A.N. Campana1, M.C. Tavares2, D. Silva3
A modelagem de Equações Estruturais é uma técnica estatística multivariada que permite avaliar, simultaneamente, relações entre múltiplos construtos. O objetivo deste artigo é apresentar os princípios desta abordagem, seus elementos, características, etapas de execução e limitações. Por fim, apresentamos perspectivas futuras e possibilidades de uso da técnica nas pesquisas em Educação Física.
Palavras-chave: modelos de equações estruturais, análise de dados multivariados, educação física
Structural Equations Modeling: Presentation of a multivariate statistical approach to research in Physical Education
Structural equation modeling is a multivariate statistical technique for assessing, simultaneously, relationships between multiple constructs. The aim of this paper is to present the principles of this approach, its elements, its characteristics, its stages of implementation and its limitations. Finally, we present future perspectives and possibilities of applying this statistical technique in studies of Physical Education.
Key words: structural equation modeling; multivariate data analysis, physical education
]]>
Na Educação Física, por muitas vezes, debruçamo-nos no entendimento de atitudes de nossos alunos, atletas, ou mesmo de nosso publico que consome esportes. Temas como motivação, ansiedade corporal, satisfação corporal, violência esportiva, desistência da prática esportiva, relações entre gêneros, estigmatização são abordados pelos pesquisadores na área de Educação Física. Como são atitudes humanas, é impossível medi-las diretamente. De acordo com Hair Jr., Anderson, Tatham e Black (2005), não sendo possível a mensuração direta, os construtos devem ser medidos através de indicadores também denominados variáveis manifestas ou valores observados. Estes indicadores são componentes das escalas de atitude, e uma análise adequada destes dados pode nos oferecer respostas sólidas para nossas pesquisas.
A Modelagem de Equações Estruturais (Structural Equation Modeling - SEM) é uma técnica estatística robusta, que pertence à segunda geração de técnicas estatísticas multivariadas para análise de dados. A SEM permite aos pesquisadores responderem a uma série de perguntas inter-relacionadas de uma forma simples, sistemática e abrangente. Consegue este intento ao modelar simultaneamente as relações entre múltiplos construtos dependentes e independentes (Gefen, Straub, & Boudreau, 2000).
A área da educação física e esportes ainda não tem tradição no uso dessa técnica estatística. Os trabalhos pioneiros de Fernandes e Vasconcelos-Raposo (2005) e Fernandes, Vasconcelos-Raposo, Lázaro e Dosil (2004) apontam para a validade do uso da SEM na educação física e desporto. Os autores debruçaram-se sobre o entendimento da motivação intrínseca na prática esportiva, elaborando modelos preditivos. Entretanto, mais temas podem ser explorados e mesmo, outros modelos explicativos para a motivação intrínseca podem ser elaborados.
Reconhecendo esta lacuna metodológica em nossa área, o propósito deste artigo teórico é descrever os princípios da SEM, seus elementos, características, etapas de execução e limitações. Nosso intuito com este trabalho é de fornecer ao pesquisador brasileiro, em especial da área da Educação física, os conhecimentos básicos para a implementação da SEM em suas investigações futuras.
Definição e elementos principais
Segundo Klem (2006) a SEM, da forma que é conhecida hoje, se estruturou no ano de 1970, quando o estatístico Karl Jöreskog teve a ideia de combinar a econometria e a psicometria num único modelo. Esta é a ideia original, que formou a base da SEM - combinação de análise fatorial e análise de caminhos (path analysis). É uma técnica muito mais confirmatória do que exploratória, o pesquisador a usará para determinar se dado modelo teórico é válido, perante os dados reais observados (Hox & Bechger, 1998; Rigdon, 2009). Pode receber outros nomes como LISREL em referência ao conhecido programa estatístico de mesmo nome análise de estruturas de covariância, modelagem causal, análise causal, modelagem de equações simultâneas (Ullman, 2001).
Os modelos SEM, num sentido amplo, representam a interpretação de uma série de relações hipotéticas de causa-efeito entre variáveis para uma composição de hipóteses, que considera os padrões de dependência estatística. Os relacionamentos dentro desta composição, são descritos pela magnitude do efeito (direto ou indireto) que as variáveis independentes (observada ou latentes) têm nas variáveis dependentes (observada ou latentes) (Hershberger, Marcoulides, & Parramore, 2003).
A variável independente ou exógena é aquela que age apenas preditora ou causadora de um efeito em outra variável/construto no modelo teórico. É determinada fora do modelo e suas causas não são nele especificadas.
]]> A variável dependente ou endógena é aquela que resulta de pelo menos uma relação causal. O pesquisador conseguirá distinguir quais variáveis independentes prevêem cada variável dependente apoiando-se na teoria e também em suas próprias experiências prévias (Hair Jr. et al., 2005; Hershberger et al., 2003; Klem, 2006)O construto ou variável latente é aquela variável hipotética ou teórica que não pode ser diretamente medida como, por exemplo, qualidade, beleza, satisfação - mas que pode ser representada por outros indicadores, constituídos pelos itens das escalas ou pela observação do pesquisador, que em conjunto permitirão que ele obtenha uma medida razoavelmente precisa da atitude (Hair Jr. et al., 2005).
A variável observada, por sua vez, é o valor observado que é usado para medir a variável latente. São usadas como os indicadores da atitude que se quer medir. É recomendado que o pesquisador use múltiplos indicadores para cada variável latente, de forma a obter um entendimento mais completo e confiável do construto. Nessa direção, existe a recomendação geral de que pelo menos três variáveis observadas devem estar relacionadas a cada variável latente (Garver & Mentzer, 1999; Geffen et al., 2000; Hair Jr et al., 2005; Hershberger et al., 2003).
A SEM é uma técnica apropriada e mais eficiente para a análise uma série de equações múltiplas, sendo caracterizada por dois componentes básicos: o modelo estrutural e o modelo de mensuração (Hair Jr. et al., 2005).
O modelo estrutural relaciona as variáveis dependentes e independentes. É nele que se sumarizam as relações causais entre as variáveis latentes. O modelo de mensuração especifica os indicadores de cada variável latente e permite avaliar a confiabilidade de cada construto ao estimar as relações causais que nele ocorrem (Geffen et al., 2000; Hershberger et al., 2003).
