










Serviços Personalizados
Journal
Artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkMedia & Jornalismo
versão impressa ISSN 1645-5681versão On-line ISSN 2183-5462
Media & Jornalismo vol.18 no.32 Lisboa abr. 2018
ARTIGO
O Jornalismo no contexto da Web Semântica
Journalism in the context of the Semantic Web
El periodismo en el contexto de la Web Semántica
Bruno VianaI
I Universidade do Porto, Faculdade de Letras, 4150-564 Porto, Portugal. E-mail: brvuno.viana@gmail.com
RESUMO
A emergência da web, enquanto plataforma de criação de conteúdo, veio a alterar a forma de se produzir e consumir notícias. Atualmente, as novas práticas jornalísticas influem não só na forma e conteúdo, mas também na relação dos jornalistas com o público. Com o desenvolvimento de novas tecnologias, conceitos como algoritmos, aplicações, base de dados, bolhas e filtros passaram a fazer parte das reflexões sobre os caminhos do jornalismo. Por meio de uma revisão de literatura sobre o tema, a intenção deste artigo é de refletir sobre as mudanças observadas no jornalismo, especificamente no que concerne às práticas profissionais, a partir do uso e desenvolvimento das novas tecnologias no âmbito da Web 3.0, a Web Semântica. A metodologia utilizada é a da pesquisa bibliográfica.
Palavras-chave: Algoritmos; Bolhas; Internet; Jornalismo; Web Semântica
ABSTRACT
The emergence of the web as a platform for production and content creation has changed the way we produce and consume news. Today, new journalistic practices influence not only the form and content, but also the relationship between journalists and the public. With the development of new technologies, concepts such as algorithms, applications, databases, bubbles and filters have become part of the reflections on the paths of journalism. Through a literature review on the subject, the intention of this article is to reflect on the changes observed in journalism, specifically regarding professional practices, from the use and development of new technologies in the scope of Web 3.0, the Semantic Web. The methodology used is that of bibliographic research.
Keywords: Algorithms; Bubbles; Internet; Journalism; Semantic Web
RESUMEN
La emergencia de la web, como plataforma de producción y creación de contenido, ha cambiado la forma de producir y consumir noticias. Actualmente, las nuevas prácticas periodísticas influyen no sólo en la forma y contenido, sino también en la relación de los periodistas con el público. Con el desarrollo de nuevas tecnologías, conceptos como algoritmos, aplicaciones, base de datos, burbujas y filtros pasaron a formar parte de las reflexiones sobre los caminos del periodismo. A través de una revisión de literatura sobre el tema, la intención de este artículo es reflexionar sobre los cambios observados en el periodismo, específicamente en lo que concierne a las prácticas profesionales, a partir del uso y desarrollo de las nuevas tecnologías en el marco de la Web 3.0, Web Semántica. La metodología utilizada es la de la investigación bibliográfica.
Palabras clave: Algoritmos; Burbujas; Internet; Periodismo; Web Semántica
Introdução
A evolução das potencialidades oferecidas pela Internet1, desde a sua liberação para uso comercial até os dias atuais, pode ser melhor compreendida a partir da divisão em três fases: Web 1.0 - a web de ligações de informação; Web 2.0 - ligações de pessoas - e a Web 3.0, a web de ligações de conhecimento (Aghaei et al, 2012). Em um primeiro momento, tem-se uma web que possibilitou uma massificação dos conteúdos informacionais, entretanto apresentava um perfil mais estático. Na segunda fase, os recursos da web já permitiam aos usuários interagir e produzir conteúdos.
Atualmente, considera-se que existe uma transição da Web 2.0 para uma nova demanda, a Web 3.0, onde se observa um ambiente mais dinâmico e participativo (Paletta e Mucheroni, 2015). Esta web é ainda marcada pelo de uso de aplicações em dispositivos móveis e pela abrangência no que é relativo às questões semânticas, onde as informações podem ser direcionadas de acordo com o perfil do usuário que busca a informação.
Os avanços da Internet e da Web 2.0, com o recurso da interatividade, também promoveram novos questionamentos sobre o papel do jornalista, na medida em que permitiram que qualquer usuário da web pudesse consumir informação e entretenimento, ao mesmo tempo também os produzir, o que Jenkins (2006) define por prosumer. Na transição da primeira fase do jornalismo online (onde se apenas reproduzia as produções da imprensa na web) para o modelo de Webjornalismo/Ciberjornalismo (produção específica para o ambiente online), segundo denominação de Canavilhas (2001), percebeu-se também um salto qualitativo na relação jornalismo-público.
A intenção deste artigo é de expor e refletir sobre as mudanças observadas atualmente no jornalismo, em específico nas práticas profissionais decorrentes, a partir do uso e desenvolvimento das novas Tecnologias da Informação e Comunicação (TICs) e aplicações no âmbito da Web 3.0, também conhecida por Web Semântica. Conceitos como Algoritmos, Aplicações, Base de Dados, Bolhas, Filtros e Mineração de Dados norteiam as reflexões sobre os caminhos do jornalismo nesta atual conjuntura.
