











 Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
1. Introduction
The increasing amount of information online is exceeding our ability to process it. All of us know the feeling of being overwhelmed by the number of new videos, news articles and social media content published every day, and services such as YouTube, Facebook and TikTok have dramatically reduced the barriers to publishing content for the whole world to see. Content burden, or infobesity, is clearly a problem that requires the attention of both academia and the companies that develop these platforms. There is a need to separate the signal from the noise and offer people information that is relevant to their interests (but also offer different points of view, in order to avoid the “filter bubble”, explained later in this article). During the last 10 years, this problem has been tried to fix with the help of algorithm-based recommendation systems that offer content based on metadata analysis and lately also on the analysis of content qualities. But these systems have their problems, and in addition to trying to fix them, a more traditional solution has been brought back: human curation. Human-based curation was an academic topic of interest in the beginning of 2010s, but the research on this topic has been mostly overtaken by research on algorithms and recommendation systems. In recent years, though, many content-rich companies have attempted to get back to human curation. Some examples include Instagram with their IGTV (Systrom, 2018), Amazon buying Goodreads, a personal book review site (Bhaskar, 2016), and also Spotify’s increase of human curation in music playlists (Kollewe, 2016). YouTube was planning a “curated future” as early as in 2012 (Rosenbaum, 2012), but for some reason this vision never came to reality, and to this day YouTube relies on its current, algorithm-based video recommendation system. But the advantages of human curation are evident, and today humans are superior to computers in several ways. For example, we have an innate ability to inspect subjects in a holistic way, and us humans can use our emotions to find deeper meanings in various types of content. Whereas computers are analyzing patterns, we are driven by curiosity. Humans can also categorize content effectively without the need of extensive metadata. These advantages make us especially well-suited for analyzing specific type of content.
One form of content that is extremely popular among people around the world is video. Cisco has predicted that by 2022, video will account for 85% of all web traffic (VNI, 2018). In addition to often subscribe-based streaming services such as Netflix and Hulu that provide long-form videos such as TV shows and movies, one extremely popular form of video is short-form video. An official definition for short-form video is still lacking, but in general they range anywhere from one second to one minute. They are often related to Internet Video Culture, where content in general has an extremely short relevance window, after which they often disappear into obscurity. This, in addition with the lack of relevant metadata, often makes it extremely difficult for algorithms to detect their relevancy. In contrast to music, people do not watch online videos more than once, so engagement data is very limited. Also, in contrast to traditional news content, videos do not come regularly from known sources. Instead, they are published at random intervals by a much wider pool of creators. One of the biggest success stories with short-form video is the video-sharing social networking service TikTok, which was launched in 2017 and became hugely popular in 2018. The popularity and impact of short videos has also been noticed by older platforms such as YouTube and Snapchat, who show short advertisements ranging from 5 to around 15 seconds. This format seems to be suitable for the modern times, where multitasking is common practice (Shirky, 2008) and where our collective attention span has reduced (Lorenz-Spreen et al., 2019). Based on their popularity, short-form videos seem to be relatively lucrative business model for both the companies owning the platforms, and for the creators, when combined with short form advertisement (Brown, 2020).
Short-form videos are often closely related to Internet’s meme culture. The concept of a meme can be traced back to Richard Dawkins’ book The Selfish Gene, where he referred it as a “concept for discussion of evolutionary principles in explaining the spread of ideas and cultural phenomena” (Dawkins, 1976), but has evolved in its digital context to something else. Nooney & Portwood-stacer, (2014) defined this evolved form of memes as “digital objects that riff on a given visual, textual or auditory form and are then appropriated, re-coded, and slotted back into the internet infrastructures they came from.” In this study, memes are referred within the context of short-form video and curation. For a more thorough analysis on memes and meme culture, see (Graham & Dutton, 2014, and Wiggins & Bowers, 2015).
This research focuses on comparing different aspects of human curation and algorithm-based recommendation systems. Even though different domains where curation is used are outlined in this work, the focus of this work is on short-form video. Algorithm-based systems have several pitfalls when analyzing this type of content, and our research explores if human curation would be beneficial in this area. When comparing algorithms and human curation, we refer to state-of-the-art research conducted on both domains. The study attempts to find answers to the following research questions:
RQ1: What are the main characteristics and differences between algorithm-based and human curation?