Essa análise combinada do modelo estrutural e de mensuração permite medir os erros das variáveis observadas como partes integradas do modelo e a combina a análise fatorial com a hipótese testada, numa única operação (Geffen et al., 2000).
Os dados de pesquisa
A SEM tem três suposições relativas aos dados da pesquisa: (1) observações independentes; (2) amostragem aleatória; e, (3) linearidade de todas as relações.
As observações independentes são obtidas quando diversos sujeitos respondem apenas uma vez ao instrumento de pesquisa ou são observados apenas uma vez pelo pesquisador são dados não-pareados.
]]> A amostragem aleatória pode ser obtida quando o pesquisador forma sua amostra de pesquisa, tendo oferecido à população em geral, chances iguais de participar da amostra por sorteio, por estratificação ou por um sistema de escolhas.A linearidade implica em prever valores que recaem numa linha reta, que tem uma mudança com unidade constante da variável dependente em relação a uma mudança com unidade constante da variável independente.
Os métodos mais usados de estimação da SEM exigem a comprovação da normalidade multivariada. Então, além destas três suposições, a normalidade multivariada dos dados também deve ser garantida. Isso significa que deve ser garantido que as distribuições univariadas são normais, que a distribuição conjunta de qualquer par de variáveis tem normalidade bivariada e que todos os gráficos bivariados são lineares e homocedásticos, da mesma forma que deve ser evitada uma forte assimetria nos dados (Hair Jr et al., 2005, Kline, 1998, Levin, 1987).
O pesquisador pode utilizar o teste de Mardia, baseado em testes de assimetria e curtose, para verificar a normalidade multivariada (Mardia, 1970). A análise dos dados por este teste é o mais adequado, sendo superior a outras alternativas, como por exemplo, a generalização do teste univariado de normalidade de Shapiro-Wilks, por haver maior possibilidade de cometer um erro tipo I na análise dos dados (Cantelmo & Ferreira, 2007). Entretanto, é válido caracterizar a distribuição dos dados amostrais em termos de localização (skewness) e variabilidade (kurtosis) e os testes univariados de normalidade podem ser usados para este fim (Howell, 1999).
Quanto à amostra, há uma variação em relação à técnica de estimação. O método de Estimação de Máxima Verossimilhança permite que se usem amostras menores, entre 100 e 200. Já o método de Estimação Assintoticamente Independente de Distribuição exige amostras maiores, para compensar a falta de normalidade multivariada dos dados. Neste caso, pode-se lançar mão da regra que determina a razão entre sujeitos e variáveis, que recomenda usar a razão 10:1, sendo ideal 15:1 ou 20:1 (Hair Jr et al., 2005; Klem, 2006; Schumacker & Lomax, 2004).
Terminologia da SEM
O modelo de uma equação estrutural, conforme popularizada por Jöreskog criador do LISREL tem terminologia específica para o modelo estrutural e para o modelo de medida.
Na terminologia LISREL, o modelo estrutural é composto pela variável latente endógena, chamada de η (Eta); pela variável latente exógena, chamada de ξ (Ksi); pelos caminhos que conectam η a ξ, chamado de coeficiente γ (Gama); pelos caminhos que conectam η a outra η, chamados de β (beta) matriz de correlação entre as variáveis exógenas latente σ, chamada de Φ (Phi); a matriz de correlação entre erros das variáveis latentes endógenas, chamado de Ψ (Psi) e o erro de mensuração, chamado de ζ (Zeta) (Geffen et al. 2000; Klem, 2006).
Já o modelo de mensuração consiste em variáveis observadas que estão associadas aos construtos exógenos (X) e que estão associadas aos construtos endógenos (Y); em caminhos entre as variáveis observadas e o construto exógeno aos quais estão associadas, chamado de λX (Lambda X); em caminhos entre as variáveis observadas e o construto endógeno ao qual estão associadas, chamado de λY (Lambda Y) e o erro de variância associado com cada variável observada, indicando que a variável não está representando a variável latente exógena que está associado, chamado de Θδ (Theta Delta) (Geffen et al., 2000; Klem, 2006) (ver tabela 1).
]]>Tabela 1. Variáveis e Parâmetros na SEM
| Notação do Lisrel | Variáveis |
| η | Variável dependente, endógena: latente |
| ξ | Variável independente, exógena: latente |
| Ψ | ]]> Indicador de variável dependente: observada |
| Ξ | Indicador de variável independente: observada |
| ε | Erro na variável dependente observada |
| δ | Erro na variável independente observada |
| ζ | Erro de mensuração de h |
|
| ]]> Parâmetros |
| λY | Coeficientes que relacionam variáveis dependentes latentes a variáveis dependentes observadas |
| λX | Coeficientes que relacionam variáveis independentes latentes a variáveis independentes observadas |
| β | Coeficientes que relacionam as variáveis dependentes latentes entre si |
| Γ | Coeficientes que relacionam as variáveis independentes latentes a variáveis dependentes latentes |
| Φ | ]]> Variâncias e covariâncias entre variáveis independentes latentes |
| Ψ | Variâncias e covariâncias entre os erros |
| Θε | Variâncias e covariâncias entre erros na variáveis dependentes observadas |
| Θδ | Variâncias e covariâncias entre erros na variáveis independentes observadas |
]]>Nota: Adaptado de Klem (2006)
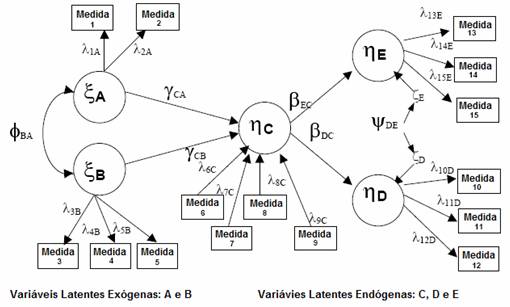
Na pesquisa, é comum encontrar a representação pictórica das relações entre as variáveis latentes e observadas (figura 1).