Não se trata de apontar resultados ou caminhos a se seguir, mas, a partir da revisão de literatura sobre o tema, refletir sobre os novos encaminhamentos do jornalismo. A partir desta revisão, busca-se também descobrir possíveis linhas de investigação sobre o tema, que por ser atual e dinâmico apresenta constantes alterações. A metodologia utilizada é a da pesquisa bibliográfica.
Web Semântica: por uma delimitação
Também conhecida por Web Semântica (WS), ou Web Inteligente (Sabino, 2013), a terceira fase da web se apresenta como uma extensão da Web 2.0, segundo Berners-Lee et al (2001). Para o autor, nesta fase a informação está a ser definida de maneira mais eficiente, o que permite que pessoas e computadores possam cooperar de forma mais eficaz. Pode-se considerar que neste momento, os conteúdos online são disponibilizados no sentido semântico, ou seja, de maneira mais segmentada.
É importante observar que o termo Web 3.0 já foi utilizado há mais de uma década. Ainda em 2001, foi tratado na obra de Tim Berners-Lee e mencionado no jornal The New York Times em 2006, por John Markoff (Creamer, 2008).
Relativamente ao termo “Semântica2 ” que também batiza esta nova fase da web, deve-se ao facto desta nova fase estabelecer uma interligação dos significados das palavras, o que as possibilita de serem compreendidas por computadores (Santos e Nicolau, 2012). Corrêa e Bertocchi (2012) também a chamam de um espaço digital “desambiguado3 ”, já que as máquinas podem entender os significados dos dados sem informações sobrepostas.
Neste sentido, o usuário passa a ter menos tarefas, bem como, decisões enquanto utiliza a Internet. Novos sistemas informáticos passam a efetuar boa parte das ações antes reservadas aos utilizadores. Surgem, assim, os conteúdos “machine-readable”4 na web. O conteúdo machine-readable é estruturado de forma que seja legível tanto por humanos como por máquinas, o que proporciona um ambiente em que utilizadores e computadores possam trabalhar em consonância, com a transmissão de informações a ocorrer em tempo real, de forma mais prática, eficiente e imediata (Teixeira e Silva, 2013). Corrêa e Bertocchi (2012) afirmam que uma das utilidades óbvias desta fase da web é conferir semântica, ou “ontologias”5 ao conteúdo disponível no ciberespaço.
Um dos intuitos da Web 3.0 é ainda conectar, interligar e analisar dados provenientes de diferentes lugares, ou de diferentes data sets6 para se conseguir novos fluxos de informação. O objetivo também desta Web 3.0 está em colocar os computadores em primeira instância, ao invés dos utilizadores. Passa-se, assim, de uma Web de documentos interligados para uma Web de coisas (termo referente a conjuntos de dados) interligadas (Reis, 2016).
Entretanto, Paletta e Mucheroni alertam que este processo de indexação da informação é dotado de um nível de complexidade e que ainda não tem sido utilizado de uma forma generalizada. “A rede mundial de computadores ainda não consolidou a Web 2.0 e empresas já começam a desenvolver a Web 3.0” (2015: 10). Os autores, entretanto, acreditam que o uso e disseminação de dispositivos móveis irá ajudar na evolução da web, bem como na inclusão digital. Embora afirmem que a Web 3.0 ainda não esteja em todas as organizações, assumem que novas aplicações deste contexto já estão a circular (Paletta e Mucheroni, 2015).
O Jornalismo e a Web Semântica: novas práticas profissionais
Os impactos destas novas tecnologias e as reconfigurações das práticas jornalísticas daí derivadas ainda são temas de estudos, pois são transformações que ainda estão a ocorrer. Para Dimitra Milioni (2017), o jornalismo neste momento está em um fluxo de mudanças. Em estudo realizado junto a jornalistas do Chipre, a investigadora aferiu que o uso de mecanismos de busca e as interações de jornalistas com os públicos mudaram mais profundamente nos últimos cinco anos.
Para além disto, muitos dos jornalistas que participaram do estudo relataram aumento na jornada de trabalho, bem como, um acréscimo da influência relacionada ao mercado (pressões por lucro, por exemplo). A influência do público, por meio da produção de conteúdos - os UGC (User Generated Content), ou por envolvimento direto, durante o processo de produção noticiosa na redação, também tem marcado a rotina profissional dos jornalistas do Chipre. Ainda como resultado do estudo, Milioni aferiu que, em decorrência das diversas mudanças atuais, os padrões éticos dos jornalistas entrevistados têm vindo a enfraquecer substancialmente ao longo dos anos (Milioni, 2017).
