproveitados para uma melhoria do processo de perfuração. Estas fontes não são exploradas para monitorização e alerta por ferramentas convencionais. Nesse sentido, através dos dados gerados em DDR, o objetivo deste estudo passa por construir um modelo de Inteligência Artificial (AI) usando Redes Neuronais Artificiais (ANN) para classificar as operações de perfuração de um poço de petróleo.
O desenvolvimento bem-sucedido de novos campos de petróleo e a extensão da vida útil dos campos de produção são o resultado de programas de perfuração eficiente (Sidahmed, Coley, & Shirzadi, 2015). A institucionalização de tais programas diminui a estrutura de custos substancialmente através do processo sistemático e advento de novas tecnologias. Ao longo da última década, o setor reconheceu o valor de automatizar partes significativas das tarefas de perfuração para manter eficiência, reduzir a sobrecarga e superar o erro humano (Iversen, Gressgård, Thorogood, Balov, & Hepsø, 2013).
O objetivo deste estudo é desenvolver um classificador através de aprendizagem automática que permita classificar se um poço em prospeção tem ou não petróleo. Para atingir o objetivo definido, foram conduzidas duas análises de classificação de operações para identificar as atividades de NPT e tempo produtivo (PT - Productive Time). A primeira, usando as redes Multi-Layer Perceptron (MLP). A segunda, usando as redes Long Short-term Memory (LSTM). Posteriormente, os dois modelos foram comparados com o objetivo de identificar o modelo com melhores resultados.
O sistema de classificação pode ser utilizado para produzir um relatório preciso e detalhado sobre as atividades realizadas durante a perfuração de um poço. Através deste, será possível identificar as atividades que gastam mais tempo na sonda e otimizar os custos em futuros poços.
2.Revisão de literatura
A classificação automática de texto consiste na tarefa de atribuir uma ou mais categorias a um documento ou a um conjunto de dados eletrónicos com base no seu conteúdo. Atualmente, a classificação é amplamente utilizada em muitos contextos. As abordagens por padrões de categorização utilizam estatística ou métodos de IA para executar uma tarefa (Sanchez-Pi, Martí, & Garcia, 2014). Os métodos mais usados podem ser ANN, máquinas de Vetores de Suport (SVM), lógica Fuzzy, algoritmos genéticos (GA) e K-Nearest Neighbor (Han, Kamber, & Pei, 2011). Todos estes métodos requerem um conjunto de treino de documentos pré-classificados que são usados para atribuir classificações automaticamente (Sanchez-Pi et al., 2014).
A perfuração de um poço de petróleo é feita a partir da utilização de uma sonda de perfuração que, por definição, consta como um conjunto de sistemas, equipamentos e ferramentas que tem a principal finalidade de perfurar diversas camadas de rochas, até encontrar um reservatório de petróleo (Thomas, 2001). O percurso criado através das camadas geológicas (poço) irá ligar o reservatório à superfície, permitindo assim a correta drenagem dos hidrocarbonetos. Os eventos que podem ocorrer durante a operação de perfuração de um poço de petróleo são a perda de circulação, prisão da coluna de perfuração, desmoronamento do poço, alargamento do poço, influxo de fluidos indesejados (kick), falha no BHA (vibração), entrada de cascalhos nos jatos quando a circulação é interrompida (pack-off), falta de hidratação de argilas (bit-balling) e vazamento no sistema de circulação (washout) (Heriot Watt, 2013).
2.1. Evolução da IA na indústria de Oil&Gas
A IA é uma área de grande interesse e importância para o setor de Oil&Gas. Esta tecnologia tem provocado grandes impactos na indústria e a sua aplicação tem continuado a crescer (Bello, Holzmann, Yaqoob, & Teodoriu, 2015). A aplicação de IA nesta indústria tem mais de 30 anos, sendo voltada para a interpretação de logs de poços, diagnóstico de brocas usando ANN e interfaces inteligentes de simuladores de reservatórios (Bello et al., 2015). Os valores mensuráveis da IA incluem a possibilidade de fazer máquinas resolverem problemas difíceis para entender tendências e fazer previsões de cenários futuros com o menor esforço e desperdício de tempo (Rable, 2017).