Figura 1. Representação gráfica de um modelo de equação estrutural
Nota: Adaptado deGefen et al. (2000)
]]>As setas indicam o tipo de relação entre as variáveis latentes e observadas. Se a seta for unidirecional ela indicará uma relação recursiva entre as variáveis. Se a seta for bidirecional, ela indicará uma relação não recursiva entre as variáveis, ou seja, elas têm uma relação mútua e recíproca. Cada construto no par estabelece uma relação com outro construto. A linha curvada, bidireccional, existente entre duas variáveis latentes representa a correlação e a covariância destas variáveis no modelo (Garver & Mentzer, 1999; Hair Jr et al., 2005; Hershberger et al., 2003). No modelo, as elipses/círculos sempre representarão as variáveis latentes e os quadrados/retângulos representarão as variáveis observadas (Hershberger et al., 2003).
Nem sempre o pesquisador se deparará com fenômenos que podem ser explicados apenas pela relação entre variáveis observada e latente. Neste tipo de modelo, variável latente é determinada diretamente pelos indicadores: avalia-se uma série de aspectos da variável latente, e os resultados dos itens desta avaliação permitirão que o pesquisador confirme sua teoria para aquele fenômeno. Este modelo é chamado de modelo de medida de primeira ordem (Garver & Mentzer, 1999).
Em outros casos, o pesquisador se deparará com um fenômeno mais complexo, que exige um maior grau de abstração e sua explicação exigirá a reunião de uma série de variáveis latentes para explicá-lo. Nesta situação, os indicadores representarão as variáveis latentes de primeira ordem. Estas, por sua vez, agem como múltiplos indicadores que são causados pela variável latente de segunda ordem. Este tipo de modelo é chamado de modelo de medida de segunda ordem (Garver & Mentzer, 1999).
Estágios na Modelagem de Equações Estruturais
Com o propósito de garantir que ambos os modelos estrutural e de mensuração estejam especificados de forma correta e que os resultados sejam válidos, uma série de passos ou estágios sistemáticos devem ser seguidos. Para Schumacker e Lomax (2004) são cinco os passos fundamentais: (1) especificação do modelo, (2) identificação do modelo, (3) estimação do modelo, (4) testagem do modelo e (5) modificação do modelo. Hair Jr et al. (2005) distinguem sete estágios que todo pesquisador deverá passar ao trabalhar com a SEM: (1) desenvolvimento de um modelo teórico; (2) construção de um diagrama de caminhos de relações causais; (3) conversão do diagrama de caminhos construído anteriormente em um conjunto de modelos estrutural e de mensuração; (4) escolha do tipo de matriz dos dados e estimação do modelo proposto; (5) avaliação da identificação do modelo estrutural; (6) avaliação dos critérios de qualidade do ajuste e (7) interpretação e modificação do modelo. São estes sete estágios que descreveremos a seguir.
No primeiro estágio, desenvolvimento de um modelo teórico, o que deve guiar o pesquisador é a premissa de que a modelagem de equações estruturais é baseada em relações causais, onde a mudança numa variável inevitavelmente acarretará mudança em outra variável. Aqui, vale salientar que nenhum método estatístico, por mais robusto que seja, é capaz de transformar dados transversais (correlacionais) em dados longitudinais (causais). A causalidade da qual se fala na SEM implica, na verdade, em fortes e multivariadas relações causais. Na interpretação dos dados transversais e do modelo SEM, deve-se trabalhar com a ideia de preditor x consequência e não exatamente, causa x efeito, como nas pesquisas longitudinais (Mueler, 1997).
O pesquisador deverá ter um conhecimento profundo do tema para determinar quais variáveis são dependentes e independentes. Esse cuidado, assegurará que sejam respeitados os quatro critérios para causalidade estabelecida pela SEM: (1) associação suficiente entre duas variáveis; (2) evidências anteriores de causa x efeito; (3) falta de variáveis causais alternativas e (4) uma base teórica para a relação. Hair Jr et al. (2005) reconhecem que nem sempre é possível atender a todos os critérios, mas que frente a uma sólida perspectiva teórica, é possível fazer afirmações de causalidade. Além de possibilitar reconhecer as relações entre as variáveis para atender à causalidade, o conhecimento teórico aprofundado do tema permite que o pesquisador evite erros de especificação. O erro de especificação ocorre quando se omite uma variável relevante ao modelo, o que causa uma avaliação errônea da importância das demais variáveis e por conseguinte, falta de qualidade no ajuste do modelo proposto.
No segundo estágio, construção de um diagrama de caminhos de relações causais, o pesquisador deve determinar, esquematicamente, as relações causais (preditivas) e associativas (correlações) entre as variáveis dependentes e independentes. Deve-se usar setas retilíneas para determinar as relações causais e setas curvilíneas para determinar associações entre os construtos, e em alguns casos, até mesmo entre os indicadores (Hair Jr et al., 2005) (ver figura 2).
]]> 
Figura 2. Exemplo de um diagrama de caminhos
Nota: Adaptado de Hair Jr et al. (2005)
No terceiro estágio, conversão do diagrama de caminhos construído anteriormente em um conjunto de modelos estrutural e de mensuração, o pesquisador deverá definir o modelo de uma forma mais formal, através de equações que definem o modelo estrutural, o modelo de mensuração e um conjunto de matrizes indicando correlações teorizadas entre construtos e variáveis.
Transformar um diagrama de caminhos em equações que formaram o modelo estrutural é uma passagem direta, que implica, entretanto, no reconhecimento dos construtos endógenos e exógenos. Os construtos endógenos formam as variáveis dependentes na equação e os construtos exógenos formam as variáveis independentes (ver figura 3). Para definir o modelo de mensuração, o pesquisador deverá especificar quais variáveis definem cada construto. As variáveis observadas que são os itens respondidos pela amostra nos questionários são os indicadores e os construtos latentes são os fatores. Deve-se ter o cuidado em determinar o número de indicadores mais que um, por volta de 3, no máximo 5 ou 7 e em determinar a confiabilidade dos indicadores. O pesquisador, na análise confirmará esta associação que ele determinou no modelo de mensuração. Finalizando os requisitos do terceiro estágio, deve-se verificar a existência de correlações entre construtos endógenos o que é comum, representado uma influência compartilhada sobre as variáveis ou entre os exógenos que tem menos aplicações apropriadas e pode acarretar má interpretação das equações estruturais (Hair Jr et al., 2005).

Figura 3. Exemplo da transformação de um diagrama de caminhos em equação estrutural
]]>Nota: Adaptado de Hair Jr et al. (2005) b é o coeficiente estrutural de cada efeito teorizado e e é o erro que é formado pelos erros de especificação e pelos erros aleatórios de mensuração.