Atualmente, a produção jornalística se inicia com a definição do formato e dispositivo em que tal produção será difundida. São debatidas e criadas estratégias de produção para formatos em múltiplos dispositivos, em um processo de produção crossmedia. De acordo com Bertocchi, Camargo e Silveira (2015: 64), é preciso definir soluções de usabilidade e design para produtos e serviços jornalísticos em pelo menos quatro canais: web (tela do computador), mobile (telas de dispositivos celulares), tablet (telas de dispositivos móveis de maior porte) e, ainda, o espaço físico mais tradicional (papel, por exemplo).
Neste contexto, Palacios et al (2015:14) acredita que os dispositivos móveis emergem como uma tecnologia definidora de novos padrões de produção, distribuição e consumo. Os autores tratam esses dispositivos como sendo “objetos particularmente promissores no âmbito dos estudos voltados para o surgimento e desenvolvimento de inovações em jornalismo”. Corrêa e Bertocchi (2012) destacam que todo o debate que está a envolver esta temática reflete manifestações ciberculturais contemporâneas e que alteram as formas de sociabilidade.
Uma das mudanças observadas nas redações jornalísticas está na utilização de bases de dados para a produção de conteúdos para a web. O uso de base de dados na construção das produções noticiosas levou à criação do conceito de Jornalismo Digital em Base de Dados (JDBD) por Barbosa, ainda em 2007. Sobre esse conceito, Lammel e Mielniczuk (2012:185) afirmam ser um jornalismo que usufrui das vantagens e funcionalidades das bases de dados, destacando-se em termos de “dinamicidade, automatização, flexibilidade, inter-relacionamento/hiperlincagem, densidade informativa, diversidade temática, visualização e convergência”.
Tal prática traduz-se num mosaico informativo de pequenas notícias ao invés de descrições únicas e extensas de um acontecimento (Fidalgo, 2007a). Devido à importância dada a determinado facto, as referências noticiosas poderão aumentar em número e detalhe, resultando numa visão mais pormenorizada de determinado acontecimento. Fidalgo (2007a) afirma que a princípio, a informação é dada em traços gerais, no sentido de responder às questões clássicas de um lead jornalístico (quem, o quê, quando, onde, como e porquê). Depois, as noticias que são sugeridas, e que estão correlacionadas ao tema, vão complementar a informação. “De certo modo, poder-se-ia entender essa sucessão de notícias como uma extensão da noção de pirâmide invertida, usada na feitura de uma notícia, a um conjunto de notícias sobre o mesmo evento” (Ibidem: 101).
Neste sentido, Fidalgo propôs o conceito de Resolução Semântica, que consiste em disponibilizar informação contínua aos utilizadores, como resultado de um jornalismo assente numa base de dados. Essa informação não remete exclusivamente para elementos escritos, já que há espaço para som e vídeo, o que contribui para o enriquecimento da notícia. Lammel e Mielniczuk (2012) referem que a interligação de notícias contribui também para a construção da memória, pelo facto de permitir o acesso a conteúdos anteriores. Atualmente, a utilização dos dados permite cruzar notícias que se complementam, as quais estão organizadas cronologicamente (Reis, 2016).
O crescente uso de bases de dados no jornalismo fez com que surgissem os processos conhecidos por Mineração de Dados (Data Mining) ou Descoberta de Conhecimento em Bases de Dados (KDD – Knowledge Discovery in Databases). Trata-se de dois processos de exploração de grandes volumes de dados, com o objetivo de detetar padrões e relações entre variáveis, de forma a criar novos subconjuntos de dados (Fidalgo, 2007b). Esse tipo de atividade é, atualmente, de grande importância económica, já que ajuda a identificar padrões de consumo e preferências dos usuários da web, o que se torna em informação de grande valia para as empresas. É importante perceber que este processo de mineração de dados pode ser utilizado no intuito de criar um novo tipo de notícia, com uma informação mais específica para o público. Para Barlow (2015), esse novo instrumental é conhecido por jornalismo de dados ou jornalismo digital. Para o autor, isto se configura em uma nova técnica de produção de notícias, a partir da grande quantidade de informação presente na internet.
Reis (2016) destaca que a mineração de dados permitirá a obtenção de informações inesperadas, através das quais são feitas correlações que podem ser transformadas em notícias relevantes. Segundo Fidalgo (2007b), o uso de algoritmos7 , que buscam e estabelecem padrões de comportamento e consumo, poderá propiciar uma evolução do jornalismo. Essa mineração de dados irá conferir maior rigor e objetividade, ainda de acordo com Fidalgo, o que resultará em uma melhor cobertura e um produto jornalístico mais preciso. Wooley (2016) destaca que o desenvolvimento tecnológico propiciou uma sofisticada arquitetura relacional dos sistemas de base de dados, o que permite que uma unidade ou módulos de informação sejam filtrados e automaticamente recuperados pelos algoritmos.