RQ2: How can these two methods be used to complement each other?
This paper is structured as follows: after this introduction, we outline background and related work on both human curation and algorithm-based recommendation systems. We also compare these two methods and analyze their problems and challenges. In the Discussion part, we summarize the implications of these findings, and theorize how they could be overcome. We also provide a model for combining these two.
2. Human Curation versus Algorithm-based Recommendation Systems
Human Curation
In essence, curation is about people adding their qualitative judgement to the content that is being gathered and then organized (Rosenbaum, 2011). Curation has a long history in library environments and also in the art world. In the latter, curators have conventionally functioned as gatekeepers and as arbitrators of taste (Ames, 2007). Art curators attempt to recognize emerging trends in the art world and try to bring previously unknown artists to our attention (or delegate others into oblivion). Famous art curators such as Hans Ulrich Obrist and Okwui Enwezor carry a position of great trust and authority and are well listened by art fans around the world. The primary goal of museums is to bring art to the public, which is carried out by the curators. Therefore, they serve as mediators between the artist and the museum visitors as they select and organize the art objects for the exhibitions. This makes the work of curators critical to success within the art world (Joy & Sherry, 2003). From the curatorial perspective, the most essential part of any museum is its permanent collection. Curators are responsible for the principal parts of this collection, including its contents, classification and when and how it is exhibited for the audience. Curators also often add their interpretation of the art exhibited, making them “knowledge brokers of a specific nature, taking culture created by others, and interpreting and publicizing it for the public good” (Villi et al., 2012). They scour the globe for artefacts related to the topic and organizes them in such a way as to take guests on a journey as they experience the exhibit. (Dale, 2014).
With the same basic concept and idea in the background, curation as a practice has extended beyond libraries, galleries, and museum exhibitions into different areas of online content creation and sharing. In today’s online communities, words curate and curator are often associated with activities such as selecting and presenting (Schlatter, 2010), but for example in the context of Internet Video, the interpretation aspect has become more prevalent in form of reaction videos, where content curators provide metalevel commentary on different content types, e.g. on movie trailers, competitions or general viral videos. One of the largest reaction video content creators, REACT, has over 20.1 million subscribers (information retrieved on 20.1.2021).
Steven Rosenbaum, the author of book Curation Nation (Rosenbaum, 2017), declared five laws of the curation economy as follows:
People do not want more content, but less. The flow of raw and unfiltered information is overwhelming, and people want it to stop.
Curators come in three different shapes: Curation Experts, Editorial Curators, and Passion-Driven Curators. Experts are people whose background and depth of understanding makes their curation valid. In Rosenbaum’s words, “If you’re looking for medical advice, you want your video viewing curated by a doctor, not a patient”. Editorial Curators manage the editorial content of the publications and sites they are responsible for. Finally, the Passion-Driven Curators curate content they are passionate about.
Curation is not a hobby; it is both a profession and a calling. Curator should be compensated for their effort based on their contribution in this emerging ecosystem. Rosenbaum states that the economic basis of curation is both essential and inevitable.
Curation requires technology and tools to find, filter, and validate content at the speed of the real-time web.
Curation within narrow, focused, high-quality categories will emerge to compete with the mass-media copycats who are filling the curation space with lists, cat videos, and meme links.
As one of Rosenbaum’s laws states, there can be both amateur and professional curation. Villi, Moisander, & Joy (Villi et al., 2012) categorized the former as social curators, and additionally categorized them as ordinary customers. By their definition, social curators are not necessarily making their content choices based on expertise (e.g. in art or journalism), rather than on informed opinion, involving some level of accountability and liability. This, however, limits the definition of professional curation to people who have some form of official certificate to prove their expertise. Would for example people who work as curators, e.g. curating music or videos, without any kind of certification, be considered professional or social curators? Or both? In the recent years, this line has faded as more and more of active users and content creators have been recruited for curation purposes. Villi, Moisander, & Joy (Villi et al., 2012) also challenged this view by stating that your online presence and influence can be a bigger factor in successful curation, i.e. distributing the content as extensively as possible, than your expertise on a particular topic.