No quarto estágio, escolha do tipo de matriz dos dados e estimação do modelo proposto, o pesquisador deverá atentar para a entrada dos dados de forma apropriada e para a seleção dos procedimentos de estimação.
Quanto à escolha do tipo de matriz dos dados, na SEM, a entrada dos dados de todos os indicadores do modelo será feita por uma matriz de variância-covariância ou de correlação. Originalmente, a SEM foi formulada para trabalhar com matrizes de variância-covariância. A vantagem do uso deste tipo de matriz é a possibilidade de comparar diferentes amostras e populações, na medida que ela fornece comparações válidas para esta finalidade. Na matriz de correlação, esta possibilidade de comparações não ocorre. O uso de correlações é adequado quando o objetivo da pesquisa é apenas compreender o padrão de relações entre os construtos, mas não aplicar a variância total de um construto (Hair Jr et al., 2005, p. 484).
Tendo isto em vista, é recomendado que na testagem de uma teoria, seja aplicada a matriz de variância-covariância, por esta ser a forma apropriada de validar relações causais. É importante que os dados supram as três suposições da SEM, já anteriormente apresentadas: observações independentes, amostragem aleatória e linearidade das relações. É nesse estágio que o pesquisador também determina como tratará os dados perdidos. A opção listwise que elimina todos os dados daquela observação independente no qual um ou mais dados foram perdidos pode acarretar uma perda amostral, entretanto, o pesquisador se precavê de causar irregularidades na matriz de dados. Este é justamente o risco associado à abordagem pairwise, que pode induzir a problemas no processo de estimação. Estas duas opções podem ser viáveis quando não ocorre uma perda amostra muito grande. Outra opção que pode ser usada em perdas amostrais maiores, é a abordagem Expectation-Maximization (EM), uma alternativa de tratamentos de dados perdidos oferecida pelo programa Statistical Package for Social Science (SPSS). A vantagem desta abordagem é que ela induz a um menor viés nos modelos estimados (Hair Jr et al., 2005).
Quanto a estimação do modelo proposto, o pesquisador deverá escolher entre as técnicas existentes, a que mais se adequa aos seus dados. As técnicas mais comuns são (Hair Jr et al., 2005; Schumacker & Lomax, 2004; Thompson, 2006):
]]> (i) Mínimos quadrado ordinários (OLS): que não têm hipóteses de distribuição, nem testes estatísticos associados. Provêm estimativas coerentes e dependentes da escala, isto é, mudanças na variável observada da escala acarretam soluções diferentes ou um conjunto de estimativas diferentes;(ii) Máxima Verossimilhança (MLE): na qual se requer que os dados tenham distribuição normal multivariada e que a amostra seja em torno de 100 a 200 casos. A amostra não deve ultrapassar de 400 a 500 respondentes, pois acima deste tamanho amostral a técnica se torna muito sensível, e dessa forma, todas as medidas de qualidade do ajuste tendem a ser ruins. Na maioria dos programas para análise da SEM é a técnica pré-selecionada;
(iii) Mínimos Quadrados Generalizados (GLS): onde se deve trabalhar com dados aderentes à curva gaussiana. Exige uma amostra grande entre 400 e 500 respondentes;
(iv) Estimação Assintoticamente Livre de Distribuição (ADF): na qual a não-normalidade dos dados na provoca qualquer interferência, mas exige um tamanho amostral maior, por volta de 20:1, ou seja, quinze respondentes para cada indicador do modelo.
Além da técnica de estimação, Hair Jr et al. (2005) afirmam que o pesquisador deve escolher um entre os processos de estimação: (1) Estimação direta, no qual o modelo é diretamente estimado com um procedimento selecionado, sendo que o erro amostral é que fundamenta o intervalo de confiança e o erros padrão de cada estimativa; (2) Bootstrapping, que faz uma reamostragem dos dados originais, calculando-se as estimativas de parâmetros e erros padrão com base nos dados da pesquisa; (3) Simulação, que também faz uma reamostragem, mas diferentemente do bootstrappingpode alterar determinadas características da amostra para atender aos objetivos da pesquisa e do pesquisador e (4) Jackknifing, que como nos dois processos anteriores também faz uma reamostragem, sendo que a diferença para os anteriores está em criar N novas amostras, sendo N o tamanho da amostra original, com o detalhe de que a cada nova amostra que é criada, uma observação é omitida.
No quinto estágio avaliação da identificação do modelo estrutural, a questão central é a de identificação do modelo. Segundo Hoyle (1995), a identificação diz respeito à correspondência entre a informação a ser estimada os parâmetros livres e a informação da qual será estimada a variâncias e covariâncias observadas (p.4). Ullman (2001) fornece um exemplo simples que explica a questão da identificação do modelo:
Um modelo é dito identificado quando há apenas uma solução numérica para cada parâmetro no modelo. Por exemplo, tenhamos a variância Y=10 e a variância Y=α+β .Quaisquer valores podem ser substituídos por α e β desde que somem 10. Não há uma solução única nem para a e nem para b; isto posto, há um infinito número de combinações entre os dois números que podem resultar em 10. Dessa forma, esta equação simples não está identificada. Entretanto, se fixássemos o valor de α como 0, então haveria uma única solução para β, 10, e a equação estaria identificada (p.691).
Para Schumacker e Lomax (2004), a identificação do modelo depende da designação dos parâmetros como livres, fixos e condicionados. Tendo o modelo especificado e as especificações dos parâmetros determinadas, os parâmetros são combinados para formar uma, e apenas uma ∑ (matriz de variância-covariância).
]]> Hair Jr et al. (2005) afirmam que para fins de identificação, o pesquisador deve preocupar-se com a diferença entre o tamanho relativo da matriz de covariância - ou de correlação - em relação ao número de coeficientes estimados. Esta diferença é chamada de graus de liberdade, que é calculada como:df = ½ [(p+q)(p+q+1)] t
onde: df= graus de liberdade; p= número de indicadores endógenos; q= número de indicadores exógenos e t= número de coeficientes estimados no modelo proposto
Hair Jr et al. (2005) ainda esclarecem que existem duas regras básicas para determinar a identificação do modelo: condição de ordem e de ordenação. A regra da condição de ordem impõe que os graus de liberdade do modelo devem ser maiores ou iguais a zero. A condição de ordenação pressupõe que se determine algebricamente se cada parâmetro está univocamente identificado. Para resolver esta complexa tarefa o pesquisador pode lançar mão da regra das três medidas - todo e qualquer construto com três ou mais indicadores será sempre identificado - e da regra dos modelos recursivos modelos recursivos com construtos identificados serão sempre identificados.