Em relação à questão das Bolhas ou das Filter Bubbles (Pariser, 2011), este termo se refere ao processo de uma maior personalização da informação disponibilizada ao usuário. Segundo Pariser, a filter bubble diz respeito ao resultado de uma pesquisa personalizada, fruto de um algoritmo, que apresenta resultados de pesquisa com base nas preferências, localização e histórico do utilizador na Internet. Com isso, tudo aquilo que seja contrário aos gostos do usuário é dispensado, isolando-o na sua bolha cultural e ideológica. “A existência destas bubbles será uma das alterações introduzidas pela chegada da Web Semântica” (Reis, 2016: 77). Abaixo (Figura 1), a exemplificação de como funciona uma filter bubble na web.
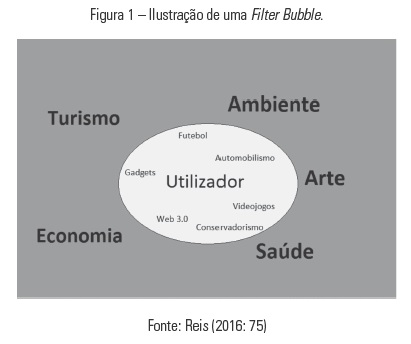
De acordo com Ben Smith (2017), editor-chefe do portal de notícias BuzzFeed, os usuários da web vivem em bolhas de filtros, especialmente no uso dos media sociais. “Qualquer pessoa que trabalhe com informação passou o último ano a observar como os media sociais afetam as opiniões das pessoas sobre o mundo, e como podem fechar esse mundo a opiniões dissidentes” (Smith, 2017). Seja na web ou por meio de aplicações (apps) para tablets e/ou dispositivos móveis, pode se observar uma larga utilização de algoritmos para lidar com a crescente massa informativa que está a circular no ciberespaço. Para Corrêa e Bertocchi (2012), o buscador Google e a plataforma Facebook são baseados no que chamam de “algoritmos curadores”, já que estes decidem qual a informação será disponibilizada ao usuário.
Reis (2016) afirma que os websites conhecidos como agregadores de conteúdos são exemplos do atual uso das filter bubbles. O autor cita o portal português Sapo, que reúne conteúdos de diversos outros websites e que, segundo Reis, pode contribuir para o aumento das fontes de informação dos utilizadores. Entretanto, a partir do seu próprio exemplo, o autor identifica que, na prática, o utilizador apenas tem acesso aos conteúdos dos parceiros do Sapo. A partir de estudos sobre o consumo de noticias na internet, Flaxman, Goel & Rao (2016) afirmam que uma há uma tendência de existir uma maior segregação ideológica quando o consumo de noticias ocorre em medias sociais, ou em websites de busca personalizado, se comparado com o consumo a partir de outras fontes, como por exemplo um portal jornalístico online.
Voltando à Pariser (2011), o autor considera que o uso em larga escala destes filtros, apesar de segmentar o conteúdo disponibilizado aos usuários, pode evitar também que este acesse o que deveria ver. Criam-se assim bolhas distintas, mas o utilizador que está dentro de cada uma dessas não consegue identificar o conteúdo que ficou de fora. Em relação ao jornalismo, Pariser acredita que os algoritmos estão a substituir o papel dos jornalistas. Apesar da capacidade de fazer chegar informação relevante ao usuário, não cumpre os requisitos deontológicos e éticos da profissão, o que segundo o autor é uma característica do ser humano e não da máquina. Isto revela-se numa situação negativa, já que temas complexos ou de difícil debate na sociedade podem não chegar aos utilizadores da web, por estarem fora de seus interesses pessoais. “Assim sendo, o futuro encaminha-se para que sejam algoritmos a ditar o que cada utilizador lê, ouve e fica a saber” (Reis, 2016: 78).
Para Gil Ferreira (2017b), tanto as empresas de media quanto os usuários contribuem para aumentar a complexidade deste processo polarizador das filter bubbles, que é resultante do uso de algoritmos. Segundo o autor, há uma tendência no mercado dos media informativos, que, em suas versões digitais, permitem e incentivam um nível de personalização no consumo da informação. Ou seja, o usuário pode assim criar uma própria versão do jornal, no sentido de aceder somente ao que seja de seu interesse. A mesma lógica também ocorre em sistemas de gravação de televisão ou de subscrição de programas de rádio em RSS8.
Ainda sobre os públicos, Gil Ferreira acrescenta: “Enquanto as fontes de notícias se expandem, também eles recorrem a tecnologias para filtrar e personalizar o acesso à informação, em acordo com gostos e interesses pessoais” (Ferreira, 2017a). Na mesma linha de pensamento, o autor cita Cass R. Sunstein, no livro “Republic.com 2.0”, que discute que quando o poder de filtrar é ilimitado, as pessoas poderão decidir com antecedência e precisão o que vão e o que não vão encontrar.
