









 Portugués (pdf)
Portugués (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1.Introdução
As patentes são úteis para análise competitiva e de tendências tecnológicas (Abraham & Morita, 2001), tendo sido empregadas na gestão de projetos de pesquisa e desenvolvimento para avaliar a posição competitiva da indústria. Os pedidos de patentes estão disponíveis ao público e incluem informações úteis, tais como como o nome do requerente, data da aplicação e detalhes técnicos da invenção. Trata-se de uma fonte de informação valiosa para auxiliar a avaliação de tendências na pesquisa, uma vez que revelam as áreas de inovação que os inventores estão focados. A análise de patentes também é uma abordagem interessante para estudos prospectivos por utilizar informações textuais sobre propriedade intelectual de diversas áreas do conhecimento. O crescimento de patentes geralmente segue uma tendência semelhante que pode se assemelhar ao crescimento em forma de S (Chen, Chen & Lee, 2010). Nos estágios iniciais de uma tecnologia, o número de patentes emitidas é muito limitado. Segue-se um período de rápido crescimento quando o número de patentes depositadas e submetidas aumenta e então é atingido um patamar de maturidade. Como o processo de registro de patentes é caro e pode levar vários anos, o depósito em um escritório de registro de propriedade intelectual significa que há otimismo na contribuição econômica ou técnica do conhecimento que será protegido. Através da análise das informações registradas em uma patente, é possível acompanhar as mudanças ao longo do tempo e identificar quais as jurisdições, ou seja, os escritórios de propriedade intelectual dos países, estão realizando a maioria das atividades de patenteamento. Além disso, aprofundando a análise do conteúdo em que é requerida a proteção em termos de patente, é possível ter uma visão dos tipos de tecnologias em desenvolvimento e aquelas que estão surgindo e onde serão aplicadas. Vários índices foram introduzidos para medir a força tecnológica em função da quantidade ou qualidade da patente. Alguns exemplos incluem índices de citação de patentes e modelos de regressão (Wantanabe, Tsuji & Brown, 2001). A análise de patentes tem se mostrado valiosa no panejamento do desenvolvimento tecnológico, desde a análise da estratégia em nível nacional (Abraham & Morita, 2001) até a modelagem de tecnologias emergentes específicas (Bengisu & Nekhili, 2006). Os metadados de patentes são geralmente de acesso livre na maioria dos países e várias diretrizes foram introduzidas para aprimorar a técnica usando palavras-chave e categorização. Todavia, os registros nas bases de patentes não fornecem as palavras-chave, sendo que a categorização pode ser feita utilizando os códigos de classificação de patentes. Há duas classificações de patentes usadas em âmbito internacional: a Classificação Internacional de Patentes (IPC – The International Patent Classification), disponível no sítio da World Intellectual Property Organization (2022) e a Classificação de Cooperação de Patentes (CPC – The Cooperative Patent Classification), que pode ser consultada no European Patent Office (2022). A classificação de um documento de patente influencia todo o ciclo de vida deste documento. A cada nova versão da IPC e da CPC, novos símbolos são criados, mostrando a tendência do desenvolvimento tecnológico nas áreas afins. Em suma, os bancos de patente podem ser utilizados para: sondar as atuais tendências por meio do conhecimento do estado da técnica e histórico da tecnologia; visualizar os inventos mais recentes aplicados nas mais diversas áreas do desenvolvimento de pesquisas; prospectar uma determinada tecnologia; levantar novos temas para trabalhos acadêmicos; identificar o nível de exploração de uma tecnologia; buscar novas maneiras técnicas para a solução de problemáticas existentes na sua área de atuação; dentre outras utilizações possíveis. A bibliometria é definida por Norton (2010) como a medida de textos e informações, tornando-se uma ferramenta padrão para a gestão da pesquisa nas últimas décadas. Todas as compilações significativas de indicadores científicos dependem fortemente da publicação e estatísticas de citação e outras técnicas bibliométricas mais sofisticadas. Os métodos bibliométricos têm sido usados para rastrear as citações de periódicos acadêmicos. Entretanto, hoje a bibliometria pode ser usada para entender o passado e até mesmo potencialmente para estimar o futuro (Morris et al, 2022). A bibliometria ajuda a explorar, organizar e analisar grandes quantidades de dados históricos, ajudando os pesquisadores a identificar padrões ocultos que podem ajudar os pesquisadores no processo de tomada de decisão. Algumas técnicas