2.2. Aplicação da IA na engenharia de perfuração
A classificação de textos através de técnicas de IA criou desafios. Estas técnicas estão concentradas na forma como os relatórios estão escritos. Em muitos casos, não existe um padrão a ser seguido pelas empresas de Joint Venture. De modo a identificar os estudos mais relevantes realizados no âmbito do objeto de estudo, foi aplicada uma query na base de dados Scopus a partir do ano 2000. O resultado devolveu 50 artigos científicos. Através de uma análise cuidada, foram excluídos aqueles que não estavam relacionados com a aplicação de abordagens de dados para o problema específico da perfuração de petróleo, conduzindo a 15 artigos (Tabela 1).
Através desta tabela, podemos verificar que vários autores se concentraram em técnicas de regressão para resolver problemas ou estimar resultados de perfuração. Nenhuma técnica de classificação de operações de perfuração é aplicada.
De acordo com análise da Tabela 1, podemos concluir que cerca de 75% dos estudos estão relacionados com o uso de ANN (50%) e SVM (25%), seguidos da lógica Fuzzy (12%) e GA (13%). Tais resultados justificam a escolha de ANN para treinar o classificador. Adicionalmente, em comparação com técnicas mais tradicionais para classificação como regressão logística e árvores de decisão, as ANN tipicamente obtêm melhores resultados (Moro et al., 2018). No entanto, poucos estudos apresentaram resultados utilizando a ANN com dados extraídos de DDRs.
Para além disto, verificou-se que os estudos apresentados se concentram maioritariamente em estimar a velocidade em operações de perfuração de um poço de petróleo, não observado a classificação automática das operações de perfuração com o objetivo de estimar a duração de perfuração de poços. Nesse sentido, propõe-se um novo estudo com base na topologia de ANN. Das técnicas de IA destacadas, é pertinente questionar se há alguma que possa ser 100% fiável e adequada para o uso em todas as circunstâncias. A Tabela 2 resume os pontos fortes e fracos das técnicas de IA (Agwu, Akpabio, Alabi, & Dosunmu, 2018).
Tabela 1 Técnicas de IA aplicadas na engenharia de perfuração
| Título | Referência | Objetivo | Método | Resultado |
|---|---|---|---|---|
| Determinação da alteração da densidade da lama de perfuração com pressão e temperatura simplificadas e precisas | (Osman & Aggour, 2003) | Fornecer previsões precisas da densidade da lama em função do tipo, pressão e temperatura da lama | ANN | R2 = 0.9998 |
| Abordagem de ANN para estimar propriedades de filtragem de fluidos de perfuração | (Jeirani & Mohebbi, 2006) | Estimar o volume de filtro e a permeabilidade do bolo de filtro usando os dados de filtragem estática. | ANN | R 2 (Volume do filtro) = 0.9815 𝑅 2 (Permeabilidade) = 0.9433 |
| Previsão e Prevenção de Tubos Presos: Uma Abordagem de Rede Neural Convolucional | (Siruvuri, Nagarakanti, & Samuel, 2006) | apresentar uma aplicação de métodos de IA para entender e estimar a ocorrência de tubos diferencialmente presos durante a perfuração. | ANN | 𝑅 2 (Tubos presos) = 0.063 𝑅 2 (Tubos não presos) = 01619 |
| Estimando padrões de fluxo e perdas de pressão por atrito de fluidos bifásicos em poços horizontais usando ANN | (Ozbayoglu & Ozbayoglu, 2009) | Estimar os padrões de fluxo e as perdas por pressão de atrito de fluidos bifásicos que fluem através de geometrias anulares horizontais usando ANN, em vez de usar modelos mecanicistas convencionais. | ANN | MSE=0.006 [FPL with BP] MSE=0.005 [FPL with J/E] MSE=0.005 [FP with BP] MSE=0.005 [FP with J/E] |
| Tomada de decisão para redução do tempo improdutivo por meio de uma previsão integrada de circulação perdida | (Moazzeni, Nabaei, & Jegarluei, 2012) | Prever a gravidade da perda de lama durante a perfuração ao longo de diferentes setores do campo petrolífero. | ANN | 𝑅 2 = 0.82 |
| Pesquisa de colagem de tubos com pré-aquecimento baseada em rede neural | (Zhu, Liu, & Zhang, 2013) | Propor o uso da tecnologia de IA para realizar o pré-aviso de acidente de tubos presos durante a perfuração. | ANN | - |