A respeito do uso dos algoritmos na produção jornalística online, Corrêa e Bertocchi (2012) acreditam serem dotados de um papel de curadoria, já que se trata de um produto derivado de um processo humano, ou seja, com critérios de escolha pré-definidos e baseados num contexto de informação. Para desenhar um algoritmo, é necessário elaborar uma série de instruções que visam resolver determinado problema. Segundo as autoras, o algoritmo é um código de programação computacional, executado com certa periodicidade e com um esforço definido. É um procedimento que pode ser executado não só por máquinas, mas também por seres humanos, o que segundo Corrêa e Bertocchi ampliaria a acuidade associada à personalização. Abaixo, ilustração que exemplifica o funcionamento de um algoritmo:
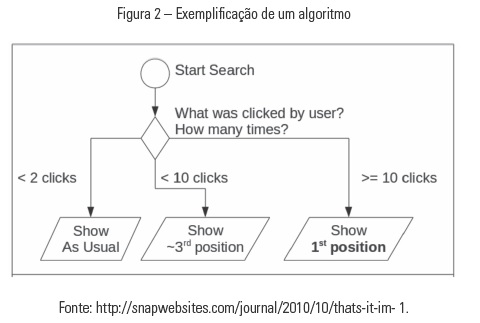
Reis (2016) destaca que em relação às produções jornalísticas publicadas na plataforma Facebook, o feed, ou alimentador, de notícias obedece a um algoritmo que ordena elementos por consoante a importância definida pelos programadores. No caso do Google, o algoritmo utilizado recolhe os dados do utilizador e disponibiliza a informação considerada mais útil e precisa. Gil Ferreira (2017a) reflete que há uma outra leitura a ser feita sobre o desenvolvimento dos media e sua relação com os públicos. Apesar da grande quantidade de meios de comunicação, as notícias e informações que estes meios fornecem são “altamente redundantes”, definindo, assim, uma agenda comum de debate.
Há pouco mais de uma década, estudos que comparavam a audiência dos 5 jornais em papel mais lidos nos EUA (que, juntos, somam 21,5% da audiência) com os cinco sites informativos mais consultados (41,4%), demonstravam que a atenção na Web é ainda mais concentrada que no mundo impresso. Mostravam ainda que muitas fontes online eram subsidiárias das fontes dos media tradicionais, resultando numa redundância entre as agendas dos dois ambientes. Muitos exemplos demonstram que o mercado dos media segue neste sentido. (Ferreira, 2017a).
O autor reflete sobre um importante tema que está relacionado com a disseminação da produção jornalística online: a questão do agendamento ou da agenda-setting9. Para Gil Ferreira, os media mainstream10 continuam a ter um poder determinante na definição da agenda da opinião pública. Neste sentido, os editores e jornalistas, antes principais detentores da função de gatekeeper, ou seja, definidores do que é ou não notícia, foram substituídos, em parte, pelos diretores de tráfego online e, em outra parte, pelos públicos consumidores dos media digitais (Ferreira, 2017b).
Em relação ao que Ferreira chama de diretores de tráfego online, Anderson, Downie e Schudson (2016: 100-101) os definem como sendo os programadores de algoritmos (aqueles que determinam as noticias que são mais facilmente encontradas em websites de busca); os analistas de dados digitais (que investigam quais conteúdos atraem mais tráfego aos seus websites); e, por último, aos curadores de conteúdos personalizados nos novos media. Anderson, Downie e Schudson unem esses três tipos de novos profissionais da web em uma perspetiva comum: ambos possuem uma mesma expetativa em relação às audiências online que aquela que havia em relação aos públicos dos meios offline.
Ao se referir aos media sociais e ao considerar o elevado número de utilizadores, Gil Ferreira (2017a) acredita que é possível criar uma agenda alternativa de temas, com valor informativo, alternativa ao que é selecionada pelos editores dos media mainstream. O autor acredita que, em muito casos, as estórias são trazidas, em um primeiro momento pelos novos media, mas depois contextualizadas e validadas pelos media convencionais. Entretanto, Gil Ferreira afimra que, em todo caso, permanece a reapreciação da noção de agendamento.
A partir de estudos realizados em 2013, Christian Fuchs identificou que os vídeos mais vistos no Youtube, bem como as interações mais comuns no Facebook, ou mesmo as pesquisas realizadas no Google, evidenciaram que as grandes empresas internacionais de media, juntamente com outras organizações, controlam a economia política da atenção dos públicos nestas plataformas. Ainda como resultado do estudo, Fuchs concluiu que a música e o entretenimento, em geral, são os temas mais populares. Já a política não chega a ultrapassar um nível menor de interesse.
A internet e os média sociais são hoje espaços estratificados e não participativos, onde a atenção colonizada é dominada pelas grandes corporações e pelos atores sociais e políticos mais poderosos, que, também nestes espaços, centralizam a formação do discurso e da opinião (Fuchs, 2014: 100-103)
É importante destacar o acordo firmado pelo Facebook com grandes empresas de media para distribuição de conteúdo informativo (Bittencourt, 2015). Em 2015, empresas de media como o The New York Times, o BuzzFeed, a NBC News, a National Geographic, o The Guardian, a BBC, a Bild, a Spiegel online e a The Atlantic acordaram termos para a publicação de conteúdo no Facebook. Bittencourt (2015) questiona o facto destes veículos já utilizarem o Facebook em suas rotinas produtivas, através de fanpages. A autora reflete sobre a centralização no processo de seleção do que será ou não difundido, que exclui o público e privilegia o uso dos algoritmos. “Essa aproximação entre veículos e Facebook não espanta, diante do crescimento do site, com seus mais de 1,4 bilhão de usuários” (Bitterncourt, 2015:131).