Tradicionalmente, existem três níveis de identificação dos modelos (Hair Jr et al., 2005, Schumacker & Lomax, 2004):
(i) Modelo subidentificado: modelo com quantidade negativa de graus de liberdade, o que significa que um ou mais parâmetros não podem se runicamente identificados porque não há informações suficientes para isso. Este modelo não está identificado e não poderá ser estimado até que o pesquisador fixe ou condicione alguns parâmetros;
]]> (ii) Modelo exatamente identificado: modelo com zero grau de liberdade. Todos os parâmetros estão unicamente determinados e há a quantidade de informações exatas para serem analisadas.(iii) Modelo superidentificado: modelo que dever ser perseguido pelo pesquisador. Ele tem um número de graus de liberdade maior que zero, ou seja, mais informações na matriz de dados que o número de parâmetros a serem estimados. Dessa forma há mais de uma maneira de ajustá-lo, buscando o maior número de graus de liberdade possível. Essa condição permite a generalização do modelo.
Hair Jr et al. (2005) propõem quatro ações corretivas para resolver problemas de identificação do modelo. As ações devem ser executadas na seguinte ordem: (1) construir um modelo com um número mínimo de coeficientes; (2) caso seja possível, fixar as variâncias de erros de mensuração; (3) fixar os coeficientes de estruturais conhecidos; e, (4) eliminar variáveis problemáticas. Se os problemas persistirem, os autores recomendam que o pesquisador volte ao primeiro estágio da SEM e lance mão de um novo modelo teórico.
O sexto e penúltimo passo, avaliação dos critérios de qualidade do ajuste, deve ser iniciado com a identificação de estimativas transgressoras. Os casos de estimativas transgressoras mais comuns são: (1) variáveis Heywood - variáveis com variância negativa; (2) coeficientes padronizados excedentes ou muito próximos a 1; e, (3) erros padrão elevados. Caso as encontre, o pesquisador deverá primeiramente resolve-las, com as mesmas estratégias para resolver os problemas de identificação, antes de analisar os demais resultados e do modelo (Hair Jr et al., 2005).
Após ter corrigido as estimativas transgressoras, o pesquisador deverá avaliar o ajuste geral do modelo. Para isso, ele deverá observar uma ou mais medidas de qualidade do ajuste, pois são elas que lhe permitirão avaliar se o seu modelo teórico pode ser confirmado frente aos dados observados. Existem três tipos de medidas de ajuste gerais do modelo: (1) medidas de ajuste absoluto, que indicam o ajuste geral do modelo; (2) medidas de ajuste incremental, que comparam o modelo proposto ao modelo nulo aquele que é ponto de referencia ou padrão de comparação e (3) medidas de ajuste parcimonioso, que compara o ajuste do modelo aos parâmetros estimados necessários para alcançar um nível específico de ajuste (Hair Jr et al., 2005, Schumacker & Lomax, 2004; Ullman, 2001) (ver tabela 2).
Tabela 2. Medidas de Ajuste Geral do Modelo *
|
| Medida | ]]> Valor aceitável |
| Medidas de ajuste absoluto | Qui-quadrado ( χ2) | Valores menores resultam em maiores níveis de significância: a matriz verdadeira não é estatisticamente diferente da prevista |
| Parâmetro de não centralidade (NCP) | Valores mais perto de zero são melhores. | |
| Índice de qualidade do ajuste (GFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito) | |
| Raiz do resíduo quadrático médio (RMSR) | ]]> Valores inferiores a 0,10 | |
| Raiz do erro quadrático médio de aproximação (RMSEA) | Valores inferiores a 0,08 | |
| Medidas de ajuste incremental | Índice ajustado de qualidade do ajuste (AGFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito), recomenda-se acima de 0,90 |
| Índice de Tuker-Lewis (TLI) ou Índice de ajuste não- ponderado (NNFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito), recomenda-se acima de 0,90 | |
| Medidas de ajuste ]]> parcimonioso | Índice de ajuste ponderado (NFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito), recomenda-se acima de 0,90 |
| Índice de ajuste comparativo (CFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito) | |
| Índice de ajuste incremental (IFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito) | |
| Índice de ajuste relativo (RFI) | Varia de zero (ajuste nulo) a 1 (ajuste perfeito) | |
| Critério de informação Akaike (AIC) | ]]> Varia de zero (ajuste perfeito) a um valor negativo (ajuste nulo) | |
| Qui-quadrado ponderado** | Valores inferiores a 1 indicam um ajuste pobre; valores acima de 5 indicam necessidade de ajuste. O valor aceitável deve ser igual ou menor a 5 |
]]>Nota: Adaptado de Hair Jr et al. (2005).
*Apresenta-se os valores sugeridos pelo sistema LISREL.
** Qui-quadrado ponderado: divide-se o valor do χ2pelo número de graus de liberdade (c2/df).
Convém salientar que há uma ampla discussão da área sobre os valores de cut-off dos testes, mas esta discussão está fora do escopo deste artigo. Entretanto, o domínio desse conhecimento é de extrema relevância e por isso, sugere-se alguns artigos sobre este tópico (Barret, 2007; Bentler, 2007; Dion, 2008; Hu & Bentler, 1999; Markland, 2007; Marsh, Hau, & Wen, 2004).
Após a análise destes ajustes globais, deve-se atentar aos ajustes específicos do modelo de mensuração e do modelo estrutural. Quanto ao modelo de mensuração, deve-se avaliar a unidimensionalidade e a confiabilidade.
A unidimensionalidade é a característica de um conjunto de indicadores que tem apenas um traço inerente ou conceito em comum(Hair Jr et al., 2005, p.470). Avaliar a unidimensionalidade consiste em verificar se os indicadores estabelecidos representam de fato um único construto. Uma medida aceitável da unidimensionalidade deverá revelar baixos resíduos padronizados. Se os resíduos estiverem altos, ao examiná-los o pesquisador deve procurar identificar padrões destes resíduos, que deverão ser maiores que 2 ou 2,58, dependendo do alpha escolhido. Se estes resíduos estiverem associados com um conjunto de indicadores usados para medir a mesma variável latente, então este conjunto de indicadores irá representar, provavelmente, seu próprio fator unidimensional. Por outro lado, grandes resíduos sem nenhum padrão aparente indicam um item ruim (Garver & Mentzer, 1999).
