











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1. Introducción
La gestión del tráfico vehicular se ha convertido en un gran desafío en ciudades del mundo con expansión demográfica, pues a mayor crecimiento poblacional, mayor demanda de transporte. Saus (2023) menciona que los patrones de expansión de las ciudades tienen un impacto en la efectividad del transporte público. En ese sentido, los gobiernos locales suelen descuidar la planificación del transporte, en medio de una creciente cantidad de vehículos (Ministerio de Seguridad Pública de China, 2023) y la inadecuada gestión del tráfico. Las emisiones de dióxido de carbono (CO2) del parque automotor son una situación preocupante, sabiendo que el 90% de las emisiones de CO2 están contribuyendo al cambio climático (Nikas et al., 2022). En cuanto al control de las emisiones de CO2, en países de Latinoamérica como Colombia, Ecuador y Perú, las sugerencias de organismos internacionales de reemplazar vehículos que utilizan combustibles fósiles por vehículos eléctricos no se pueden implementar fácilmente (OCDE, 2011).
Respecto a la gestión del tráfico, los planes de gestión siguen perdiendo eficacia. Camargo (2018) menciona que el modelo "pico y placa" implementado en la ciudad de Bogotá, Colombia, en el año 2002, no ha mejorado el problema de la congestión vehicular. En el año 2002, había 500,000 automóviles registrados; para el año 2011, este número aumentó a 1,400,000 automóviles particulares. Caso similar sucedió en la ciudad de Lima, Perú; en el año 2019 se implementó el modelo "pico y placa", únicamente en ciertas vías principales de alta congestión. Como resultado, las vías alternas y alimentadoras resultaron sumamente congestionadas. A la fecha, en Perú, el modelo es inviable y se ha dejado de usar; en Colombia, el modelo continúa en uso, ya que “pico y placa” les es necesario debido a obras de infraestructura programadas para el 2024 y que afectarán el tráfico en la capital colombiana.
La principal motivación del trabajo propuesto es la necesidad de contribuir con la optimización del tráfico vehicular mediante una gestión inteligente de semáforos. Manrique (2018) identifica que una de las causas principales del tráfico vehicular está relacionado con la gestión de semáforos pues presentan problemas específicos como: luces dañadas, visibilidad reducida para los vehículos y tiempos fijos asignados a los colores de semáforo. Un tiempo de fase inadecuado permite la ocurrencia de accidentes y tiempos de espera perdidos. En consecuencia, el tiempo del ciclo del semáforo representa una variable importante a considerar con el fin de mejorar la productividad y seguridad en las intersecciones viales (Araya-Porras et al., 2022).
En el Perú se ha observado que los semáforos con configuraciones de tiempos de fase fijos o predefinidos son los que más se han instalado. Los tiempos de luz verde son inadecuados. Tramos de la vía que están vacíos tienen luz verde; mientras tanto, hay carriles con vehículos esperando en rojo en la vía transversal. Al respecto, diversos estudios han abordado el tema de la asignación de tiempos de ciclo del semáforo, usando algoritmos que respondan a la realidad del entorno. Para ello, han recurrido a la Inteligencia Artificial (IA), para desarrollar teorías, algoritmos, métodos, tecnologías y sistemas de aplicación (Huawei Technologies Co., Ltd., 2023). Las técnicas más usadas son las de optimización, las de gestión de sensores y técnicas de aprendizaje automático (Tomar et al., 2022).
Este trabajo tiene como objetivo proponer un sistema inteligente de gestión de semáforos en tiempo real. Las principales contribuciones de este trabajo son la validación de los métodos de conteo vehicular basados en YOLOv4 en cuanto a niveles de precisión, la precisión de medición de velocidad vehicular basada en el Método de Detección de Intrusiones (IDM) y el aporte significativo del algoritmo heurístico, que en su conjunto forman el sistema inteligente, reduciendo el tiempo de espera de los vehículos en contraste con la configuración predefinida de los semáforos tradicionales. Los resultados encontrados servirán a otros investigadores para: 1) diseñar sistemas escalables y sincronizados para varias intersecciones viales bajo el enfoque de tiempo real y 2) crear componentes de software embebidos con el algoritmo heurístico para ser utilizados con transformadores o redes LSTM.