Para o investigador de Columbia C.W. Anderson (2011), a curadoria jornalística com recurso a algoritmos pode ser inserida em um campo de estudo emergente – a sociologia do algoritmo. Trata-se de um “jornalismo de algoritmos”. Segundo Anderson, o algoritmo desempenha um papel social e técnico relevante no que diz respeito à mediação entre jornalistas, audiência e conteúdos. Após realizar uma pesquisa junto das redações de jornais norte-americanos, o autor assegura que o jornalismo de algoritmos é uma opção viável para que os jornais aumentem o seu conhecimento e compreensão em torno do seu público.
Em uma linha de pensamento diferente, Corrêa e Bertochi consideram que um algoritmo não deve ocupar a função de editorialização de informação. As autoras afirmam ser importante refletir sobre o papel do jornalista-curador nesta atual conjuntura, no intuito de definir “o estabelecimento de uma relação entre sofisticação do algoritmo e correspondente intervenção humana especializada (o jornalista) no processo de sua construção” (2012: 137). E acrescentam que quanto maior for o volume de informação, mais importante será a presença do elemento humano, juntamente com o algoritmo. O jornalista, com base nos seus conhecimentos de mundo e de ética, pode agir de forma a fazer chegar informação relevante ao público.
Gil Ferreira (2017a) acredita que o enfraquecimento do papel do jornalista, enquanto filtro possui oportunidades e perigos. O autor relembra a função clássica de gatekeeper desempenhada durante décadas na definição do agendamento social. Segundo Ferreira, havia uma reflexão sobre quais ideias podiam ser discutidas pelo público e quais eram demasiado radicais, não fundamentadas e que não se traduziam em um contributo cívico.
É possível hoje notar como a ausência de um padrão mínimo de ordem discursiva dificulta, de modo diferente, o debate, a intercompreensão e o entendimento sobre questões de interesse comum (Ferreira, 2017a).
Considerações Finais
A partir das reflexões empreendidas, percebe-se que o desenvolvimento da Internet e das aplicações da Web tem promovido mudanças contínuas no jornalismo, seja na forma de produção, veiculação e na adoção de novas linguagens e práticas profissionais. Considera-se que o surgimento dos dispositivos móveis, a necessidade constante de aprendizado tecnológico, a identificação da audiência e uma busca por novas linguagens e mais proximidade com o público são alguns dos desafios inerentes à prática jornalística nos dias atuais.
Relativamente ao jornalismo e a Web semântica, conclui-se que essa relação ainda é pouco explorada. Percebe-se que muitas das inovações desta fase da Web já se encontram em uso, porém para autores como Paletta e Mucheroni (2015), ainda não são usadas em larga escala. Considera-se que o uso de base de dados no jornalismo recorre aos recursos de interatividade e memória (com a interligação de noticias), potencializando características que já compõem o Ciberjornalismo. Em relação ao uso dos algoritmos, enquanto filtros, e que resulta na formação das bolhas e na segmentação dos conteúdos disponibilizados, reflete-se que estes não devem ocupar o papel de editor das informações jornalísticas. Com um crescente volume de informação a circular, seguido de uma também crescente segmentação, seja em websites jornalísticos ou nos media sociais, o usuário pode ficar sem acesso à informações relevantes. Conforme refletido, o jornalista, no papel de curador de conteúdos e com base nos seus conhecimentos de mundo e de ética, pode agir de forma a fazer chegar informação relevante ao público.
Entende-se que as reflexões apresentadas neste artigo tratam de temas complexos, sobre um fenómeno contemporâneo e em mudança. No momento, tem-se a consciência de que as reflexões são pouco conclusivas, no sentido de apontar caminhos, mesmo não sendo este o objetivo inicial. A partir das considerações realizadas deixa-se o espaço para novos apontamentos que poderão ser feitos em futuros trabalhos.
Referências Bibliográficas
Anderson, C.; Downie, L. & Schudson, M. (2016). The News Media, What everybody needs to know. Oxford: Oxford University Press. [ Links ]
Anderson, C.W. (2011). Deliberative, Agonistic, and Algorithmic Audiences: Journalism's Vision of its Public in an Age of Audience Transparency. International Journal of Communication 5 (2011), (529–547). [ Links ] ISBN 1932–8036/20110529.
Aghaei, S. et al (2012). Evolution Of The World Wide Web: From Web 1.0 To Web 4.0. International Journal of Web & Semantic Technology IJWesT, 3 (1): 1-10. [ Links ]
Barbosa, S. (2007). Jornalismo Digital em Base de Dados (JDBD): um paradigma para produtos jornalísticos digitais dinâmicos. Tese de doutoramento, Facom/Ufba, Salvador.