| Novo método para prever e resolver o problema da perfuração e perda de fluidos usando ANN modular e enxame de partículas algoritmo de otimização | (Toreifi, Rostami, & Manshad, 2014) | Prever a perda de circulação durante a perfuração em qualidade e quantidade. | ANN | 𝑅 2 = 0.94 |
| Previsão em tempo real de parâmetros reológicos do fluido de perfuração à base de água KCl usando ANN | (Elkatatny, 2017) | Usar as frequentes de medições de densidade da lama, viscosidade do funil de Marsh e percentagem sólida para prever as propriedades reológicas desenvolvendo correlações empíricas | ANN | AAPE < 6% 𝑅 2 > 0.90 |
Tabela 2
| Título | Referência | Objetivo | Método | Resultado |
|---|---|---|---|---|
| Previsão em tempo real de parâmetros reológicos do fluido de perfuração à base de água KCl usando redes neuronais artificiais | (Elkatatny, 2017) | Usar as frequentes de medições de densidade da lama, viscosidade do funil de Marsh e percentagem sólida para prever as propriedades reológicas desenvolvendo correlações empíricas | ANN | AAPE < 6% 𝑅 2 > 0.90 |
| Previsão e prevenção de aderência de tubulação usando modelagem lógica difusa adaptativa | (Murillo, Neuman, & Samuel, 2009) | Estimar o risco de ocorrência de tubos presos no procedimento de planeamento de poços e durante a perfuração em tempo real | Lógica Fuzzy | - |
| Um modelo preciso para prever a densidade do fluido de perfuração em condições de poço | (Ahmadi, Shadizadeh, Shah, & Bahadori, 2018) | Sugerir um modelo preditivo rigoroso para estimar a densidade do fluido de perfuração (g / cm3) em condições de poço | Logica Fuzzy | 𝑅 2 = 0.7237 MSE = 69.0907 |
| Uma abordagem de aprendizagem de máquina para a previsão de settling | (Goldstein & Coco, 2014) | Utilizar uma abordagem de aprendizagem de máquina baseada em programação genética para prever a velocidade de assentamento de partículas não coesas. | GA | RMSE = 0.26 𝑅 2 = 0.97 |
| Determinação ideal de parâmetros reológicos para fluidos de perfuração de espigão-sela usando GA | (Rooki et al., 2012) | Determinar comportamento reológico não newtoniano de fluidos de perfuração, a fim de determinar os três parâmetros do modelo de Herschel-Bulkley com mais precisão. | GA | 𝑅 2 = 0.9972 |
| Uma abordagem de SVM para a previsão da densidade do fluido de perfuração em alta temperatura e pressão | (Wang, Pu, & Tao, 2012) | Prever a densidade do fluido de perfuração em alta temperatura e pressão (HTHP). | SVM | MAPE = 0.872 𝑅 2 = 0.9994 |
| Aplicação do algoritmo SVM para o cálculo da perda por pressão por atrito do fluxo trifásico em anéis inclinados | (Shahdi & Arabloo, 2014) | Uso de Lease Square (LS-SVM), para cálculo de perdas por atrito de fluidos de perfuração bifásicos baseados em gás. | SVM | 𝑅 2 = 0.9862 |
| Estimação da densidade do fluido de perfuração na tecnologia de lama: Aplicação em poços de petróleo de alta temperatura e alta pressão | (Kamari, Gharagheizi, Shokrollahi, Arabloo, & Mohammadi, 2017) | Desenvolver um modelo confiável para prever a densidade de quatro fluidos de perfuração, incluindo à base de água, à base de óleo, Coloidal Gás Aphron (CGA) e sintético. | SVM | 𝑅 2 = 0.999 |
3.Metodologia
O estudo é desenvolvido segundo a metodologia Cross-Industry Standard Process of Data Mining (CRISP-DM) (Laureano, Caetano, & Cortez, 2014). A escolha deste modelo deve-se ao facto de ser considerado o padrão de maior aceitação e por ter sido usado para problemas semelhantes. A metodologia CRISP-DM é um modelo que possui processos iterativos, com sequências não mandatárias, possuindo um ciclo de vida, que ocorre nas fases que têm as suas tarefas (Sergio Moro, Laureano, & Cortez, 2011).
Foi utilizado o Spyder 4.0 (do projeto Anaconda) como IDE1 para o desenvolvimento do projeto (Smith, 2020).
Em termos de bibliotecas, foram utilizadas o Keras e o TensorFlow, configurado para uso de GPUs. Adicionalmente, foi adotado o scikit-learn para os algoritmos de Machine Learning (MLP; LSTM) e validação cruzada.