El presente artículo está estructurado en las siguientes partes: inicia con una revisión bibliográfica del tema, seguido por la descripción de los materiales y métodos aplicados. Luego, se describe la sección de resultados y discusión, donde se analizan los resultados obtenidos de la aplicación de algoritmos en términos de precisión. Finalmente, la sección de conclusiones y trabajos futuros.
2. Revisión bibliográfica
De los trabajos más recientes relacionados con el tráfico vehicular, un grupo está enfocado en la detección de carreteras, otro en la detección y seguimiento de vehículos, y otro grupo en los sistemas de transporte inteligente (ITS). Wang et al. (2019) sugieren que es posible monitorear secciones de carreteras para predecir el tráfico con técnicas como el modelado de datos y un modelo de predicción. Usaron una secuencia de matrices para entrenar un modelo profundo que combina una red neuronal convolucional (CNN) de aplicación específica para clasificación y segmentación de imágenes, según Jiménez-Murillo et al. (2023), y una red neuronal recurrente (RNN). Fundamentalmente, entrenaron un modelo profundo para predecir el flujo de tráfico y controlar las luces de tráfico con el fin de reducir la congestión.
Se han empleado técnicas de sustracción de fondo junto con métodos de análisis de contraste en distintas regiones de interés (ROI). Las métricas fueron: el número de vehículos en espera cuando un semáforo cambia de rojo a verde y la cantidad de vehículos que atraviesan la intersección, justo antes de que el semáforo pase de verde a rojo. El método se denomina Procesamiento de Textura de un conjunto de regiones de interés (Inglés-Romero et al., 2018).
Ashifuddin et al. (2019) desarrollaron un ITS con un enfoque de Internet de las cosas (IoT) para administrar la congestión del tráfico. Se utilizaron sensores estacionarios en la carretera para estimar y categorizar el nivel de congestión del tráfico en distintos tramos viales dentro de una ciudad, así como para analizar los datos de tráfico capturados como velocidad y densidad. Emplearon una red neuronal artificial (ANN) como base del sistema para clasificar los siguientes niveles de congestión: flujo libre, congestión media y congestión alta.
Actulamente, un sistema inteligente administrador de tráfico está conformado de componentes como: a) Adquisición de imágenes que, a través de sensores de cámara, captura datos de la realidad, b) Extracción de características en función del reconocimiento, detección y seguimiento de vehículos y c) Aplicaciones de software de tráfico que suelen utilizar sistemas de posicionamiento global, sensores de tráfico y datos de tráfico en tiempo real. Tendencias actuales de ITS están basadas en metaheurísticas, lógica difusa, redes neuronales convolucionales, aprendizaje por refuerzo y una combinación de modelos y sistemas llamados híbridos (Nigam et al., 2023).
Para la adquisición de imágenes en tiempo real, el algoritmo que ha respondido de manera muy eficiente en procesos de detección es You Only Look Once (YOLO). A la fecha, es el estado de arte para la detección de objetos (Gonçalves et al., 2023). Los algoritmos previos a YOLO para la detección de objetos utilizan R-CNN o Fast R-CNN, procedimientos que son robustos y precisos, pero son procesos complejos, lentos y poco optimizables debido a que cada componente debe entrenarse por separado (Redmon et al., 2016). YOLO solo usa regresión con la red neuronal, debido a ello su rapidez. Zuraimi & Zaman (2021) evaluaron YOLOv4 en comparación con su versión previa en un sistema de detección de vehículos; según los resultados, se alcanzó una precisión del 82,08% en tiempo real de aproximadamente 14 fps en una tarjeta gráfica GTX 1660ti.
Respecto a la medición de la velocidad de objetos basada en video, se han encontrado estudios que utilizan métodos de sustracción del objeto en movimiento. Al objeto se considera como una mancha dentro de una elipse delimitadora, la cual se va ubicando en cuadros consecutivos a través de intervalos de tiempo (Cheung & Kamath, 2005). La técnica se ha mejorado con la técnica de estimación del fondo y seguimiento del movimiento mediante la segmentación del primer plano (Jeyabharathi & Dejey, 2016).