Barlow, M. (2015). Data Visualization: A New Language for Storytelling. Sebastopol: O'Reilly Media Inc. [ Links ]
Berners-Lee, T.; HendleR, J.; Lassila, O. (2001). The Semantic Web. Scientific American 284, no. 5 (May): 34-43. Retrieved from http://www.nature.com/doifinder/10.1038/scientificamerican0501-34.
Bertocchi, D.; Camargo, I. O.; Silveira, S. C. (2015). Possibilidades narrativas em dispositivos móveis. In Canavilhas, J.; Satuf, I., Jornalismo para Dispositivos móveis: produção, distribuição e consumo. Livros Labcom, Covilhã, [ Links ] UBI.
Bittencourt, M. C. A. (2015). Midiatização do ativismo e jornalismo digital: o impacto dos filtros do Facebook nos processos de produção e circulação de conteúdos de coletivos midiáticos. Revista LatinoAmericana de Ciéncias de la Comunicacíon. 1222 (Junho): 124-133.
Campos, L.F. de B. (2007). Web 2.0, biblioteca 2.0 e ciência da informação: um protótipo para disseminação seletiva de informação na web utilizando mashups e feeds RSS. In: Encontro Nacional de Pesquisa em Ciência da Informação, [ Links ] 8., 2007, Salvador. Anais... Salvador: UFBA
Canavilhas, J. (2001). Webjornalismo. Considerações gerais sobre jornalismo na web. BOCC. Retirado de http://www.labcom.ubi.pt/sub/investigador/af1bdcf390cdebbc3f9f3ae31c050102#sthash.UM8JZIAJ.dpuf.
Corrêa, E.S. e Bertocchi, D. (2012). A Cena Cibercultural do Jornalismo Contemporâneo: Web Semântica, Algoritmos, Aplicativos e Curadoria. MATRIZes 2. São Paulo: Universidade de São Paulo (123-144).
Creamer, M. (2008). It's Web 3.0, and someone else's content is king. Advertising Age 79(15): 75-76. [ Links ]
Fidalgo, A. (2007a). A resolução semântica no jornalismo online. In Barbosa, S., Jornalismo Digital de Terceira Geração(pp. 101-111). Covilhã: Labcom. [ Links ]
Fidalgo, A. (2007b). Data Mining e um novo jornalismo de investigação In Barbosa, S., Jornalismo Digital de Terceira Geração(pp. 155-168). Covilhã: Labcom. [ Links ]
Ferreira, G.B. (2017a). Quem define a agenda na internet? Retirado de http://pt.ejo.ch/jornalismo/define-agenda-na-era-da-internet. [ Links ]
Ferreira, G.B. (2017b). O “meu jornal” e o interesse público: Implicações cívicas do agendamento na era dos novos média. Revista Comunicando 6, 1 (Julho): 83-102. [ Links ]
Flaxman, S.; Goel, S.; Rao, J. (2016). Ideological Segregation and the Effects of Social Media on News Consumption. SSRN Scholarly. New York.
Fodor, J. (2007). Semântica: uma entrevista com Jerry Fodor. 2007. Tradução de Gabriel de Ávila Othero e Gustavo Brauner. ReVEL. 5 8.
Fuchs, C. (2014). Social Media: A critical Introduction. Londres: Sage. [ Links ]
Jenkins, H. (2006). Convergence Culture. Where old and new media collide. New York: New York University Press. [ Links ]
King, B. E.; Reinold, K. (2008). Finding the Concept, Not Just the Word. A librarian's guide to ontologies and semantics. Oxford, UK: Chandos.
Lammel, I. e Mielniczuk, L. (2012). Aplicação da Web Semântica no jornalismo. Estudos Em Jornalismo e Mídia 9 (1), Universidade Federal de Santa Catarina: 180-195.
McCombs, M. E. & Shaw, D. L. (1972). The Agenda-Setting Function of Mass Media. The Public Opinion Quarterly 36 (2) [ Links ]
Milioni, D. L. (2017). Journalists in Cyprus - Worlds of Journalism Study report. Cyprus University of Technology. Retrieved from https://www.academia.edu/31265063/Milioni_Dimitra_L._2017_Journalists_in_Cyprus_-_Worlds_of_Journalism_Study_report. [ Links ]
Palacios, M., Barbosa, S., Da Silva, F. F., & Da Cunha, R. (2015). Jornalismo móvel e inovações induzidas por affordances em narrativas para aplicativos em tablets e smartphones. In Canavilhas, J; Satuf, I. (Orgs), Jornalismo para dispositivos móveis: produção, distribuicão e consumo (pp. 7-42). Livros Labcom. [ Links ]
Paletta, F. e Mucheroni, M. (2015). Web Semantica, Agentes Inteligentes e a Produção de Conhecimento na Web 3.0. Comunicação apresentada na CONTECSI – 12.a Conferência Internacional sobre Sistema de Informação e Gestão de Tecnologia. Retirado de http://www.contecsi.fea.usp.br/envio/index.php/contecsi/12CONTECSI/paper/view/2918/2317.