analíticas têm sido usualmente utilizadas em bibliometria, tais como autores, afiliações, mapas conceituais, análise de agrupamento e fator, análise de citação e cocitação para mencionar algumas delas. Na análise de patentes, existem diversos trabalhos que empregaram a análise bibliométrica. Entre os diversos exemplos podemos mencionar: a construção de um modelo de análise de patentes para orientar a transferência de tecnologia (Liu & Yu, 2017); o desenvolvimento de um modelo de análise de patentes para promover o desdobramento da tecnologia de grafeno na indústria de TIC (Xi & Xiang, 2020); a indicação de previsões para três áreas tecnológicas emergentes integrando a análise de patentes com ferramentas de prospecção (Daim et al, 2006); o mapeamento tecnológico utilizando análise de patentes e de redes sociais para identificar especialistas e tecnologias existentes ou em desenvolvimento (Daim et al, 2014); em uma revisão de literatura foi verificado o potencial industrial dos biocatalisadores, particularmente das lípases (Almeida et al, 2021); a introdução e a previsão de biossensores para uso em aplicações da área de saúde com o emprego de biossensores (Sheikh & Sheikh, 2017), uma meta-análise sobre o desenvolvimento de pesquisas sobre análise de patentes no período de 1980 a 2003 (Lai et al, 2007); o fornecimento de uma abordagem sistemática para a análise integrada de tendências que levam em conta a análise de patentes empregando mineração de textos (Wu et al, 2011). Contudo, não foram identificados estudos utilizando o pacote R-Bibliometrix na análise qualitativa de informações registradas em patentes. Este artigo se insere na temática Análise Qualitativa com Apoio de Software Específico, visando explorar as potencialidades do pacote R-Bibliometrix, para através da análise qualitativa de patentes, extrair informações relevantes para a sua exploração. Portanto, a questão de pesquisa deste artigo é: como gerar subsídios para a interpretação qualitativa de patentes utilizando o apoio da estrutura conceitual do pacote R-Bibliometrix?
2.Metodologia
A metodologia deste trabalho compreende a coleta de dados, detalhando como a pesquisa foi realizada, e a análise dos dados, que apresenta uma síntese do pacote R-Bibliometrix e da conversão dos dados para serem importados e analisados.
2.1 Coleta de dados
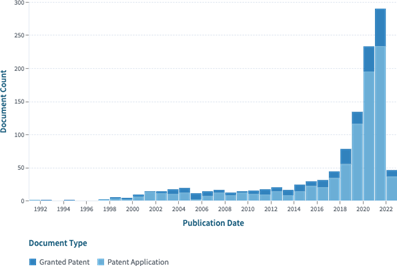
A pesquisa de patentes foi realizada na base Lens (2022), que é de acesso livre e indexa documentos científicos e patentes. A base tem uma atualização semanal da indexação de patentes. Atualmente, a Lens abrange 42.175.357 de patentes concedidas, 63.542.254 de patentes submetidas; mais de 100 escritórios de registro de propriedade intelectual, incluindo China, Estados Unidos, Japão, Alemanha, Escritório Europeu (European Patent Office), Escritório da Organização Mundial de Propriedade Intelectual (World Intellectual Property Organization – WIPO), além, de Brasil, Portugal e Espanha. A base Lens também indexa mais de 200 milhões de registros acadêmicos, compilados e harmonizados das bases Microsoft Academic, PubMed e Crossref. Os documentos são enriquecidos com informações de acesso aberto via Unpaywall (Piwowar et al, 2018), texto completo CORE (2022) e links de identificação de autores pelo ORCID (2022). O acesso livre e o conceito central da base Lens, focado em ciência aberta, foram considerados como fundamentais, para que pesquisadores, sem acesso às bases pagas com informações sobre patentes e artigos científicos possam ter acesso a estas informações e conduzir suas pesquisas. Para exemplificar as possibilidades de análise utilizando o pacote R-Bibliometrix, foi realizada uma pesquisa de patentes submetidas (Patent Application) e concedidas (Granted Patent) sobre o tema de inteligência artificial. Para a maior abrangência, foi utilizada a seguinte expressão de busca: “artificial intelligence” OR “machine learning” OR “deep learning”. Foram delimitados os campos de Title, Abstract e Claims, resultando em 233.048 documentos, abrangendo o período de 1973 a 2022. Em seguida foi aplicado um recorte para identificar as patentes que continham a palavra Education. Mantendo as condições anteriores e inserindo um operador booleano AND, obteve-se a seguinte expressão de busca: ((title:("artificial intelligence") OR abstract:("artificial intelligence") OR claim: ("artificial intelligence")) OR ("artificial intelligence")) AND (title: (education) OR abstract: (education) OR claim: (education)). A pesquisa resultou em 1.131 patentes , sendo 264 concedidas e 867 submetidas, compreendendo o período de 1991 a 2022. A Figura 1 apresenta a evolução das patentes. Observa-se que o pico ocorreu em 2021 com 233 patentes submetidas e 57 concedidas.