Algorithm-based Recommendation Systems
Recommendation systems (sometimes also referred as recommender systems) are a method of information filtering that aims to predict preference or rating that the user would give to an item (e.g. videos, songs, books, articles) they had not yet experienced. These systems also generally make their suggestions based on two types of data: explicit and implicit. For example, with videos, explicit content incorporates structured metadata such as movie/video genre, its description, director and/or actors, etc. or other unstructured data from external sources, such as views, likes and shares. A lot of research has focused on building recommendation systems based on explicit data (see e.g. Deldjoo et al., 2016; Basharat et al., 2008; Basu et al., 1998), but with videos, these systems are not very accurate because of the huge amount of content being generated in today’s web. This has caused many researchers to study recommendations based on the implicit features of the content. Again, with videos, implicit content could include the content’s visual features such as lighting, color, shape, motion, plot, and other aesthetics (Kumar et al., 2019).
Some recommendation systems are built using a model based on the characteristics or metadata of the content or the user’s social environment. The former is referred to as content-based approach, and the latter is known as collaborative filtering approach. Also, hybrid models of these approaches have been developed (Pazzani & Billsus, 2007). Many current services and platforms use algorithms that rely on collaborative filtering, but the technique itself is not new - Goldberg et al. (1992) implemented a collaborative filtering-based recommendation system in as early as 1992, and Resnick et al. (1994) used it in Usenet news groups in the mid-nineties. In collaborative filtering, the system obtains users’ opinion or rating on items by asking them explicitly or by observing implicitly how they interact with the system and its items. These ratings are stored in a database that is known as the user-item rating matrix. Then, different similarity measurement methods can be applied to identify those users who have similar preferences or to find items that are similar to those that the user kept in high regard in their ratings. The reason why collaborative filtering is the most applied and successful technique in recommendation systems, is because it often recommends unanticipated content to the user. (Najafabadi et al., 2019)
Recommendation systems are widely used in commercial systems, and for example Amazon, Twitter and Netflix still rely heavily on them. But these systems have their problems and pitfalls, and we will discuss them further later in this paper.
Comparing Human Curation and Algorithm-based Recommendation Systems
Many see that the role for human and algorithm-based curation are very different and can offer a greater potential when used as complementary (rather than competing) methods of providing content. The main differences between human curation and algorithms are as follows:
Human curation is usually based on curiosity, whereas algorithms analyze specific patterns from sets of data. Humans can also base their judgement on context, thus being able to evaluate potential impact of the content and assess if there is missing data.
Human curation builds on cumulative intelligence and exchange of information. Nearly all the big technological innovations (including algorithm-based recommendation systems) today are based on cumulation of information and exchange of information between innovative minds. Fusion of different ideas to create something larger than the sum of the parts is a uniquely human phenomenon, and one of the biggest limitations of AI-based curation today.
Human curators can take into account factors that are very challenging to measure. For algorithms, it is very difficult to measure and detect motivations and intensity of the content. Humans have the intrinsic ability to understand emotional context and the motivational forces behind them.
IPSOS, a company that focuses on combining human and algorithm-based curation, describe the key differences (and complementary qualities) of the two in a following way (Table 1):
Table 1. between algorithm-based and human curation
| Algorithm-based curation | Human curation |
|---|---|
| Patterns | Curiosity |
| Answers | Questions |
| Specific | Holistic |
| Behavior | Motivation |
| Output | Impact |
| Data | Culture |
| Knowledge | Wisdom |
From: Roy, 2018
Problems with Human Curation and Videos
When comparing human curation to algorithm-based recommendations, the most evident challenge with human curation is its slowness. When compared to computers, humans are extremely slow at processing big amounts of data for long periods of time. This can become a problem when the amount of data becomes exponential, as curating all the incoming content becomes impossible for even a large pool of human curators. On the other hand, the slowness could also be considered an asset in the curation process - a thorough analysis on the content may provide better end result, curation-wise.