3.1. As operações de perfuração e classificação
Durante a fase de perfuração de um poço de petróleo, compete aos engenheiros de perfuração fazer um relatório diário de operações com o objetivo de controlar o monitorizar o processo de perfuração. Através da inspeção dos relatórios, é possível identificar operações que estão a consumir tempo excessivo de sonda e, a partir dessa observação, adotar medidas que melhorem a operação de perfuração. O sistema de classificação proposto identifica a operação que está a ser executada através da interpretação de dados.
Atualmente, o registo de operações realizadas é feito através do DDR. O DDR é um relatório preenchido diariamente que descreve as operações executadas nas últimas 24 horas. A descrição das operações é feita em linguagem natural e o responsável pelo preenchimento elabora um pequeno texto no qual descreve de forma resumida as atividades executadas. Além da descrição, existe um sistema de codificação que classifica a atividade.
3.2. Construção do dataset
Antes de proceder ao treino do modelo, foi necessário recolher os dados. Esses dados foram extraídos do DDR (Figura 1) através de um script desenvolvido em linguagem VBA no MS excel. Depois da construção do dataset, foram obtidos 20.390 registos de entrada. Os dados foram exportados para uma lista de Python. A Tabela 3 resume as variáveis usadas para o presente estudo.

Tabela 3: Resumo das variáveis
| # | Column | Not-Null Count | Dtype |
|---|---|---|---|
| 0 | 20390 non-null | object | |
| 1 | Type | 20390 non-null | object |
A variável PDF representa os dados extraídos do DDR. Trata-se da variável dependente que contém o texto que ajuda a classificar as operações. Cada linha desta variável representa uma atividade e é com base nestas atividades que os engenheiros conseguem classificar as operações de perfuração.
3.3. Modelo de redes neuronais
O modelo de ANN tenta imitar processos simplificados de aprendizagem biológica e simular algumas funções do sistema nervoso humano. Uma ANN consiste em unidades de processamento simples, chamadas de neurónios (Bishop, 1996). As ANNs consistem num modo de abordar problemas de AI (Barreto, 1997). As ANN provaram fornecer um alto nível de competência na solução de muitos problemas complexos de engenharia que estão além da capacidade computacional da matemática clássica e dos procedimentos tradicionais (Agwu et al., 2018).
Para tornar o trabalho robusto, os modelos de ANN escolhidos foram os que obedecem a critérios de multicamadas: redes recorrentes (recurrent) e redes de propagação para frente (feedforward), designados de LSTM e MLP, respetivamente. A escolha destes modelo deveu-se ao facto de outros modelos de ANN, como ADALINE e Perceptron, apresentarem resultados com pouca relevância em comparação com os modelos escolhidos (Jiang, Tang, Chen, Wang, & Huang, 2019). O estudo obedeceu a dois cenários diferentes (MLP e LSTM), com experimentação de cada atributo classificador para cada modelo de treino.
3.4. Multi-Layer Perception
O modelo MLP proposto é de três camadas com oito neurónios para cada camada. O número de camadas depende da complexidade do problema em estudo (Khan & Yu, 2016). Redes maiores, compostas por muitas camadas, conseguem “aprender” mais padrões. No entanto, assume um custo computacional elevado para além de que o overfitting2 pode surgir. Para o treino do modelo MLP foram definidos os parâmetros de entrada da Tabela 4.
Tabela 4: Parâmetros de entrada MLP
| Parâmetro | Descrição | Valores |
|---|---|---|
| hidden_layer_sizes | Número de neurónios na enésima camada oculta | (8, 8, 8) |
| alpha | Constante que multiplica o termo L1. | 1e-5 |
| max_iter | O número de iterações | 200 |
| solver | Tamanho do mini bach | lbfgs (é um optimizador na família de métodos quasi-Newton.) |
| Activation | Ativação para a camada oculta | Relu (a função de unidade linear retificada, retorna f (x) = max (0, x)) |
| Verbose | Níveis de log WARNING e INFO | True |
| random_state | Determina a geração de números aleatórios para inicialização de pesos e desvios | 40 |
3.5. Long Short-Term Memory
O modelo LSTM é de 64 camadas e épocas igual a 60. Em ANN, uma época corresponde a uma passagem completa pelo conjunto de treino. Para o treino do modelo LSTM foram definidos os parâmetros indicados na Tabela 5.