2.2 Análise dos dados
Neste trabalho, foi utilizado o pacote R Bibliometrix (Aria & Cuccurullo, 2017, 2021), que é um software de código aberto para automatizar as etapas de análise e visualização de dados quantitativos e qualitativos. Depois de converter e enviar dados bibliográficos em R, o Bibliometrix possibilita uma análise descritiva do tema pesquisado. A Tabela 1 apresenta as bases que o pacote R Bibliometrix permite a importação dos metadados e os respectivos formatos.

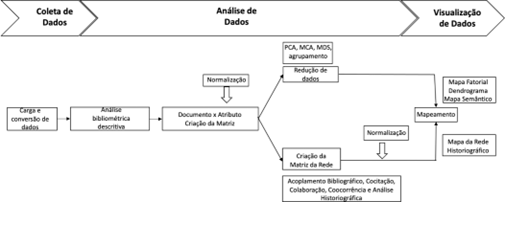
Figura 2 apresenta o processo de coleta, análise e visualização dos dados. É importante ressaltar que o pacote R-Bibliometrix apoia as principais etapas do fluxo de trabalho recomendado para o mapeamento científico. O fluxo tem início na coleta de dados nas bases e nos formatos mencionados na Tabela 1. Em seguida, os dados passam pelas etapas de criação das matrizes de documento e atributo para viabilizar o mapeamento semântico.
Apesar de fazer a importação dos dados da Base Lens, o pacote R-Bibliometrix não permite a análise dos dados de patentes, porque os identificadores são diferentes. Assim, foi necessário fazer uma substituição dos identificadores de campos adequando ao formato dos artigos científicos, conforme mostrado na Tabela 2. É importante observar que alguns resumos podem estar no idioma de origem. No exemplo, foram identificados resumos em Coreano, que foram traduzidos para o inglês. No identificador dos autores (Authors) é possível selecionar os inventores (Inventors), os proprietários (Owners) ou os requerentes (Applicants) das patentes. No exemplo, foram selecionados os requerentes das patentes.

Outro aspecto a destacar é que as patentes não possuem palavras-chave. Por este motivo, foram aproveitados os indicadores de palavras-chave e de indexação para incluir os códigos IPC e CPC. Estes códigos e os seguintes símbolos combinados: a seção; a classe; a subclasse; o grupo principal e o subgrupo. As seções são o nível mais alto da hierarquia da classificação e são divididas em oito. Cada uma delas é simbolizada por uma letra maiúscula de A até H, seguidas pelo título da Seção, que é uma indicação ampla do seu conteúdo: A - Necessidades Humanas; B - Operações de Processamento, Transporte; C – Química, Metalurgia; D – Têxteis, Papel; E - Construções Fixas; F - Engenharia Mecânica, Iluminação, Aquecimento, Armas, Explosão; G – Física; e, H – Eletricidade. O CPC possui uma seção adicional denominada Y - Tecnologias transversais emergentes. O segundo nível hierárquico são as chamadas Classes, que possuem dois dígitos numéricos. O terceiro nível são as Subclasses, que são codificadas por um dígito alfabético, cujo título indica de forma um pouco mais precisa o seu conteúdo. No quarto nível estão os Grupos, que se subdividem entre Grupos principais e Subgrupos. Os Grupos Principais são representados por até dois dígitos numéricos seguido de uma barra oblíqua e o número 00. Além disso, cada Grupo Principal possui um título que define o conteúdo dentro do escopo da sua subclasse para facilitar a pesquisa de documentos com assuntos mais específicos. Em algumas Subclasses existe o Grupo 99/00, que inclui matéria não abrangida pelos demais Grupos de uma Subclasse. Os Subgrupos são as subdivisões dos Grupos Principais e são representados por pelo menos dois dígitos numéricos diferentes de 00. Por exemplo, o código G06N 20/20 pode ser interpretado como: G – Física; G06 – Cômputo; Cálculo ou Contagem; G06N – Disposições de computação baseadas em modelos computacionais específicos; G06N 20/00 – Aprendizado de Máquina; G06N 20/20 – Aprendizagem de conjunto. Por fim, é importante ressaltar que, como os dados exportados pela Base Lens não possuem todos os metadados, algumas das funcionalidades do pacote R-Bibliometrix não são executadas. Uma limitação está na ausência das referências citadas, o que impede a compreensão da estrutura intelectual. Contudo, é possível explorar a