With humans, there is also always the possibility of bias. When curating content, can we put aside our biases and judge the content objectively? Probably not. This can cause several problems, and one of the more severe ones is what Pariser (2011) called “The Filter Bubble”. In this “bubble”, the content that we consume becomes so reduced in diversity, that we may ultimately become partially blind to other kinds of information. Of course, this problem is also present in algorithm-based recommendation systems, but whereas these systems aim to gain as many eyeballs as possible regardless of the topic, with humans, factors such as political and religious views can drive the curation through a very narrow scope. For example, on social news aggregator Reddit, users are heavily focused on news sources reflecting their own political leaning (Soliman et al., 2019). It is worth noting, that this problem is not rare in artificial intelligence driven systems, either (e.g. Hayasaki, 2017).
Biases can also lead to different forms of gatekeeping. Originally gatekeeping refers to the role of journalists and editors to select and narrate various events. Shoemaker et al. ( 2001, p. 233) defined it as “the process by which the vast array of potential news messages are winnowed, shaped and prodded into those few that are actually transmitted by the news media.” But the term has been widely taken into use on other platforms than the news media - it is very common phenomena for example on video and social media platforms (incidentally, beforementioned Reddit even has its own community for reporting cases of gatekeeping). It is worth noting, that when curating for a specific platform, the platform provides the evaluation criteria and the policies for the content. It does not remove the possibility of bias and gatekeeping but transfers the responsibility to the platform rather than to the individual doing the curation.
Problems with Algorithm-based Recommendation Systems and Videos
The sheer amount of video content uploaded online tells about the abundance of streaming material - in 2019, Youtube’s users uploaded more than 500 hours of fresh video per minute (Hale, 2019). Thus, a tremendous number of videos are made available for the audience at a very fast pace. In addition, the amount of metadata that comes attached to these videos often ranges from none to highly limited, and is also often incorrect, i.e. unrelated to the actual video content (Davidson et al., 2010). The generated content is also in short-form (shorter than 10 minutes) and naturally has no views. This is still a huge problem for video recommendation systems as they must analyze content that is unaudited, un-rated and contains no additional metadata (or in worst case, incorrect metadata). In recommendation system literature this type of situation is called a cold start problem. Most of the work and research on video recommendation systems have been made with long-form videos such as movies and TV shows, and a lot of the challenges with recommendation systems stem from this problem. The work done on this is often driven by streaming companies such as Netflix and Hulu. Hulu even organized a challenge on Content-Based Video Relevance Prediction (CBVRP) in order to tackle the cold start problem they face with their content (Wang et al., 2019).
Another challenge with recommendation systems is the data sparsity problem. This problem arises when most users give ratings to a small proportion of items, which leads to difficulties in finding sufficient and reliable matches from the database (Guo et al., 2014). Data sparsity problem is considered to be the most problematic aspect of recommendation systems together with the cold start problem. For more in-depth summary of the data sparsity problem, see Grčar et al., (2006). Gray sheep problem refers to a scenario, where the user’s opinions do not have similarities to any of the compared user groups. The consequences of the gray sheep problem are similar to cold starts, but the user may have been using the system for a long time but has not shown any interest in any of the products or content in the system, or they may be users that have “special tastes” and who neither agree nor disagree with the majority of the users For example with short-form videos, a user that watches individual videos from different categories that share no characteristics without providing any kind of feeback will be a challenging case for the algorithms as the content they have viewed is scattered.
To overcome these challenges, algorithms such as ARM (Najafabadi et al., 2017), clustering content filtering models (Salah et al., 2016), and Bayesian nets (Wei et al., 2017) have been applied. The problem with these models is that they are highly complex, require approximation of multiple restrictions, and are sensitive to the statistical properties of the data used. Due to their high cost and complexity, many of these theoretical models have not been to use in actual recommender systems (Najafabadi et al., 2019).