Javadi et al. (2019) proponen el Método de Detección de Intrusiones (IDM), que es un método empleado para identificar cuando un objeto atraviesa una línea virtual y entra en una zona de interés entre puntos discretos. El intervalo entre los puntos discretos detectados corresponde al tiempo de muestreo de la cámara. Por consiguiente, la intrusión es detectada en una variación de distancia de detección Δ(m). Esta distancia de detección está directamente relacionada con el tiempo de muestreo de la cámara t(s) y la velocidad hipotética del vehículo expresada como v (m/s).
3.Materiales y métodos
La Figura 1 muestra la arquitectura del Sistema de Gestión de Semáforos (SGS) para intersecciones viales con giro a la izquierda. Las cámaras capturan el tráfico en la intersección. El componente de detección y seguimiento clasifica y cuenta los vehículos con el algoritmo YOLO y determina su velocidad usando un método de detección de intrusiones. Estos datos alimentan el algoritmo heurístico de asignación de tiempos de fase. Además, los datos se almacenan en un servidor Kafka para aplicaciones cliente en tiempo real.
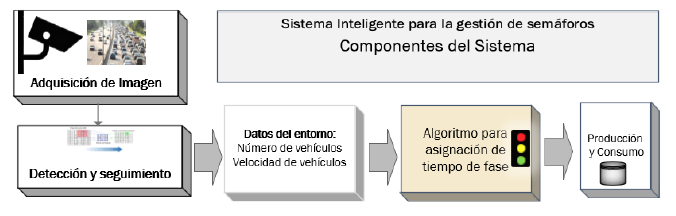
3.1. Adquisición de imágenes
Respecto al proceso de adquisición de imágenes, es importante mencionar que en cumplimiento a la ley de protección de los datos en el Perú, el uso de las imágenes capturadas ha sido y será usado estrictamente en el contexto de la presente investigación. El detector de objetos no detecta la placa de vehículo; clasifica a una persona, pero no usa reconocimiento facial. Por tanto, la privacidad de los transeúntes, los vehículos y las edificaciones está garantizada. Esta fase se realizó en una intersección de alta congestión vehicular durante la hora pico (7 a.m. hasta las 8 a.m.), en período escolar y con giro a la izquierda permitido (Av. Pacífico - Av. Country en Nuevo Chimbote, Perú). Se ensambló un equipo tal como se ilustra en la Figura 2. Se utilizó un trípode de 6 m de largo, las cámaras de dispositivos móviles con resolución de 2 megapíxeles con aspecto 4:3 y un ángulo de inclinación θ del equipo 4 entre 30 y 60 grados, calibrados de acuerdo a la distancia del tramo y el pase peatonal. Se instaló el software Open Camera y TeamViewer en los equipos 4 y 5, para controlar y monitorear con el equipo 5 al equipo 4.
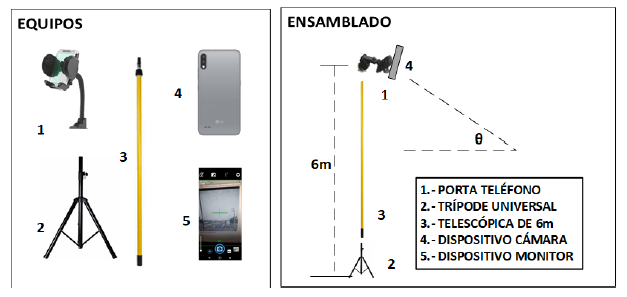
De otra parte, antes de medir las velocidades de vehículos, se midió la longitud de las líneas discontinuas del tramo vehicular, seguido por la medición del espaciado de segmentos que es la distancia entre estas líneas, expresada en metros, ver Figura 3.

Se grabaron videos e imágenes para la comparación respectiva de los datos de la recolección manual con los datos que arrojen los métodos YOLO e IDM. Para los cálculos se consideró las medidas de línea longitudinal discontinua y espaciado de segmentos que son respectivamente de 3 m y 5 m para zonas urbanas de velocidad ≤ 60 km/h y de 4.5 m y 7.5 m para zonas de mayor velocidad (Ministerio de Transportes y Comunicaciones del Perú, 2018, p. 388).