estrutura conceitual baseando-se na coocorrência de palavras e para tal o software oferece as seguintes opções: i) rede de coocorrência de palavras-chave dos autores, palavras-chave plus, título (monograma, bigrama e trigrama) e resumo (monograma, bigrama e trigrama), com a visualização dos mapas, das tabelas de dados das redes e dos gráficos de grau; ii) mapa temático de palavras-chave dos autores, palavras-chave plus, título (monograma, bigrama e trigrama) e resumo (monograma, bigrama e trigrama), com a visualização dos mapas, das redes e das tabelas de dados e dos agrupamentos; iii) evolução temática de palavras-chave dos autores, palavras-chave plus, título (monograma, bigrama e trigrama) e resumo (monograma, bigrama e trigrama), com a visualização dos mapas temáticos, das redes e das tabelas de dados e dos agrupamentos, que podem ser divididos por períodos de tempo; e, iv) análise fatorial que utiliza os métodos de análise de correspondência, de análise de correspondência múltipla e de dimensionamento multidimensional para palavras-chave dos autores, palavras-chave plus, título (monograma, bigrama e trigrama) e resumo (monograma, bigrama e trigrama), com a visualização do mapa de palavras, do dendograma de tópicos, dos artigos que mais contribuíram, dos artigos mais citados, dos agrupamentos por palavras, dos artigos por agrupamentos.
3.Análise qualitativa
A análise de um corpus textual corresponde ao material escrito, sendo possível analisar textos, entrevistas, documentos, redações etc. Com o emprego de softwares que fazem a análise de dados qualitativos, é possível realizar análises lexicográficas, que identificam a quantidade de palavras, a frequência média e o número palavras com frequência um. Análises de especificidades e fatorial de correspondência são especialmente indicadas para descrever um grande volume de dados, associando textos com modalidades de uma única variável de caracterização, ou seja, possibilita a comparação (contraste) da produção textual destas modalidades. Outro método é a classificação hierárquica descendente (CHD), que classifica os segmentos de texto em função dos seus respectivos vocabulários, formando um esquema hierárquico de classes, e o conjunto deles é repartido em função da presença ou ausência das formas reduzidas. Possui também como recurso a análise de similitude, baseada na teoria dos grafos, permitindo identificar as coocorrências entre as palavras e seu resultado traz indicações da conexão entre as palavras, auxiliando na identificação da estrutura do conteúdo de um corpus textual. Outro recurso que contribui para a visualização de um corpus textual é a nuvem de palavras, que agrupa e organiza as palavras em função da sua frequência. As palavras com maior frequência são as maiores e são colocadas ao centro do gráfico, as menores representam frequências inferiores (Camargo & Justo, 2018). A seguir serão apresentadas algumas possibilidades de interpretação de dados qualitativos registrados em patentes concedidas e submetidas. No menu Documents, é possível identificar e exportar os dados em formato CSV ou a imagem do gráfico dos seguintes tipos de análises: palavras mais frequentes; nuvem de palavras; árvore do mapa de palavras; dinâmica das palavras e tópicos de tendências. Todos estes tipos permitem extrair as palavras do título (monograma, digrama e trigrama), do resumo (monograma, digrama e trigrama), das palavras-chave dos autores (código CPC) e das palavras-chave plus (código IPC). A Tabela 3 mostra os 10 digramas mais frequentes extraídos dos resumos das patentes.

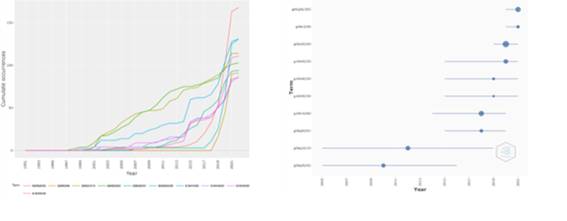
Outra possibilidade é a análise da dinâmica das tecnologias a partir dos códigos IPC. A Figura 3 apresenta a evolução da tecnologia ao longo do tempo, cumulativamente, e os tópicos de tendências. O código G06N 20/00, que corresponde ao aprendizado de máquina, é o destaque na evolução das tecnologias e teve o maior crescimento em 2020.