Hair Jr et al. (2005) afirmam que a unidimensionalidade é uma premissa para a confiabilidade do construto. A confiabilidade indica o grau em que um conjunto de indicadores de construtos latentes é consistente em suas mensurações (Hair Jr et al., 2005, p.467). Pode-se usar a seguinte fórmula para calcular a confiabilidade composta do construto:

onde: λj é a carga fatorial padronizada do indicador (assertiva) j e Ej é o erro de mensuração do indicador j, calculado como 1- confiabilidade do indicador
Valores aceitáveis são iguais ou superiores a 0,70 (Garver & Mentzer, 1999; Hair Jr et al., 2005).
]]> Uma medida complementar da confiabilidade é a medida da variância extraída. Ela reflete a quantidade total de variância dos indicadores explicada pela variável latente. A medida da variância extraída pode ser calculada pela seguinte fórmula: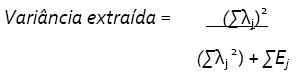
onde: λj é a carga fatorial padronizada do indicador (assertiva) j e Ej é o erro de mensuração do indicador j, calculado como 1- confiabilidade do indicador
A diferença entre a confiabilidade composta do construto e a medida da variância extraída é que nesta última as cargas padronizadas são elevadas ao quadrado antes de serem somadas. Bons valores para um construto devem ser iguais ou acima de 0,5 (50%) (Garver & Mentzer, 1999; Hair Jr et al., 2005).
Após o estabelecimento da unidimensionalidade, a validade de construto deverá ser investigada. A validade diz respeito ao aspecto da medida ser congruente com a propriedade medida dos objetos, e não com a exatidão com que a mensuração é feita (Pasquali, 2003, p.158). É a validade de construto que nos assegura que estamos medindo o construto que nos propusemos a medir. A validade convergente e a validade discriminante são os dois tipos de validade mais comummente usados para confirmar a validade de construto. Porém, a validade preditiva um subtipo da validade de critério também pode ser investigada (Dunn, Seaker & Waller, 1994; Garver & Mentzer, 1999).
A validade preditiva avalia se o construto de interesse prediz ou não construtos que seria esperado que ele predissesse. Pode ser testada no modelo de mensuração, se ele tiver um construto, que teoricamente, pudesse ser predito pelo construto de interesse. Esta avaliação se dá pela correlação com os outros construtos que o construto de interesse devesse predizer (Garver & Mentzer, 1999).
A validade convergente diz respeito à extensão com que a variável latente correlaciona-se com os itens escolhidos para medir aquela variável latente, ou seja, se os indicadores designados a formar a variável latente estatisticamente convergem. A avaliação da unidimensionalidade fornece informações para a verificação da validade convergente, na medida em que determina quais indicadores representam a variável latente. Uma das formas de avaliar a validade convergente é verificar o valor do quadrado da carga da variável latente que o conjunto de indicadores representa. Todas as cargas fatoriais deverão ser estatisticamente significantes, indicando que a validade convergente foi estabelecida (Bagozzi, Yi & Phillips, 1991; Dunn et al., 1994).
A análise da validade discriminante envolve a comparação das correlações entre os construtos do modelo e com um modelo teórico. Neste modelo teórico, todas as correlações entre os construtos está determinada como sendo de valor 1,00, o que permite realizar o teste da diferença do qui-quadrado. Para realizar este teste, calcula-se a diferença entre os valores do qui-quadrado e a diferença dos graus de liberdade para os dois modelos. Para determinar a significância estatística do teste da diferença do qui-quadadro, analise os valores da diferença do qui-quadrado e os valores dos graus de liberdade numa tabela de qui-quadrado: valores estatisticamente significantes indicam a existência de validade discriminante. O teste deverá ser realizados em cada par de construtos (Garver & Mentzer, 1999) Anderson e Gerbin (1988) e Garver e Mentzer (1999) chamam a atenção para um detalhe importante: à medida que o pesquisador realiza os testes de diferença do qui-quadrado para os pares de construto, o nível de significância de cada teste deverá ser ajustado para manter o nível total real de significância para a família de testes. Dessa forma, dever-se usar a fórmula:
]]> α0 = 1 (1 αi)Tonde: α0 é a significância do teste, sendo 0,05 o valor normalmente adotado; αi é o nível de significância que deverá ser adotado em cada análise da validade discriminante e T é o número de testes realizados
Anderson e Gerbin (1988) ainda consideram a utilização de um teste complementar para a análise da validade discriminante. Este teste consiste em determinar se o intervalo de confiança (± dois desvios-padrão) da correlação entre a estimativa de dois construtos inclui 1,00. Caso o intervalo de confiança não contenha 1,00, então os dois construtos poderão ser considerados diferentes, tendo validade discriminante
O sétimo e último passo, interpretação e modificação do modelo, envolve a interpretação dos resultados. O pesquisador deverá avaliar se os resultados obtidos para o modelo de mensuração proposto permitem dar significado aos construtos. Deverá também avaliar se é possível aceitar as relações entre os construtos endógenos e exógenos propostos no modelo estrutural, com base nas significâncias dos parâmetros deste modelo. O pesquisador, após interpretar o modelo, poderá procurar por métodos para melhorar seu ajuste, e ao fazer isso, ele iniciará a reespecificação do modelo. Para iniciar sua procura por melhoramentos no modelo, o pesquisador pode avaliar os resíduos da matriz de correlação ou de covariância prevista. Valores residuais acima de ±2,58 são considerados estatisticamente significantes, num intervalo de confiança de 95%. A existência de resíduos significantes indica erro na previsão para um par de indicadores, que poderão ser revistos na reespecificação do modelo. Os índices de modificação valores calculados para cada relação não estimada possível em um modelo são a segunda fonte para o pesquisador identificar fontes de melhoramento no modelo. Os índices de modificação correspondem à redução provocada pela estimação de um coeficiente, em qui-quadrado. Valores iguais ou acima de 3,84 sugerem uma redução estatisticamente significante no qui-quadrado, caso aquele determinado parâmetro seja estimado (Hair Jr et al, 2005).