The biggest problem in offering recommendations based on intrinsic feature analysis is that the algorithms cannot analyze the content in a holistic way. In Kumar et al., (2019), the authors referred to Zettl (2002) and stated that “light, color, camera motion, etc. serve as crucial elements which render emotional, aesthetic, and informative effects” and from this concluded that “a new artistic work, can be appropriately evaluated and recommended on the basis of intrinsic features”. This extremely simplified view of cinematic content rules out all elements of dramaturgy. Even though light, color, and camera motion can provoke emotions in the spectator, they are hardly all (or even essential) elements for doing this. For example, a quite famous YouTube video “Charlie bit my finger - again!1” is a video of a baby biting boy’s finger. The video has extremely low production value and very little action and sound, yet it has garnered over 870 million views on YouTube based on its emotional and humoristic content. This type of content would still probably be disregarded by most sophisticated recommendation systems, especially in a cold start scenario. Finally, this simplified analysis of Zettl’s Applied Media Aesthetic disregards crucial details. First, it leaves out the elements of two- and three-dimensional space, probably because these are very difficult to analyze and detect with algorithms (but are rather novel to detect by human eye). Second, the algorithms most probably analyze each element individually, rather than as an audio-visual synthesis. This contradicts Zettl’s theory, as they summarize in their work,
“Like in any system, none of these elements or fields works in isolation. The specific effect of an aesthetic element or aesthetic field is always dependent upon the proper and harmonious functioning of all others.” (Zettl, 2002)
To summarize, the problems with algorithm-based solutions are mainly related to cold start problems and in general to the lack of data required for providing suitable recommendations. Currently the systems are not sophisticated enough to overcome these challenges with either explicit or implicit content analysis.
3. Discussion
In this chapter, we discuss the main takeaways and implications derived from this research. Finally, we outline the limitations of this research and present vision for future work related to human curation.
Human curation
In human curation, emotions work as a driving force. This provides an ‘edge’ over algorithms, as they still have difficulties in detecting emotional nuances related to humor, fear, and other primal human reactions. Where algorithms analyze and looks for specific patterns, human curation is often fueled by curiosity. Humans attempt to solve problems by asking various questions (“Is this funny?”, “Do I feel like people would enjoy this type of content based on my own, initial reaction?”, etc.). Humans also approach problems in a holistic way, trying to interconnect the analyzed content to the whole (e.g., tying the content to a larger, cultural context). Manual curation often considers the impact of the content, instead of just trying to output or publish something, and the context of this impact is often revolving around culture.
Regarding cold start problems, humans are much more accurate in evaluating the relevance of this type of content, where there is little to no metadata available on the analyzed content. The biggest disadvantage of human curation is the slow processing and analyzation of content, and the longer the analyzed content, the longer it takes for humans to analyze it as a whole. This has not stopped the big corporations in returning to human curation, though. Many streaming companies have changed or reverted to human curation, including HBO Max2 and the streaming giant Netflix3.
To characterize human curation, it is emotion-based, culture and curiosity-driven, holistic, and slow. Regarding content, human curation is especially suitable for short-form video, videos with emotional content and with references to culture(s), and for videos with low production values (lighting, editing, audio quality, etc.).
Algorithm-based recommendation systems
Algorithm-based recommendation systems have the benefit of being fast and tireless workhorse that can analyze content around the clock. The analysis is based on finding patterns, and instead of raising questions, algorithms seek for answers from the content. Algorithms are also looking for specific characteristics from the content and is based on reductionist approach. Generally, algorithms have hard time predicting the impact of the analyzed content, and they are often used with large datasets. This makes it a viable option for long-form videos such as movies, as their production values (lighting, audio and video quality, color balance, etc.) are often of higher quality, and the content itself is often complemented with sufficient metadata (genre, credits, etc.). Even though algorithms and cold start problem is a constant subject of research, a viable solution has yet to be developed, meaning that algorithms are not very efficient when the content is lacking in metadata. They also struggle with emotion-based content and are relatively bad at detecting primitive human emotions such as humor and fear.
To characterize algorithm-based recommendation, it is dependent on patterns, is data-driven, it emphasizes behavior and is fast. Regarding content, algorithm-based recommendations are suitable for long form video, content with accurate metadata, and for videos with high production value (lighting, editing, audio quality, etc.).
Combining human curation with algorithm-based recommendation systems
Combination of human curation with algorithms is not a new thing, and it is still being utilized on many platforms. One of the forerunners was Apple Music with their Beats station. Instead of using algorithms alone to create their playlists, Apple used DJ’s and celebrity musicians to create them. Jimmy Iovine, the head of the Apple Music at the time, stated that algorithms alone could not handle the “emotional task” of choosing right music for the right moment (Stratechery, 2015). Facebook and Google have admitted that their recommendation systems have played a big role in spreading misinformation and showing inappropriate content for the younger viewership (Kovach, 2019; Rosen & Lyons, 2019).