Pariser, Eli (2011). The Filter Bubble: What the Internet Is Hiding from You. Publisher: Penguin Press HC. Kindle Edition.
Reis, R. L. D. P. (2016). O jornalismo em Portugal e os desafios da Web 3.0. Dissertação de mestrado. Universidade Católica Portuguesa, Lisboa. [ Links ]
Sabino, J. (2013). Web 3.0 e Web semântica - Do que se trata? Retirado de http://www.cin.ufpe.br/~hsp/Microsoft-web.pdf. [ Links ]
Santos, E. e Nicolau, M. (2012). Web do futuro: a cibercultura e os caminhos trilhados rumo a uma Web semântica ou Web 3.0». Revista Temática 10. Retirado de http://www.insite.pro.br/2012/Outubro/web_semantica_futuro.pdf. [ Links ]
Skiena, S. S. (2008). The Algorithm Design Manual, 2. Edição Springer-Veriag London. [ Links ]
Smith, G. (2017). BuzzFeed Tries Way to Break Readers Out of Social-Media Bubbles. The Washington Post. Retrieved from https://www.bloomberg.com/news/articles/2017-02- 17/buzzfeed- tries-way-to-break-readers-out-of-social-media-bubbles. [ Links ]
Teixeira, M. e Silva, M. (2013). Hiperligações no ciberespaço: interatividade, comunicação e educação. Revista Temática 10, Porto Alegre: Temática Publicações. Retirado de http://www.insite.pro.br/2013/Outubro/hiperligacoes_ciberespaco_interatividade.pdf.
Woolley, S. C. (2016). Automating power: social bot interference in global politics. First Monday 21(4), pp. 1-13. Retrieved from http://rstmonday.org/ojs/index.php/fm/article/view/6161/5300.
Recebido / Received / Recibido: 23/06/2017
Aceite /Accepted /Aceptación: 01/10/2018
Notas
1 É a infraestrutura necessária para uma de suas maiores e mais conhecida aplicações: a Web. Internet e Web são, portanto, conceitos distintos. A Web pode ser definida, em suma, como a parte da internet acessada por meio de navegadores, ou browsers. (Paletta e Mucheroni, 2015).
2 “Em particular, é a parte da gramática que se preocupa com as relações entre os símbolos da língua e as coisas no mundo a que eles referem, ou sobre as quais mantêm condições de verdade” (Fodor, 2007:1).
3 “Importante lembrar que a Comunicação trabalha, em seus diferentes processos narrativos, com o recurso da ambiguidade para persuadir, fazer crer, informar, contextualizar. Daí a importância do comunicador como mediador e municiador ativo da aplicabilidade da WS” (Corrêa e Bertocchi, 2012: 126).
4 Legível por máquina (Tradução livre).
5 King & Reinold (2008: 8) afirmam que é uma “coleção de conceitos, organizados em uma hierarquia de categorias, combinados com as relações entre os conceitos, afim de refletir o vocabulário de uma área de conhecimento”.
6 Conjunto de dados (Tradução livre).
7 O termo algoritmo, na área da computação, corresponde a um “procedimento criado para cumprir uma tarefa específica” (Skiena, 2008: 3).
8 Really Simply Syndication. “O termo syndication refere-se originariamente à distribuição do trabalho de um colunista ou cartunista para muitos jornais, assim como à venda de, por exemplo, séries televisivas para estacões locais. Web syndication é o processo de disponibilizar conteúdo publicado em um sítio para utilização por outros sítios. RSS, em sua última forma, é um acrónimo para Really Simple Syndication. Feeds RSS pertencem a uma classe de “alimentadores” utilizados para atualização constante de conteúdo na Web, como ocorre em blogs ou sítios de notícias” (Campos, 2007: 10).
9 Conceito que afirma que os media selecionam, filtram e distribuem a informação ao público. Por meio deste processo, os media teriam o poder de destacar ou ignorar um determinado assunto em prol de outros (McCombs e Shaw, 1972).
10 Convencionais, tradicionais (Tradução livre).
Bruno César Brito Viana - Doutorando em Informação e Comunicação em Plataformas Digitais na Universidade do Porto, Portugal. Investigador-Bolsista da Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - CAPES. Ex-professor de jornalismo no Brasil, do departamento de Comunicação Social da Universidade Federal do Rio Grande do Norte (UFRN). Mestre em Estudos da Mídia, pelo Programa de Pós-graduação em Estudos da Mídia (PPgEM/UFRN) em 2014. Jornalista graduado pela UFRN, em 2011. Experiência em assessoria de comunicação, editoração e TV. Desenvolve investigações sobre o Brasil no contexto do jornalismo internacional e ciberjornalismo.