3.2. Detección y seguimiento
Se utilizó un modelo preentrenado Yolov4 aplicado a una base de datos de 120 imágenes de intersección vehicular capturadas en la intersección descrita en la sección 3.1. No fue necesario proceder al etiquetado de imágenes con LabelImg porque, más que clasificación, el enfoque estuvo en detección. Se modificó el archivo yolov4.cfg, para solamente permitir detectar vehículos como camiones, bicicletas, automóviles, buses, motocicletas, entre otros, a fin de discriminar el conteo exclusivo de vehículos. Luego, para la parte experimental de conteo de las 120 imágenes de los tramos de la intersección vial, de manera aleatoria, con un intervalo de confianza de 95%, se consideró una muestra de 96 imágenes. En la Figura 4, se pueden observar tres escenarios de detección mediante algoritmo. En cuanto al proceso de seguimiento, se consideró de manera aleatoria simple 16 vehículos, durante un período de tiempo. Para llevar a cabo la medición manual de la velocidad, según el método IDM, se calculó el tiempo que un vehículo toma en recorrer una cierta distancia Δ(m), en este caso la distancia d = 7.5 m +2 m de tolerancia. Con un cronómetro digital se registró el momento en que el vehículo inició la intrusión de la distancia d hasta finalizar el recorrido d. El tiempo t en segundos obtenido de manera manual se emplea para determinar la velocidad en km/h mediante la siguiente fórmula: velocidad v = (9.5 m/t) x (3600 s/h) x (km/1000 m).

3.3. Respecto al flujo de tráfico
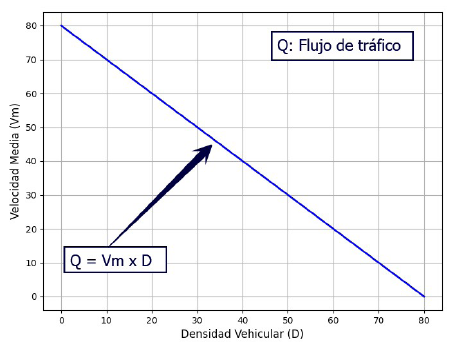
El flujo de tráfico está determinado por la ecuación Q=Vm x D, donde Q es el flujo de tráfico,Vm es la velocidad media y D es la densidad vehicular. Esto significa que Q varía en función de los valores de Vm y D. En la Figura 5 se puede observar que si la densidad vehicular disminuye, la velocidad media crece y si la densidad vehicular aumenta, la velocidad media disminuye. Esto tiene su implicancia en la determinación empírica del tipo de congestión basada en la densidad.
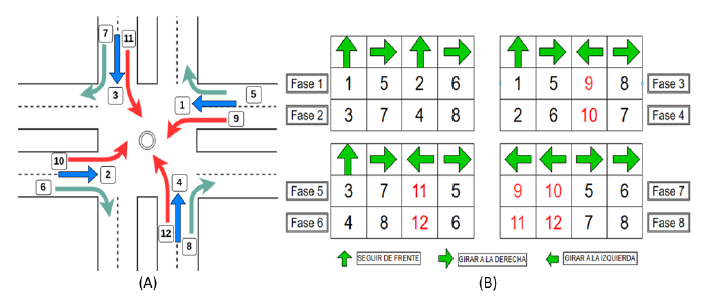
En la Figura 6(A) se observa que, cuando entra en fase el par de flujos (1, 2), estos no presentarán conflictos entre sí. De manera similar sucede con el par de flujos (3, 4). El par de flujos (5, 6) y (7, 8) giran a la derecha tampoco presentan conflictos entre sí. Los flujos conflictivos son los flujos que giran a la izquierda como los pares de flujo (9, 2), (10, 1), (11, 4) y (12, 3). En la Figura 6(B) se observan 8 fases menos conflictivas conformadas por 4 flujos y se evidencia que cada vez que aparece un giro a la izquierda, la fase siempre presenta un flujo conflictivo que no afecta a los demás. Por ejemplo, en la fase 6 los flujos 4, 8 y 6 no entran en conflicto y el flujo conflictivo 12 tampoco los afecta. Por tanto, en un escenario en el que el tráfico entra en bloqueo mutuo, una de estas 8 posibilidades de fase podrá ayudar a descongestionar el tráfico.