Tabela 5 Parâmetros de entrada LSTM
| Parâmetro | Descrição | Valores |
|---|---|---|
| input_length | Tamanho do vetor de sentença de entrada | 300 |
| units | Quantidade de células na camada LSTM | 64 |
| dropout_rate | Taxa de dropout da camada de entrada | 0.5 |
| bach_size | número de amostras a serem utilizadas em cada atualização do gradiente | 128 |
| optimizer | Tipo de optimizador | adam |
| epochs | Número de épocas | 10 |
| word_embedding_dim | dimensionalidade do word embedding pré-treinado | 50 |
| max_fatures | Quantidade máxima de palavras mantidas no vocabulário | 5000 |
| embed_dim | dimensão de saída da camada Embedding | 128 |
| loss | calcula a quantidade que um modelo deve procurar minimizar durante o treinamento. | binary_crossentropy |
3.6. Avaliação
Para avaliar os modelos de classificação as seguintes métricas foram adotadas (Ian Witten, Eibe Frank, Mark Hall, 2016): precisão (1), sensibilidade (2), F1-Score (calculado a partir da precisão e do recall) (3) e curva ROC (Receiver operator characteristic curve). TP, FP e FN correspondem ao número de verdadeiros positivos, falsos positivos e falsos negativos, respetivamente. A precisão é intuitivamente a capacidade do classificador de não rotular como positiva uma amostra negativa.
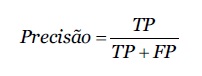 eq1
eq1
A sensibilidade é a capacidade de o classificador de encontrar todas as amostras positivas.
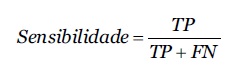 eq2
eq2
O F1-score, pode ser interpretada como uma média ponderada da precisão e recuperação
 eq3
eq3
A sensibilidade e a especificidade são características difíceis de conciliar, sendo complicado aumentar a sensibilidade e a precisão de um teste simultaneamente. As curvas ROC representam a relação entre a precisão e a sensibilidade de um teste diagnóstico quantitativo. Outra forma de avaliar o modelo é através da accuracy (ACC). É comum interpretar a qualidade dos valores da ACC como: 0,5 - igual a um classificador aleatório; 0,6 - razoável; 0,7 - bom; 0,8 - muito bom; 0,9 - excelente; 1 - perfeito (Landis & Koch, 1977).
4. Resultados e discussão
4.1. Classificador Multi-Layer Perceptron
O ACC foi 98%, com uma precisão de acerto de 98% para o NPT e 97% para o PT (Tabela 6).
4.2. Long Short-Term Memory
O ACC foi de 91%, com uma precisão de acerto de 93% para o NPT e de 91% para o PT (Tabela 7).
4.3. Análise dos modelos
A Tabela 8 apresenta um resumo dos resultados dos modelos.
Tabela 8 Resumo da análise do Modelo
| Modelo | ACC | Precisão | Sensibilidade | F1-Score |
|---|---|---|---|---|
| MLP | 0.98 | 0.98 | 0.95 | 0.96 |
| LSTM | 0.91 | 0.86 | 0.85 | 0.87 |
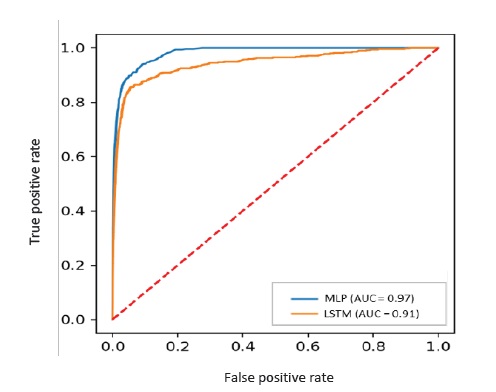
Face aos resultados obtidos, constatou-se que o modelo que apresentou melhor performance foi o modelo MLP (Figura 2). Por este motivo, o modelo MLP foi o escolhido para o presente estudo.
4.4. Interpretação do modelo
A curva ROC possibilita determinar a capacidade de previsão do modelo medida em termos dos acertos na classe real. A diagonal a tracejado representa um modleo aleatório. Logo, quanto maior for a área debaixo da curva ROC, melhor a capacidade do modelo de distinguir a classe objetivo.
Este estudo propõe modelos de previsão que, sendo ANN, não podem ser diretamente interpretados (Sérgio Moro, Cortez, & Rita, 2018). Como tal, para validar o modelo, foi usado o package Local Interpretable Model-agnostic Explanation (LIME) que permite validar a classificação de modelos tipo black-box. O LIME é um algoritmo que tem a capacidade de explicar as previsões de problemas de classificação ou regressão de maneira fiel, através de um modelo interpretável (Ribeiro, Singh, & Guestrin, 2016).