These shortcomings have created a new kind of model for curating content - a Hybrid Curation Model. In these systems, algorithms perform the initial work by gathering data from selected sources, after which the human curators take over and filter content for publication. The published content is filtered again by the algorithms and the sources are updated based on this filtering. This model’s workflow can be seen in Figure 1.
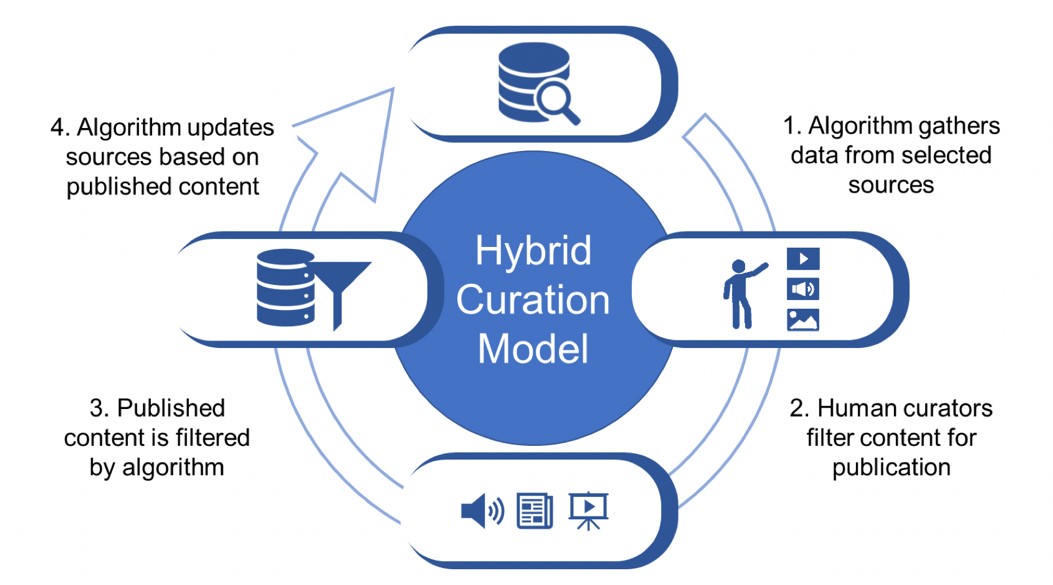
Some companies have made human curation their main selling point, and for example a company called Neverthink4 is providing its users only human curated short-form video content. The content is heavily focused on short-form meme videos, which are often lacking in metadata and suffer from cold start problems when filtered by algorithms.
Limitations and Future Work
The main limitation for this research is a philosophical one, and it relates to the question “What constitutes as relevant and good quality information?” Our personal interests and world views vary greatly, and what information is relevant to someone is obviously completely irrelevant to other. In human curation, like we already do in the art world, we can use people with expertise and/or knowledge in areas such as art, memes, and funny cat videos to filter out content that they consider to be relevant to their target audience. Algorithms and their developers have attempted to solve this problem of “quality content” by offering the viewers relevant content based on metadata. This often fully automated process may lead to some grave consequences (e.g. Fisher & Taub, 2019). In the future we will study the effectiveness of both human and algorithm-based curation, and also delve deeper into the question of “quality content” with experienced curators of web content through a series of quantitative and qualitative studies. It is worth noting, that even though this model focuses on the technical aspects of curation, one should also consider the economic and cultural implications when choosing a curation model.
4. Conclusion
In this paper, we investigated the characteristics and challenges of both human curation and algorithm-based recommendation systems. This comparison was done in general, and more specifically in the context of short-form videos. We discovered that human curation is emotion-based, culture and curiosity-driven, holistic, and slow, and is especially suitable for short-form video and emotional content. Algorithm-based recommendation systems on the other hand are dependent on patterns, are data-driven and fast. They are especially suitable for long form video, content with accurate metadata, and for videos with high production value. To combine the strong features of both curation techniques, we presented the Hybrid Curation Model that can be used to efficiently filter high quality content from large datasets regardless of content type and metadata.