A estrutura conceitual se baseia na coocorrência de palavras e oferece as seguintes opções: rede de coocorrência; mapa temático; evolução temática e análise fatorial, que utiliza os métodos de análise de correspondência, de correspondência múltipla e de dimensionamento multidimensional. As palavras podem ser extraídas das palavras-chave dos autores (código CPC), das palavras-chave plus (código IPC), do título (monograma, digrama e trigrama), do resumo (monograma, digrama e trigrama). A Figura 4 apresenta um mapa temático das rotas conceituais que foram extraídas dos resumos das patentes concedidas e submetidas.
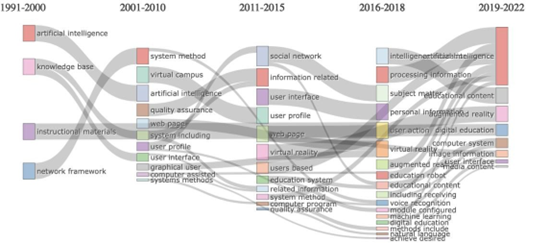
Figura 4 Mapa temático das rotas conceituais extraídas dos resumos das patentes submetidas e concedidas.
O mapa temático pode ser obtido utilizando os códigos IPC ou CPC. Neste caso, pode-se visualizar as rotas tecnológicas interpretando os códigos. A estrutura conceitual da rota tecnológica pode ser interpretada em sua macroestrutura, considerando o código até o nível de Subclasse ou Grupo Principal, ou em sua microestrutura, como apresentado na Figura 5.
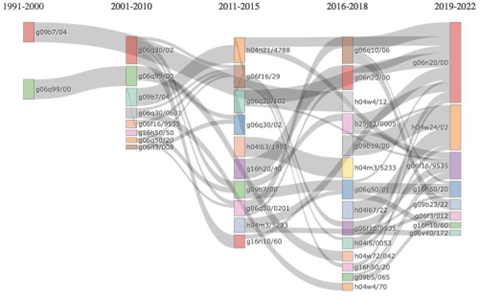
Em relação à análise fatorial, o pacote R-Bibliometrix permite obter o mapa de palavras, o dendrograma de tópicos e as palavras por comunidade. A Tabela 4 apresenta as palavras agrupadas por comunidades utilizando a análise fatorial com o método do dimensionamento multidimensional.

Enfim, o pacote R-Bibliometrix permite outras possibilidades como analisar a estrutura social, que oferece as seguintes opções: rede colaboração de autores, instituições e países, com a visualização dos grafos, das tabelas de dados e dos gráficos de grau; e mapa de colaboração de países, com a visualização do grafo e da tabela de dados.
4.Considerações Finais
O objetivo deste artigo foi a apresentação de uma abordagem para gerar subsídios para a interpretação qualitativa de patentes utilizando a funcionalidade de estrutura conceitual do pacote R-Bibliometrix. A coleta de dados realizada na base Lens, que é de acesso livre, mostrou que é possível obter informações valiosas para análises com foco em tecnologia e inovação. A base permite análises preliminares de panoramas tecnológicos com a utilização dos recursos disponíveis para a visualização. Apesar do pacote R-Bibliometrix não permitir a análise de conteúdo de patentes, é possível fazer uma conversão dos identificadores dos metadados das patentes para o formato adequado para a importação seguindo o padrão dos identificadores dos artigos. Há uma limitação, porque nem todos os dados são exportados pela base, como é o caso dos documentos citados pelas patentes. Assim, não é possível explorar a estrutura intelectual das informações registradas nas patentes. A base Lens permite identificar uma família de patentes, que é um grupo de invenções que estão relacionadas a um documento específico. Nesse sentido, é possível aprofundar a interpretação de uma tecnologia ou inovação através da análise qualitativa de todos os documentos de patentes de uma família. Como perspectiva futura, sugere-se o aprofundamento do entendimento das funcionalidades do pacote R-Bibiometrix, particularmente quanto à interpretação dos identificadores que são exportados pela base Lens para uma patente e o seu correspondente na exportação de artigos. Isso possibilitará novas análises dos dados qualitativos registrados nas patentes.