3.4. Algoritmo para flujos no conflictivos (FNC)
La Tabla 1 muestra 3 tipos de modos: MODO 1 para condiciones de congestión de rutina, MODO 2 para congestión extrema y velocidad promedio cerca de cero (Prohibición de Giro a la Izquierda) y MODO 3, solo si resulta imposible que los flujos de tráfico lineales crucen la intersección de frente.
Tabla 1 Pares de flujos no conflictivos en una intersección vial
| PAR | Par1 | Par2 | Par3 | Par4 | Par5 | Par6 | Par7 | Par8 |
|---|---|---|---|---|---|---|---|---|
| Flujos | (9,10) | (9,1) | (2,10) | (2,1) | (12,11) | (12,4) | (3,11) | (3,4) |
| MODO | 3 | 1 | 1 | 2 | 3 | 1 | 1 | 2 |
| PAR | NO | Par3 | Par2 | NO | NO | Par7 | Par6 | NO |

3.5. Algoritmo de inicio y configuración
En este algoritmo establece los datos de entrada específicos de cada tramo vehicular; como son el largo, ancho, número de carriles, espaciamiento entre vehículos y realiza los cálculos descritos en los ítems 4, 5, 6, 7 y 8 del algoritmo 2.

Este algoritmo calcula la Densidad de Grupo (dg) dividiendo el número de vehículos por el área del tramo. Luego, determina el Índice de Congestión de Tráfico (ICT), que es dg dividido por la densidad máxima del tramo, resultando en un valor en el rango de [0, 1]. Un ICT cercano a 0 indica baja congestión, mientras que cerca de 1 indica alta congestión.

3.7. Algoritmo de operaciones con la velocidad vehicular
Este algoritmo obtiene la suma de las velocidades de los automóviles en aplicación del método de seguimiento IDM. Por otra parte, si el número de vehículos del tramo es cero, entonces la velocidad media será cero; sino, la velocidad media del grupo será la suma de las velocidades del grupo dividido entre el número de vehículos del tramo. Luego, con la velocidad media del grupo (vmg) calculada, se tipifica el tipo de velocidad que puede ser baja, moderada, alta y muy alta.

3.8. Algoritmo para establecer el tipo de congestión
Este algoritmo se encarga de verificar en qué rango se encuentra el ICT del tramo actual y así establecer el tiempo de fase al tipo de congestión. El tiempo de fase T fase se determina con la ecuación T fase = L/vmg, donde L es la longitud del tramo y vmg es la velocidad media del grupo. Lo cual indica que a menor velocidad media, mayor tiempo de fase y a mayor velocidad media, menor tiempo de fase. Considerando L=100 m y Vmg=Vmin=7.2 km/h, según observación empírica, se ha obtenido la representación matemática que se muestra en la Ecuación 1, donde f(x) es el tiempo asignado para cada tipo de congestión dado el factor x y el Índice de Congestión de Tráfico (ICT). Observar que, a medida que ICT crece, la función f(x) incrementa su valor. Tmax es obtenido del algoritmo 2.
Se usó la estructura TC[Tipo-Congestión, descripción, Tfase].

3.9. Algoritmo de gestión del semáforo
El algoritmo del semáforo constantemente está recibiendo información del entorno para ajustar la programación óptima de la fase del semáforo en el tramo actual. Siempre tiene en memoria la Fase Actual, el MODO, el ICT respectivo, el tipo de congestión tc, la velocidad media del grupo vmg y el tipo de velocidad media tvm. Además, monitoriza los tramos para determinar cuál tiene mayor ICT para asignar el tiempo de fase. Luego, dependiendo de la densidad y la velocidad media, realiza el reajuste automáticamente aumentando o disminuyendo el tiempo de la fase en segundos adicionales, según sea el caso. A continuación, inicia el conteo regresivo considerando los tiempos asignados y finalmente, efectúa el cambio de fase.