Quando o modelo é reespecificado, o pesquisador deve retornar ao estágio 4 e reavaliá-lo. Hair Jr et al. (2005) advertem os pesquisadores a proceder com as modificações com cautela e que, um modelo modificado deverá passar por uma validação cruzada com dados diferentes daqueles usados para estimar o modelo anterior antes de ser aceite.
Limitações e críticas à SEM
As críticas que tem sido feitas à SEM se agregam em dois tópicos principais: qualidade/quantidade da amostra e interpretação causal (Hox & Becher, 1998).
]]> Para Thompson (2006), grandes amostras são inerentes à SEM. Essa afirmação pode ser melhor entendida ao nos atentarmos que as covariâncias e correlações são menos estáveis quando estimadas em amostras pequenas (Ullman, 2001). Thompson (2006) ilustra 4 casos onde pode se notar a sucessiva necessidade de grandes amostras: (1) modelos com um grande número de indicadores pedem amostras maiores; (2) amostras maiores ainda são necessárias quando o modelo com mais indicadores se torna mais complexo; (3) amostras maiores ainda são necessárias quando se adopta teorias elegantes de estimação de parâmetros; e, (4) a amostra ficará maior ainda se o pesquisador quiser conduzir alguma pesquisa de especificação do modelo.Deve-se considerar também a exigência da normalidade dos dados para usar a maioria das técnicas de estimação, inclusive a mais comum: o método de estimação de Máxima Verossimilhança. Caso a normalidade multivariada seja violada e o pesquisador queira usar estas técnicas de estimação, serão necessárias amostras muito grandes acima de 2500 respondentes para compensar a não-normalidade (Ullman, 2001). Esta necessidade de grandes amostras para corrigir a não normalidade pode afugentar pesquisadores com delineamentos amostrais menores, como o das pesquisas experimentais.
Quanto à interpretação causal, Mueller (1997) declara que a SEM apenas pode ser benéfica ao pesquisador se uma forte teoria está subjacente ao modelo inicialmente hipotetizado. Baseado em dados correlacionais, os métodos estatísticos não podem, por exemplo, estabelecer ou provar relações causais entre as variáveis (p.355).
Para Mueller (1997), os métodos estatísticos aplicados aos dados correlacionais podem auxiliar a identificar algumas evidências empíricas, que levarão a rejeitar ou aceitar teorias de hipóteses causais ou ainda, avaliar a força e a direção das causalidades hipotetizadas ou das relações estruturais em um dado modelo.
Outros autores criticam a causalidade da SEM. Para Thompson (2006) uma evidência causal apenas pode ser extrapolada quando os dados provêm de pesquisas experimentais. Num desing de pesquisa não-experimental, os resultados da análise de correlação dos dados têm uma ambiguidade intrínseca. Já para Cliff (1983), a única forma de demonstrar causalidade é o controlo das variáveis no tempo, quando é permitido avaliar a complexidade das relações entre as variáveis dependentes e independentes. No design transversal, as variáveis não podem ser isoladas, de forma que não é possível identificar a natureza das relações entre elas, podendo-se apenas estabelecer correlações entre as variáveis estudadas.
Entretanto os mesmos autores que fazem estas críticas não perdem de vista que a elaboração do modelo exige um conhecimento profundo da teoria do tema investigado, e que esta pode ser a chave para evitar relações causais equivocadas. Argumentando favoravelmente à causalidade implícita à SEM, Cliff (1983) frisa que os dados correlacionais podem ser sugestivos de relações causais. Para Thompson (2006) a escolha acertada das variáveis e a identificação correta das que são dependentes e independentes podem levar a SEM a ser mais forte nas questões de causalidade. O autor conclui seu argumento relembrando que mesmo frente a um bom ajuste, não existe um único modelo para aquelas variáveis estudadas, os modelos são concorrentes entre si: dessa forma há uma grande variedade de formas válidas de explicar determinadas relações de regressão entre os construtos.
Para Mueller (1997) não se pode perder de vista que estabelecer relações causais isoladas não é o único objetivo da SEM. Para que a interpretação dos dados da SEM ficasse clara, deveria ser abandonada a ideia de causa x efeito e adoptar a ideia de preditores x consequência. Essa postura vem de encontro à adoptada por Hair et al. (2005) que argumentam que a causalidade na SEM não é raramente encontrada da forma causa x efeito. Entretanto, na prática, forte apoio teórico pode tornar possível a estimação teórica de causalidade (p. 466).
Sob este novo paradigma, a SEM poderia mais ajudar do que atrapalhar no esclarecimento de relações causais, que podem estar escondidas em dados correlacionais.
Possibilidades e Perspectivas futuras
]]> Uma breve pesquisa na base de teses da CAPES, usando o termo modelagem de equações estruturais no tópico de busca assunto, resulta em 118 resultados, entre teses e dissertações. Destas, apenas uma foi feita numa faculdade de educação física, e se trata de uma escala de atitudes para verificar a sexualidade de idosos (Viana, 2009) e a outra, duma faculdade de administração abordou estratégias de telemarketing para fidelização de sócios de clubes esportivos (Faria, 2006). Na base Scielo, com o mesmo descritor, temos 9 resultados, e apenas o artigo de Fernandes e Vasconcelos-Raposo (2005) sobre o continuum de auto determinação na motivação intrínseca é relevante.Como se pode ver, a SEM é ainda uma técnica estatística pouco explorada em nossa área. O propósito é que este texto teórico instigue outros pesquisadores a diversificar sua abordagem na análise das atitudes humana, vistas à luz da Educação Física e Esportes. É preciso ter cuidado com novas abordagens, para uma interpretação correcta dos dados. Entretanto, acredita-se que a pesquisa brasileira, dada a diversidade inerente ao nosso país, pode oferecer muitas informações à ciência. Uma abordagem mais robusta às atitudes que determinam os comportamentos do homem em relação à atividade física e aos fatores pertinentes a ela traz benefícios não apenas para a compreensão da nossa realidade local, mas à complexidade desse comportamento em si.
Bibliografia
Anderson, J.C. & Gerbing, D.W. (1988) Structural equation modeling: A review and recommended two-step approach. Psychological Bulletin, 103, 411-423.