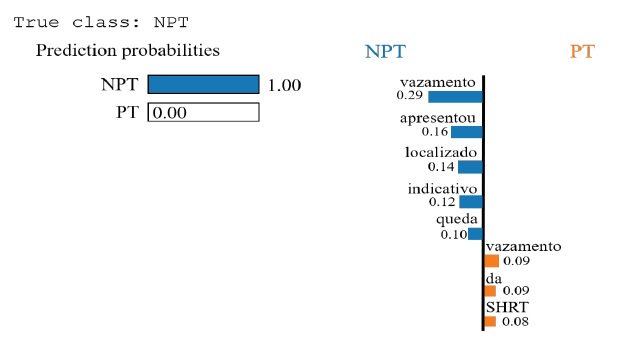
No modelo MLP, o LIME previu com uma certeza de 100% a classificação de NLP. Isto significa que há determinadas palavras que foram identificadas na MLP e que univocamente permitem classificar o NPT versus o PT. Portanto, relatórios que contenham as palavras “vazamento”, “apresentou”, “localizado”, “indicativo” e “queda”, claramente identificam tempo não produtivo (Figura 3). Estas palavras permitem a equipa de perfuração segregar os problemas e entender onde ocorrem e se aparecem nas mesmas frases. Se se entender que estas palavras estão sempre associadas à mesma frase, podem permitir à equipa de perfuração rever o programa e promover melhorias no processo.
5. Conclusões
O objetivo deste estudo passou por construir um modelo de IA usando ANN para classificar as operações de perfuração num poço de petróleo. Para atingir este objetivo, foram testados dois modelos para identificar o modelo com melhores resultados, validando o modelo ANN-MLP. Submetidas as análises de validação deste modelo através de gráficos ACC e de uma validação através do package LIME para garantir a interpretação do modelo, este foi considerado aceite para classificação de operações de perfuração. No que diz respeito ao desempenho do modelo MLP, os resultados obtidos nas métricas de precisão, sensibilidade e F1-score são satisfatórios e com uma avaliação de excelente (Landis & Koch, 1977).
O resultado deste estudo pode ser considerado uma vantagem competitiva para uma empresa que opera na área de Oil&Gas, pois consegue classificar as operações de perfuração, tornando o processo mais eficiente.
A descrição fornecida pelo modelo permite identificar eventos que estão a consumir tempo excessivo de sonda e contribui para o processo de minimização do NPT na perfuração do poço. Este modelo não só poderá trazer benefícios na redução de horas de trabalho à equipa de Drilling & Completion (D&C) e economizar recursos financeiros às empresas de Oil&Gas. Segundo números fornecidos pela equipa de D&C da Galp Exploração e Produção, em média, uma classificação normal é feita em cerca de 45 minutos, divididos em 15 minutos para leitura do relatório e 30 minutos para classificar manualmente as operações. Com o sistema de IA proposto, prevê-se uma poupança de 30 minutos por relatório. A leitura do relatório torna-se irrelevante e exigirá apenas validar a classificação fornecida pelo algoritmo e rever possíveis falhas. Estima-se que este processo dure cerca de 15 minutos. Isto significa que, para cada cinco relatórios diários, o sistema consegue poupar cerca de 2h30 de trabalho.
É de realçar que o ganho poderá aumentar com a evolução da aprendizagem contínua do modelo e, consoante a confiança e quantidade de dados que o modelo pode aprender, maior será a sua performance.
5.1. Limitações e propostas futuras
O presente estudo deparou-se com limitações, sendo que a maior foi o facto de não ser possível identificar, através do modelo, os problemas que podem ocorrer durante a perfuração. Esta limitação deveu-se ao facto de os dados serem confidenciais. Num futuro estudo, sugere-se identificar os problemas de perfuração e incluir junto destes resultados.
Com base nos dados do mesmo campo de exploração e, onde a geologia é semelhante, é possível, através do histórico, prever o tempo de duração de novos poços. Assim sendo, para trabalhos futuros, seria interessante apresentar um modelo de regressão capaz de prever o tempo de perfuração de um poço, com o objetivo de diminuir o tempo de sonda e otimizar a perfuração de novos poços.
Através do procedimento de identificação de problemas, será possível identificar o comportamento dos parâmetros para um caso real de Pack-off. O procedimento pode ser utilizado para evitar a ocorrência de problemas durante a perfuração do poço.