3.10. Despliegue, producción y consumo
El sistema inteligente propuesto se basa en el modelo productor consumidor, ver Figura 7. El servidor central que ejecuta Linux Ubuntu 22.04 LTS, con memoria RAM de 8 GB, procesador Intel Core I7 1.9 GHz, GPU NVIDIA GeForce MX130, está formado por dos nodos principales. Un nodo que se encarga de la lógica de la Gestión del Semáforo y otro nodo Nodejs que se encarga de atender las peticiones web.
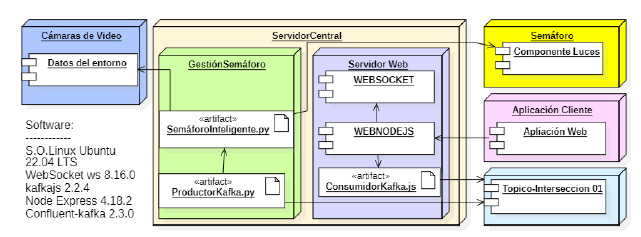
El artefacto SemáforoInteligente.py en Python 3.8 usa Yolo4 y OpenCV 4.8 para procesar datos del entorno, ejecutar un algoritmo heurístico, y enviar resultados al nodo semáforo. Este nodo muestra los tiempos de fase asignados y cuentas regresivas. ProductorKafka.py conecta y envía datos json a un servidor Kafka en la nube ConfluentKafka, incluyendo fecha, hora, tipo de tráfico, vehículos por tramo y tiempo de espera. El Servidor Kafka almacena datos en tiempo real en un tópico Intersección01 y maneja peticiones del programa ConsumidorKafka.js para la Aplicación Cliente.
4. Resultados
En esta sección se presentan los resultados de la validación del modelo de sistema inteligente propuesto, incluyendo el conteo de vehículos, la medición de velocidad y los resultados del algoritmo heurístico. Para evaluar la precisión del contador de vehículos basado en detección de objetos frente al conteo manual, se usó la fórmula precisión = (algoritmo/observador), donde algoritmo es el número de vehículos detectados y observador es el número de vehículos del conteo manual. Se realizaron 96 conteos, obteniendo una precisión media de 0.9127, una mediana de 1 y una varianza de 0.016, con un nivel de confianza del 95%. Según la prueba de normalidad de Kolmogorv a 96 grados de libertad (gl), se obtuvo un p-valor < 0.05. Por consiguiente, al aplicar la prueba no paramétrica de Wilcoxon para una muestra, se obtiene una significancia de 0.083, o sea p-valor ≥ 0.05. Por tanto, se acepta que la mediana de precisión es de 0.95.
Respecto a la velocidad de los vehículos basada en el seguimiento de objetos mediante algoritmo, en contraste con la medición manual, se evaluó la variable diferencia expresada como diferencia = |algoritmo - observador|, donde algoritmo es la velocidad obtenida mediante algoritmo y observador es la medida manual de la velocidad. Para 16 conteos se obtuvieron los siguientes estadísticos descriptivos a un 95% de nivel de confianza: una diferencia media de 1.3633, una mediana de 1.35 y una varianza de 0.895. Según la prueba de normalidad de Shapiro-Wilk a 16 grados de libertad, se obtuvo una significancia de 0.521, o sea un p-valor ≥ 0.05. Lo que implica que, en su conjunto, los datos de la variable algoritmo y observador respecto a velocidad de vehículos siguen una distribución normal. Además, se evaluó la variable precisión = algoritmo/observador donde la prueba normalidad de Shapiro-Wilk indica una significancia de 0.540, es decir, p-valor ≥ 0.05, y se acepta también que los datos de la variable precisión del algoritmo en determinar la velocidad de los vehículos siguen una distribución normal.
La prueba T de una muestra nos permitió comparar la media de la variable precisión con el valor de prueba esperado igual o superior a 0,95. Según los resultados que se observan en la Tabla 2, para los valores de prueba de 0.95, 0.98 y 0.99, el valor de prueba no se acepta debido a que el p-valor es menor a 0.05. Solo los valores de prueba de 0.96 y 0.97 se aceptan debido al p-valor ≥ 0.05.