Bagozzi, R.P, Yi, Y., & Phillips, L.W. (1991) Assessing construct validity in organizational research. Administrative Science Quarterly, 36, 421-458.
Barret, P. (2007) Structural equation modelling: Adjudging model fit. Personality and Individual Differences, 42, 815-824.
Bentler, P.M. (2007). On tests and indices for evaluating structural models. Personality and Individual Differences, 42, 825-829.
Cantelmo, N.F. & Ferreira, D.F. (2007). Desempenho de testes de normalidade multivariados avaliado por simulação Monte Carlo. Ciência e Agrotecnologia, 31, 1630-1636. [ Links ]
Cliff, N. (1983) Some cautions concerning the application of casual modeling methods. Multivariate Behavioural Research, 18, 115-126.
]]> Dion, P.A. (2008) Interpreting structural equation modeling results: A reply to Martin and Cullen. Journal of Business Ethics, 83, 365-368.Dunn, S.C., Seaker, R.F., & Waller, M.A. (1994) Latent variables in business logistics research: scale development and validation. Journal of Business Logistics, 15, 145-172.
Faria, M.A. (2006) Estratégias de Marketing para Fidelização de Sócios em Clubes Sociais de Belo Horizonte. Dissertação de Mestrado, Faculdade de Estudos Administrativos de Minas Gerais, Belo Horizonte, Brasil.
Fernandes, H. & Vasconcelos-Raposo, J. (2005). Continuum de autodeterminação: validade para a sua aplicação no contexto desportivo. Estudos de Psicologia (Natal), 10, 385-395.
Fernandes, H., Vasconcelos-Raposo, J., Lázaro, J.P., & Dosil, J. (2004). Validación e aplicación de modelos teóricos motivacionales en el contexto de la educación física. Cuadernos de Psicología del Deporte, 4, 67-89.
Garver, M.S. & Mentzer J.T. (1999) Logistics research methods: Employing structural equation modelling to test for construct validity. Journal of Business Logistics, 20, 33-57.
Gefen, D., Straub, D.W., & Boudreau, M.C. (2000) Structural equation modeling and regression: Guidelines for research practice. Commun AIS, 4, 1-77.
Hair Jr, J.F., Anderson, R.E., Tatham, R.L., & Black, W.C. (2005). Análise multivariada de dados (5a. ed.). Porto Alegre: Bookman.
Hershberger, S.L., Marcoulides, G.A., & Parramore, M.M. (2003) Structural equation modeling: An introduction. In B.H. Pugesek, A. Tomer & A.V. Eye (Eds.), Structural equation modeling: Applications in ecological and evolutionary biology (pp. 3-41). Cambridge: Cambridge University Press.
Hox, J.J. & Bechger, T.M. (1998). An introduction to structural equation modeling. Family Science Review, 11, 354-373.
]]> Howell, D. (1999). Fundamental statistics for the behavioral sciences. Pacific Grove: Brooks/Cole Publishing CompanyHoyle, R.H. (1995). Structural equation modeling: Concepts, issues and applications. Thousand Oaks: Sage.
Hu, L.-T. & Bentler, P.M. (1999). Cut-off criteria for fit indices in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6, 1-55.
Klem, L. (2006). Structural equation modeling. In L.G. Grimm & P.R Yarnold (Eds.), Reading and understanding more multivariate statistics (pp. 227-260). Washington: American Psychological Association.
Kline, R.B. (1998). Principles and practices of structural equation modeling. Nova Iorque: Guilford Press.
Levin, J. (1987). Estatística aplicada às ciências humanas. São Paulo: Harbra.
Mardia, K.V. (1970). Measures of multivariate skewness and kurtosis with applications. Biometrika, 57, 519-530.
Markland, D. (2007). The golden rule is that there are no golden rules: A commentary on Paul Barretts recommendations for reporting model fit in structural equation modelling. Personality and Individual Differences, 42, 851-858.
Marsh, H.W., Hau, K.-T., & Wen, Z. (2004). In search of golden rules: Comment on hypothesis testing approaches to setting cut-off values for fit indexes and dangers in overgeneralizing Hu and Bentler's (1999) findings. Structural Equation Modeling, 11, 320-341.
Mueller, R.O. (1997). Structural equation modeling: Back to basics. Structural Equation Modeling, 4, 353-369.
]]> Pasquali, L. (2003) Psicometria: Teoria dos testes na psicologia e na educação. Petrópolis: Vozes.Rigdon, E. (2009). What is structural equation modeling. Consultado em 09 de Maio de 2009, a partir de http://www2.gsu.edu/~mkteer/sem.html
Schumacker, R.E. & Lomax, R.G. (2001). A begginers guide to structural equation modeling. New Jersey: Lawrence Erlbaum Associates.
Thompson, B. (2006). Ten commandments of structural equation modeling. In L.G. Grimm & P.R. Yarnold (Eds.), Reading and understanding more multivariate statistics (pp. 261-284). Washington: American Psychological Association.
Ullman, J.B. (2001). Structural equation modeling. In B.G. Tabachnick & L.S. Fidell (Eds.), Using multivariate statistics (pp. 653-771). Boston: Ally & Bacon.
Viana, H.B. (2008) Adaptação e validação da ASKAS: Aging Sexual Knowledge and Attitudes Scale em idosos brasileiros. Tese de Doutoramento, Universidade Estadual de Campinas, Campinas, Brasil.
Submetido: 29.10.2009 | Aceite: 22.12.2009
1Angela Nogueira Neves Betanho Campana. Mestre em Educação Física, Adaptação e Saúde FEF/UNICAMP. Doutoranda em Educação Física, Adaptação e Saúde FEF/UNICAMP. Bolsista CNPq.
]]> 2Maria da Consolação Gomes Cunha Fernandes Tavares. Mestre e Doutora em Medicina Interna FCM/UNICAMP. Livre Docente em Imagem Corporal FEF/UNICAMP. Docente do Departamento de Estudos de Atividade Física Adaptada FEF/UNICAMP.3Dirceu da Silva. Mestre em Física e Doutor em Educação pela USP. Docente do programa de pós graduação da Faculdade de Educação FE/UNICAMP.
Endereço para correspondência: Angela Campana, Rua Dr. João Arruda, 107, Apto. 6, Jardim Chapadão CEP: 13070-050 Campinas, São Paulo, Brasil. E-mail: angelanneves@yahoo.com.br
]]>