Por lo tanto, hay evidencia de que la variable precisión para la medición de velocidad de vehículos tiene una media aceptable en el rango de precisión entre el 96% y el 97%.
Tabla 2 Prueba T para una muestra, a un 95% de intervalo de confianza
| Variable | Prueba | t | gl | Sig. Bil. | Dif.medias | Inferior | Superior |
|---|---|---|---|---|---|---|---|
| PRECISIÓN | 0,95 | 2.238 | 15 | 0.041 | 0.01307 | 0.0006 | 0.0255 |
| PRECISIÓN | 0,96 | 0.526 | 15 | 0.607 | 0.00307 | -0.0094 | 0.0155 |
| PRECISIÓN | 0,97 | -1.187 | 15 | 0.254 | -0.00693 | -0.0194 | 0.0055 |
| PRECISIÓN | 0,98 | -2.899 | 15 | 0.011 | -0.01693 | -0.0294 | -0.0045 |
| PRECISIÓN | 0,99 | -4.611 | 15 | 0.000 | -0.02693 | -0.0394 | -0.0145 |
Para la evaluación de los resultados del algoritmo de semáforo inteligente, se consideró 15000 escenarios simulados por el algoritmo (observar extracto de datos en la Tabla 3). Debido a que la variable de estudio tiempo_espera_por_ciclo es la suma del Tiempo de Espera (TE) de un tramo con el TE de su transversal. La ecuación TEC k = TE 2k-1 + TE 2k , donde k=1,2…, n/2 expresa que se tomaron cada par de datos de tiempos de espera y se obtuvieron 7500 ciclos de semáforo.
Según la prueba de normalidad de Kolmogórov-Smirnov, el estadístico descriptivo presentó una media de 76.0661 s y una mediana de 76 s, con 7500 grados de libertad. Además, se obtuvo un p-valor < 0.05. Con la prueba no paramétrica de Wilcoxon para una muestra, la mediana obtenida para la variable tiempo_espera_por_ciclo fue de 76 s con una significancia de 0.103, es decir, un p-valor ≥ 0.05, lo cual nos permite retener la hipótesis de que la mediana es igual a 76 s a un nivel de confianza de 95%.
Tabla 3 Extracto de la vista de datos de tráfico generado por simulación
| id | Fase | Tramo | V_NS | V_SN | V_EO | V_OE | TipoVel | Congestión | T.Espera |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | Norte-Sur | 23 | 47 | 14 | 19 | Alta | Medio | 38 |
| 2 | 2 | Oeste-Este | 28 | 48 | 50 | 29 | Moderada | muy Alto | 58 |
| 3 | 1 | Sur-Norte | 43 | 25 | 26 | 27 | Alta | Medio | 38 |
| … | … | … | … | … | … | … | … | … | … |
| 14997 | 1 | Sur-Norte | 11 | 36 | 14 | 17 | Alta | Bajo | 28 |
| 14998 | 2 | Oeste-Este | 26 | 40 | 43 | 38 | Moderada | muy Alto | 58 |
| 14999 | 1 | Sur-Norte | 45 | 40 | 26 | 49 | Baja | Medio | 38 |
| 15000 | 2 | Oeste-Este | 15 | 23 | 12 | 40 | Baja | Medio | 63 |
Nota. V_NS, V_SN, V_EO, V_OE es el número de vehículos en cada tramo de norte-sur, sur-norte, este-oeste y oeste-este respectivamente, que a cierta tipo de velocidad Tipovel produce un tipo de congestión.
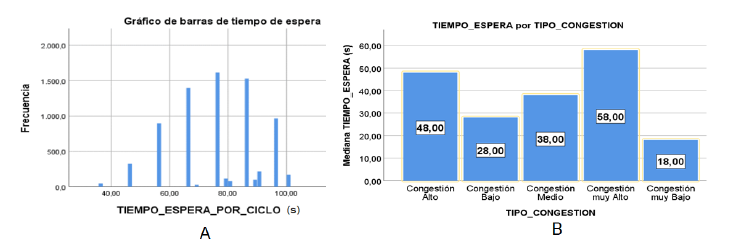
En la Figura 8A se puede observar el gráfico de frecuencia, donde la mayor frecuencia de los tiempos de espera por ciclo se encuentran cercanos a 80 s y el valor de la media es igual a 76.0661 s. En contraste con el escenario real, donde el ciclo semáforico fijo es de 92 s, se hace notar la diferencia de 14 s. Por tanto, 76 s por cada ciclo semáforico significa 47.36 ciclos/h; mejora que se hace notar frente al número de ciclos semáforicos fijo igual a 39.13 ciclos/h.
5. Discusión
Haber obtenido una precisión de 95% en cuanto al conteo de vehículos tiene una implicancia significativa en cuanto a confiabilidad del algoritmo de Yolov4, pues esto garantiza su funcionamiento e implementación en sistemas de producción. Sin embargo, los desafíos continúan respecto al problema del solapamiento u oclusión de vehículos, que son precisamente el causal del diferencial entre el conteo real y un conteo mediante algoritmo. En la Figura 9 se observa un caso de oclusión donde el bus detectado oclusiona a otros vehículos que se encuentran detrás.

Los resultados del conteo de vehículos muestran que la precisión de un modelo de inteligencia artificial puede mejorarse, especialmente al abordar problemas de oclusión. La medición de velocidad alcanza una precisión entre 96% y 97% usando algoritmos de visión computacional, demostrando su viabilidad para aplicaciones en tiempo real. El presente trabajo destaca la importancia del tiempo real en el conteo y seguimiento de vehículos. Aunque YOLOv4 y el algoritmo IDM son precisos, mejorar la precisión podría aumentar la latencia y esfuerzo computacional.
El algoritmo 5 en este estudio añade dos tipificaciones de congestión: muy baja y muy alta, mejorando la segmentación del ICT en el rango (0;1). A diferencia de Ashifuddin et al. (2019), que consideran tres tipos de congestión (libre, media y alta), nuestra propuesta especifica cinco. Como muestra la Figura 8B, las congestiones muy alta y muy baja afectan significativamente el tiempo de espera por tramo vehicular y ciclo semafórico. Por otro lado, el algoritmo de gestión del semáforo ha reducido el tiempo de espera promedio por ciclo a 76 s, mejorando respecto al ciclo fijo de 93 s, usando un modelo heurístico basado en la velocidad y el número de vehículos. Aunque el FNC en Modo 2 o 3 no garantiza resultados alentadores, nuestro modelo supera al modelo de control difuso de Wang et al. (2022), quienes lograron una reducción del 14.59%, y el nuestro logró disminuir el tiempo de espera en un 18.3%.
En cuanto a la validez interna, la metodología utilizada para el conteo de vehículos y la medición de velocidad está claramente definida, asegurando que los datos recopilados son precisos y comparables bajo condiciones controladas. Respecto a la validez externa, la presentación de resultados cuantitativos y estadísticos descriptivos a un nivel de confianza del 95% y la reducción de tiempo de espera en un 18.3% nos permiten generalizar los resultados del algoritmo heurístico a una población más amplia y a otros tipos de escenarios. Sin embargo, también hay limitaciones potenciales, como considerar la precisión del método de detección de objetos en diferentes condiciones ambientales, festividades, accidentes y variables más difíciles de medir y controlar, como el comportamiento imprudente del peatón y/o del conductor en una intersección vial, que serían motivo de otro estudio.
Para una futura aplicación en zonas de alta densidad vehicular como Lima, Perú, se sugiere adoptar nuestro modelo propuesto, enfocándose en mejorar con algoritmos de sincronización entre intersecciones viales.
6. Conclusiones y trabajos futuros
Este trabajo propone un sistema inteligente heurístico para gestionar semáforos en intersecciones viales. Basado en el flujo vehicular, toma decisiones en tiempo real, optimizando el ciclo semafórico a 76 s y reduciendo el tiempo de espera en un 18.3% respecto a los ciclos fijos. Se validó una precisión del 95% con el algoritmo de conteo Yolo y del 96%-97% con el método IDM para medir velocidad, superando el 95% esperado. Futuras investigaciones podrían adaptar el algoritmo a redes LSTM o transformadores para mejorar el proceso del sistema heurístico actual.

